Kaila Tanvi, Chaduvla Pavan K, Saxena Swati, Bahadur Kaushlendra, Gahukar Santosh J, Chaudhury Ashok, Sharma T R, Singh N K, Gaikwad Kishor
ICAR-National Research Centre on Plant BiotechnologyNew Delhi, India; Department of Bio & Nanotechnology, Guru Jambheshwar University of Science & TechnologyHisar, India.
ICAR-National Research Centre on Plant Biotechnology New Delhi, India.
Front Plant Sci. 2016 Dec 9;7:1847. doi: 10.3389/fpls.2016.01847. eCollection 2016.
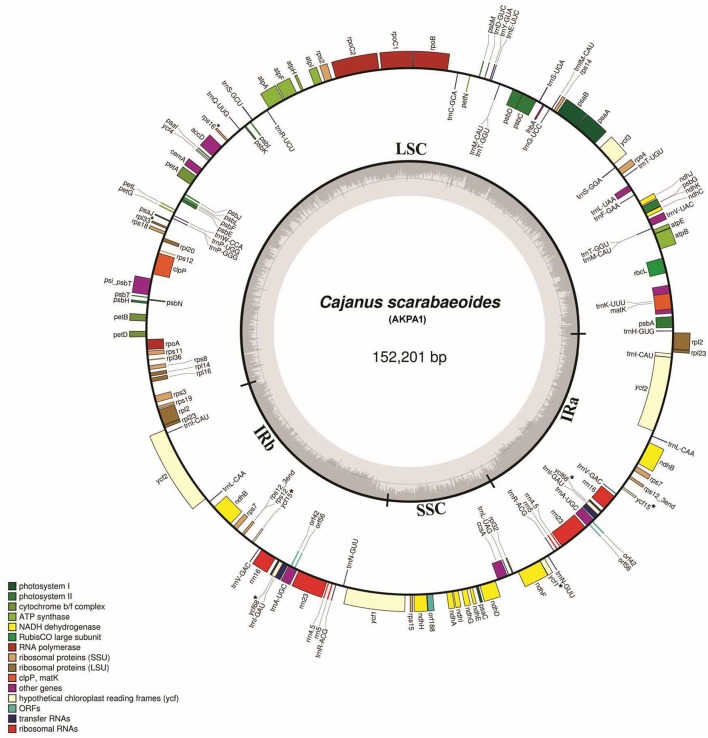
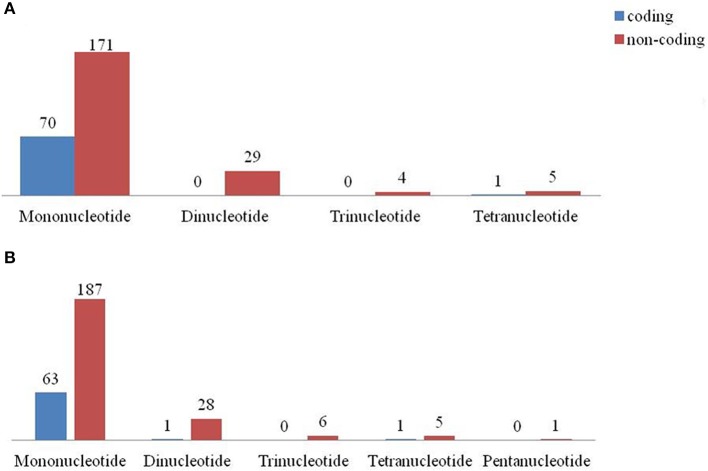
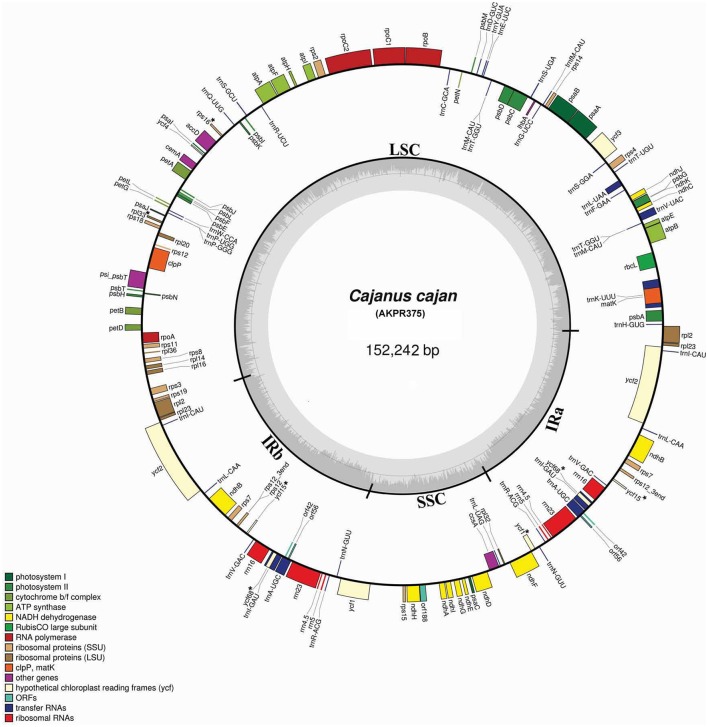
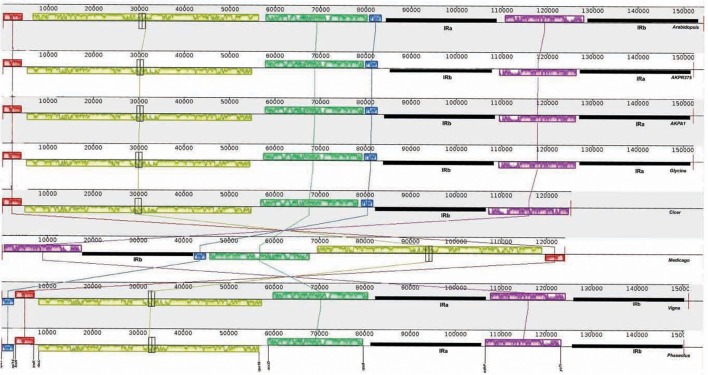
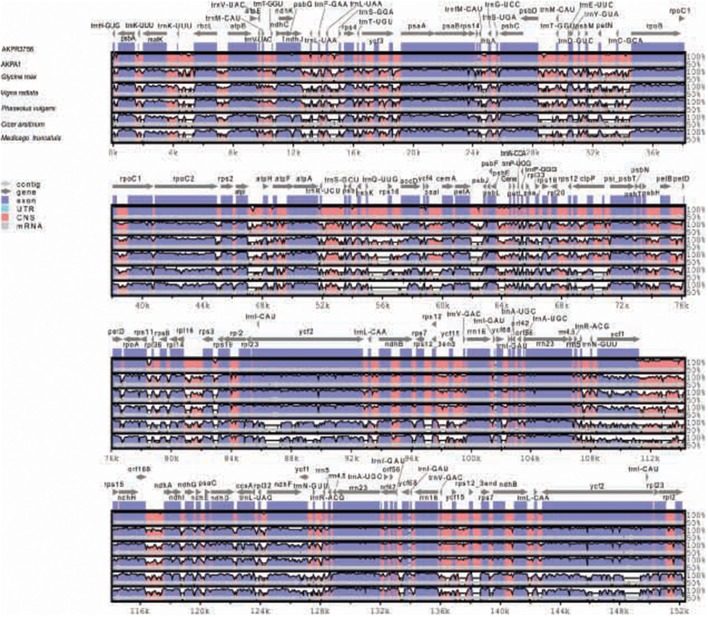
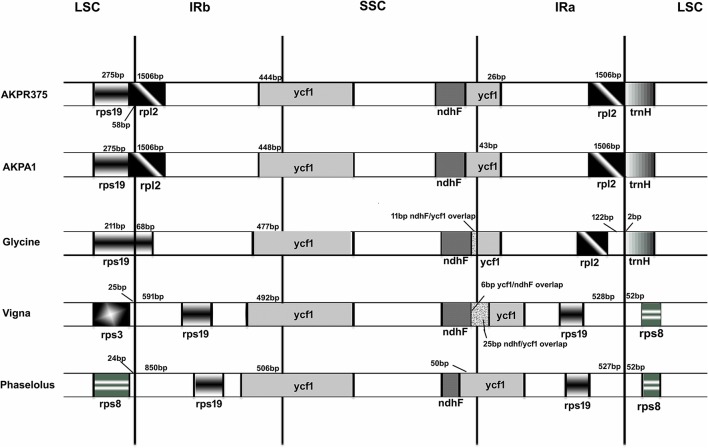
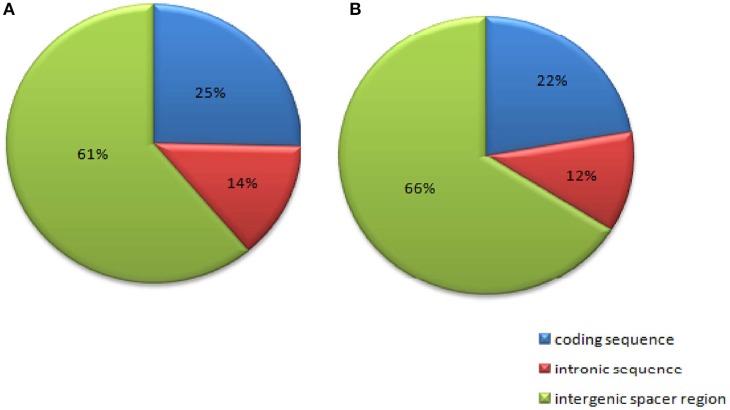
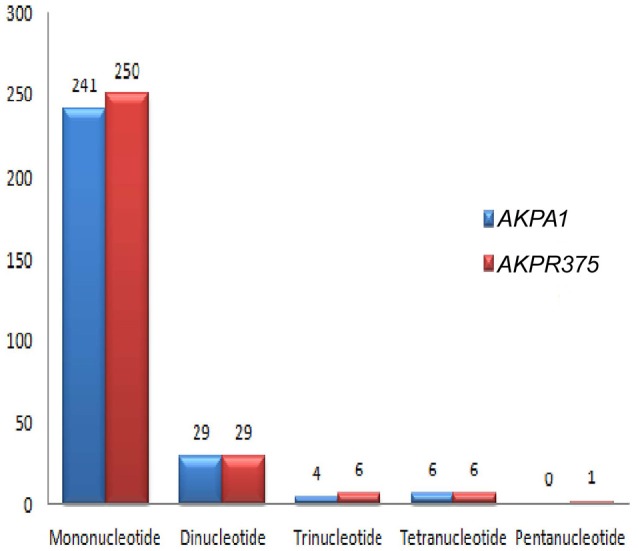
Pigeonpea ( (L.) Millspaugh), a diploid (2n = 22) legume crop with a genome size of 852 Mbp, serves as an important source of human dietary protein especially in South East Asian and African regions. In this study, the