Yokochi Masashi, Kobayashi Naohiro, Ulrich Eldon L, Kinjo Akira R, Iwata Takeshi, Ioannidis Yannis E, Livny Miron, Markley John L, Nakamura Haruki, Kojima Chojiro, Fujiwara Toshimichi
Institute for Protein Research, Osaka University, 3-2 Yamadaoka, Suita, Osaka, 565-0871, Japan.
Department of Biochemistry, University of Wisconsin-Madison, Madison, WI, 53706, USA.
J Biomed Semantics. 2016 May 5;7(1):16. doi: 10.1186/s13326-016-0057-1.
The nuclear magnetic resonance (NMR) spectroscopic data for biological macromolecules archived at the BioMagResBank (BMRB) provide a rich resource of biophysical information at atomic resolution. The NMR data archived in NMR-STAR ASCII format have been implemented in a relational database. However, it is still fairly difficult for users to retrieve data from the NMR-STAR files or the relational database in association with data from other biological databases.
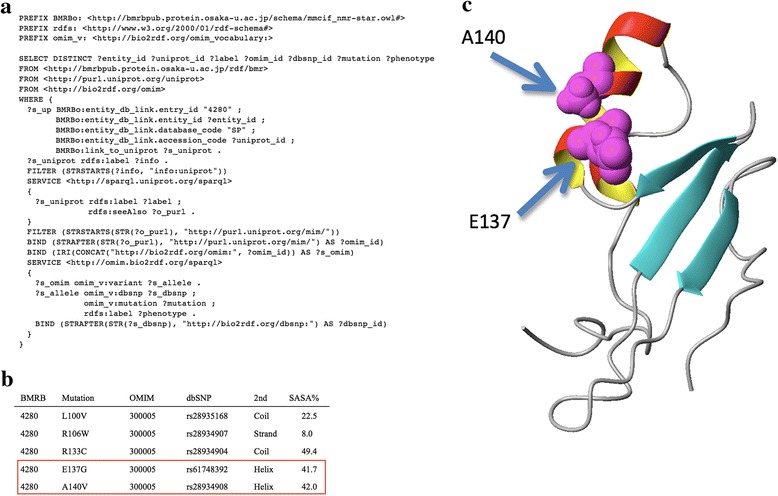
To enhance the interoperability of the BMRB database, we present a full conversion of BMRB entries to two standard structured data formats, XML and RDF, as common open representations of the NMR-STAR data. Moreover, a SPARQL endpoint has been deployed. The described case study demonstrates that a simple query of the SPARQL endpoints of the BMRB, UniProt, and Online Mendelian Inheritance in Man (OMIM), can be used in NMR and structure-based analysis of proteins combined with information of single nucleotide polymorphisms (SNPs) and their phenotypes.
We have developed BMRB/XML and BMRB/RDF and demonstrate their use in performing a federated SPARQL query linking the BMRB to other databases through standard semantic web technologies. This will facilitate data exchange across diverse information resources.
保存在生物磁共振数据库(BMRB)中的生物大分子的核磁共振(NMR)光谱数据提供了丰富的原子分辨率生物物理信息资源。以NMR-STAR ASCII格式存档的NMR数据已在关系数据库中实现。然而,用户要从NMR-STAR文件或关系数据库中检索与其他生物数据库中的数据相关的数据仍然相当困难。
为了增强BMRB数据库的互操作性,我们将BMRB条目完全转换为两种标准结构化数据格式,XML和RDF,作为NMR-STAR数据的通用开放表示形式。此外,还部署了一个SPARQL端点。所描述的案例研究表明,对BMRB、UniProt和人类在线孟德尔遗传(OMIM)的SPARQL端点进行简单查询,可用于结合单核苷酸多态性(SNP)及其表型信息对蛋白质进行NMR和基于结构的分析。
我们开发了BMRB/XML和BMRB/RDF,并展示了它们通过标准语义网技术在执行将BMRB与其他数据库链接起来的联合SPARQL查询中的应用。这将促进跨各种信息资源的数据交换。