Yoshida Kosuke, Yoshimoto Junichiro, Doya Kenji
Graduate School of Informatics, Kyoto University, Kyoto, Japan.
Neural Computation Unit, Okinawa Institute of Science and Technology, Okinawa, Japan.
BMC Bioinformatics. 2017 Feb 14;18(1):108. doi: 10.1186/s12859-017-1543-x.
Advance in high-throughput technologies in genomics, transcriptomics, and metabolomics has created demand for bioinformatics tools to integrate high-dimensional data from different sources. Canonical correlation analysis (CCA) is a statistical tool for finding linear associations between different types of information. Previous extensions of CCA used to capture nonlinear associations, such as kernel CCA, did not allow feature selection or capturing of multiple canonical components. Here we propose a novel method, two-stage kernel CCA (TSKCCA) to select appropriate kernels in the framework of multiple kernel learning.
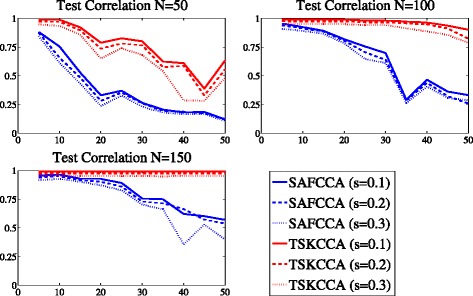
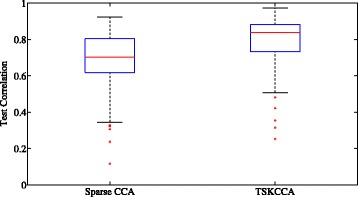
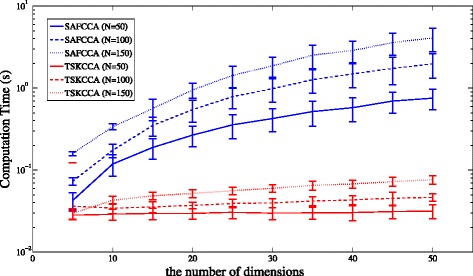
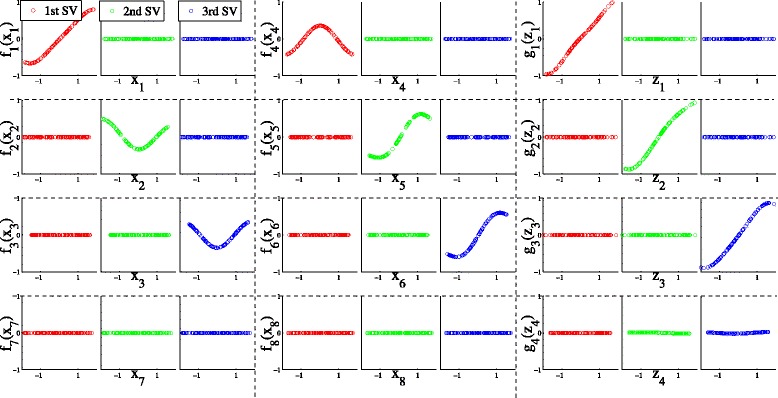
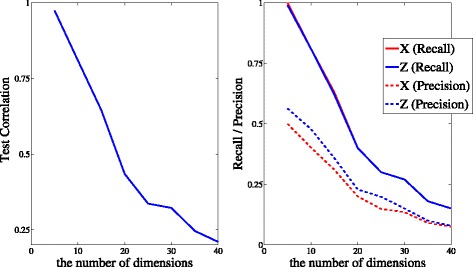
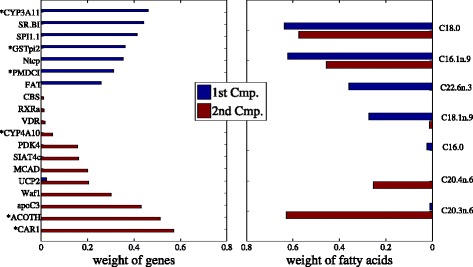
TSKCCA first selects relevant kernels based on the HSIC criterion in the multiple kernel learning framework. Weights are then derived by non-negative matrix decomposition with L1 regularization. Using artificial datasets and nutrigenomic datasets, we show that TSKCCA can extract multiple, nonlinear associations among high-dimensional data and multiplicative interactions among variables.
TSKCCA can identify nonlinear associations among high-dimensional data more reliably than previous nonlinear CCA methods.
基因组学、转录组学和代谢组学中高通量技术的进步引发了对生物信息学工具的需求,以便整合来自不同来源的高维数据。典型相关分析(CCA)是一种用于寻找不同类型信息之间线性关联的统计工具。以前用于捕获非线性关联的CCA扩展方法,如核CCA,不允许进行特征选择或捕获多个典型成分。在此,我们提出一种新方法——两阶段核CCA(TSKCCA),用于在多核学习框架中选择合适的核。
TSKCCA首先在多核学习框架中基于HSIC标准选择相关核。然后通过带有L1正则化的非负矩阵分解得出权重。使用人工数据集和营养基因组数据集,我们表明TSKCCA能够提取高维数据之间的多个非线性关联以及变量之间的乘法相互作用。
与以前的非线性CCA方法相比,TSKCCA能够更可靠地识别高维数据之间的非线性关联。