draft chloroplast genomes of and (L.) Thouars were generated. is an important species of the gene pool and has also been used for developing promising CMS system by different groups. A male sterile genotype harboring the cytoplasm was used for sequencing the plastid genome. The cp genome of is 152,242bp long, having a quadripartite structure with LSC of 83,455 bp and SSC of 17,871 bp separated by IRs of 25,398 bp. Similarly, the cp genome of is 152,201bp long, having a quadripartite structure in which IRs of 25,402 bp length separates 83,423 bp of LSC and 17,854 bp of SSC. The pigeonpea cp genome contains 116 unique genes, including 30 tRNA, 4 rRNA, 78 predicted protein coding genes and 5 pseudogenes. A 50 kb inversion was observed in the LSC region of pigeonpea cp genome, consistent with other legumes. Comparison of cp genome with other legumes revealed the contraction of IR boundaries due to the absence of gene in the IR region. Chloroplast SSRs were mined and a total of 280 and 292 cpSSRs were identified in and respectively. RNA editing was observed at 37 sites in both and , with maximum occurrence in the genes. The pigeonpea cp genome sequence would be beneficial in providing informative molecular markers which can be utilized for genetic diversity analysis and aid in understanding the plant systematics studies among major grain legumes.
木豆((L.) Millspaugh)是一种二倍体(2n = 22)豆科作物,基因组大小为852 Mbp,是人类膳食蛋白质的重要来源,尤其是在东南亚和非洲地区。在本研究中,生成了木豆和(L.) Thouars的叶绿体基因组草图。木豆是基因库中的一个重要物种,不同研究团队也利用它开发出了有前景的细胞质雄性不育(CMS)系统。一个带有细胞质的雄性不育基因型被用于对质体基因组进行测序。木豆的叶绿体基因组长度为152,242bp,具有四分体结构,其中大单拷贝区(LSC)为83,455 bp,小单拷贝区(SSC)为17,871 bp,由两个25,398 bp的反向重复序列(IR)隔开。同样,木豆的叶绿体基因组长度为152,201bp,也具有四分体结构,其中25,402 bp长的反向重复序列将83,423 bp的大单拷贝区和17,854 bp的小单拷贝区分开。木豆叶绿体基因组包含116个独特基因,包括30个tRNA、4个rRNA、78个预测的蛋白质编码基因和5个假基因。在木豆叶绿体基因组的大单拷贝区观察到一个50 kb的倒位,这与其他豆科植物一致。将叶绿体基因组与其他豆科植物进行比较发现,由于反向重复序列区域中缺少基因,导致反向重复序列边界收缩。挖掘了叶绿体简单序列重复(cpSSR),在木豆和木豆中分别鉴定出280个和292个cpSSR。在木豆和木豆中均在37个位点观察到RNA编辑,其中在基因中出现的频率最高。木豆叶绿体基因组序列将有助于提供信息丰富的分子标记,可用于遗传多样性分析,并有助于理解主要食用豆类之间的植物系统学研究。