Harron Katie, Hagger-Johnson Gareth, Gilbert Ruth, Goldstein Harvey
London School of Hygiene and Tropical Medicine, 15-17 Tavistock Place, London, WC1 H 9SH, UK.
Administrative Data Research Centre for England, UCL, 222 Euston Road, London, NW1 2DA, UK.
BMC Med Res Methodol. 2017 Feb 7;17(1):23. doi: 10.1186/s12874-017-0306-8.
Linkage of administrative data sources often relies on probabilistic methods using a set of common identifiers (e.g. sex, date of birth, postcode). Variation in data quality on an individual or organisational level (e.g. by hospital) can result in clustering of identifier errors, violating the assumption of independence between identifiers required for traditional probabilistic match weight estimation. This potentially introduces selection bias to the resulting linked dataset. We aimed to measure variation in identifier error rates in a large English administrative data source (Hospital Episode Statistics; HES) and to incorporate this information into match weight calculation.
We used 30,000 randomly selected HES hospital admissions records of patients aged 0-1, 5-6 and 18-19 years, for 2011/2012, linked via NHS number with data from the Personal Demographic Service (PDS; our gold-standard). We calculated identifier error rates for sex, date of birth and postcode and used multi-level logistic regression to investigate associations with individual-level attributes (age, ethnicity, and gender) and organisational variation. We then derived: i) weights incorporating dependence between identifiers; ii) attribute-specific weights (varying by age, ethnicity and gender); and iii) organisation-specific weights (by hospital). Results were compared with traditional match weights using a simulation study.
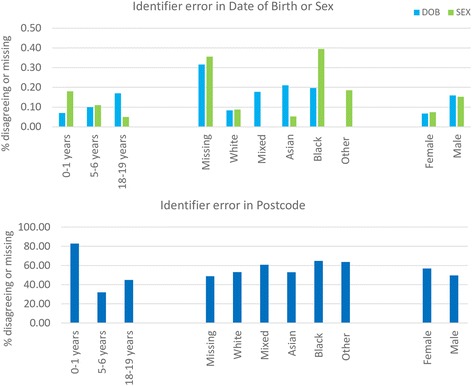
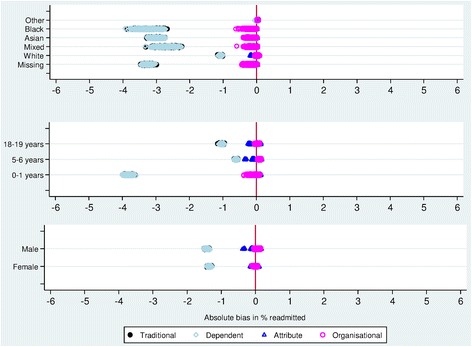
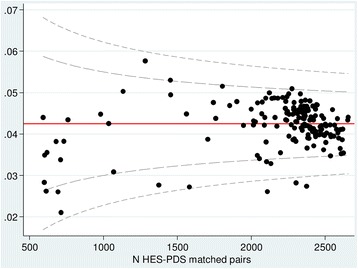
Identifier errors (where values disagreed in linked HES-PDS records) or missing values were found in 0.11% of records for sex and date of birth and in 53% of records for postcode. Identifier error rates differed significantly by age, ethnicity and sex (p < 0.0005). Errors were less frequent in males, in 5-6 year olds and 18-19 year olds compared with infants, and were lowest for the Asian ethic group. A simulation study demonstrated that substantial bias was introduced into estimated readmission rates in the presence of identifier errors. Attribute- and organisational-specific weights reduced this bias compared with weights estimated using traditional probabilistic matching algorithms.
We provide empirical evidence on variation in rates of identifier error in a widely-used administrative data source and propose a new method for deriving match weights that incorporates additional data attributes. Our results demonstrate that incorporating information on variation by individual-level characteristics can help to reduce bias due to linkage error.
行政数据源的链接通常依赖于使用一组通用标识符(如性别、出生日期、邮政编码)的概率方法。个体或组织层面(如按医院)的数据质量差异可能导致标识符错误的聚集,从而违反传统概率匹配权重估计所需的标识符之间独立性的假设。这可能会给最终的链接数据集带来选择偏差。我们旨在测量一个大型英国行政数据源(医院 Episode 统计;HES)中标识符错误率的差异,并将此信息纳入匹配权重计算。
我们使用了 2011/2012 年随机选取的 30000 份 HES 医院入院记录,这些记录涉及 0 - 1 岁、5 - 6 岁和 18 - 19 岁的患者,通过国民健康服务号码与个人人口统计服务(PDS;我们的金标准)的数据进行链接。我们计算了性别、出生日期和邮政编码的标识符错误率,并使用多水平逻辑回归来研究与个体层面属性(年龄、种族和性别)以及组织差异的关联。然后我们得出:i)纳入标识符之间依赖性的权重;ii)特定属性权重(因年龄、种族和性别而异);以及 iii)特定组织权重(按医院)。通过模拟研究将结果与传统匹配权重进行比较。
在链接的 HES - PDS 记录中,性别和出生日期记录的 0.11%以及邮政编码记录的 53%存在标识符错误(即值不一致)或缺失值。标识符错误率在年龄、种族和性别上有显著差异(p < 0.0005)。与婴儿相比,男性、5 - 6 岁和 18 - 19 岁人群中的错误频率较低,亚洲种族群体的错误率最低。一项模拟研究表明,在存在标识符错误的情况下,估计的再入院率会引入大量偏差。与使用传统概率匹配算法估计的权重相比,特定属性和特定组织的权重减少了这种偏差。
我们提供了关于一个广泛使用的行政数据源中标识符错误率差异的实证证据,并提出了一种推导匹配权重的新方法,该方法纳入了额外的数据属性。我们的结果表明,纳入个体层面特征差异的信息有助于减少因链接错误导致的偏差。