Najibi Seyed Morteza, Maadooliat Mehdi, Zhou Lan, Huang Jianhua Z, Gao Xin
Department of Statistics, College of Sciences, Shiraz University, Shiraz, Iran.
Department of Mathematics, Statistics and Computer Science, Marquette University, WI 53201-1881, USA; Center for Human Genetics, Marshfield Clinic Research Institute, Marshfield, WI 54449, USA.
Comput Struct Biotechnol J. 2017 Feb 8;15:243-254. doi: 10.1016/j.csbj.2017.01.011. eCollection 2017.
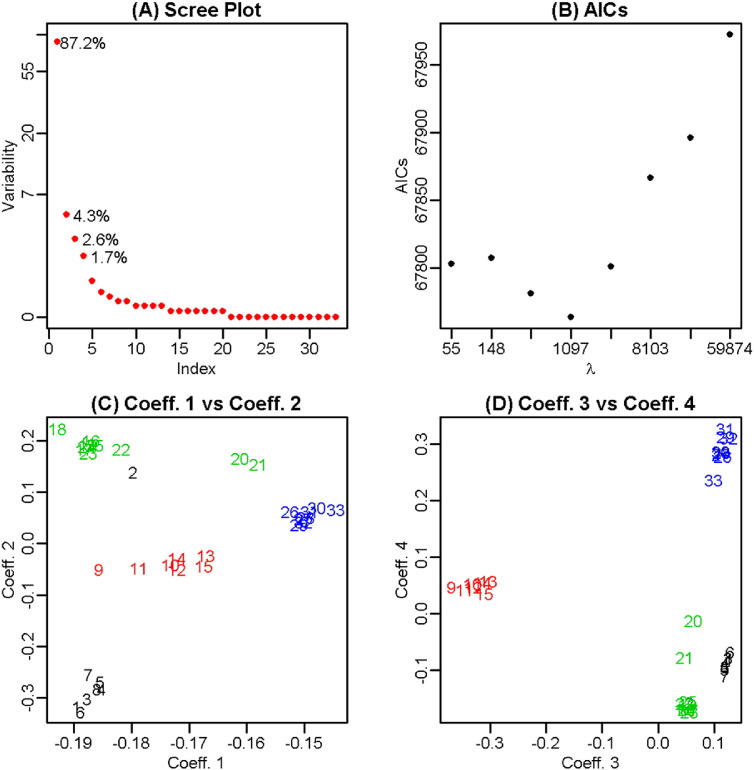
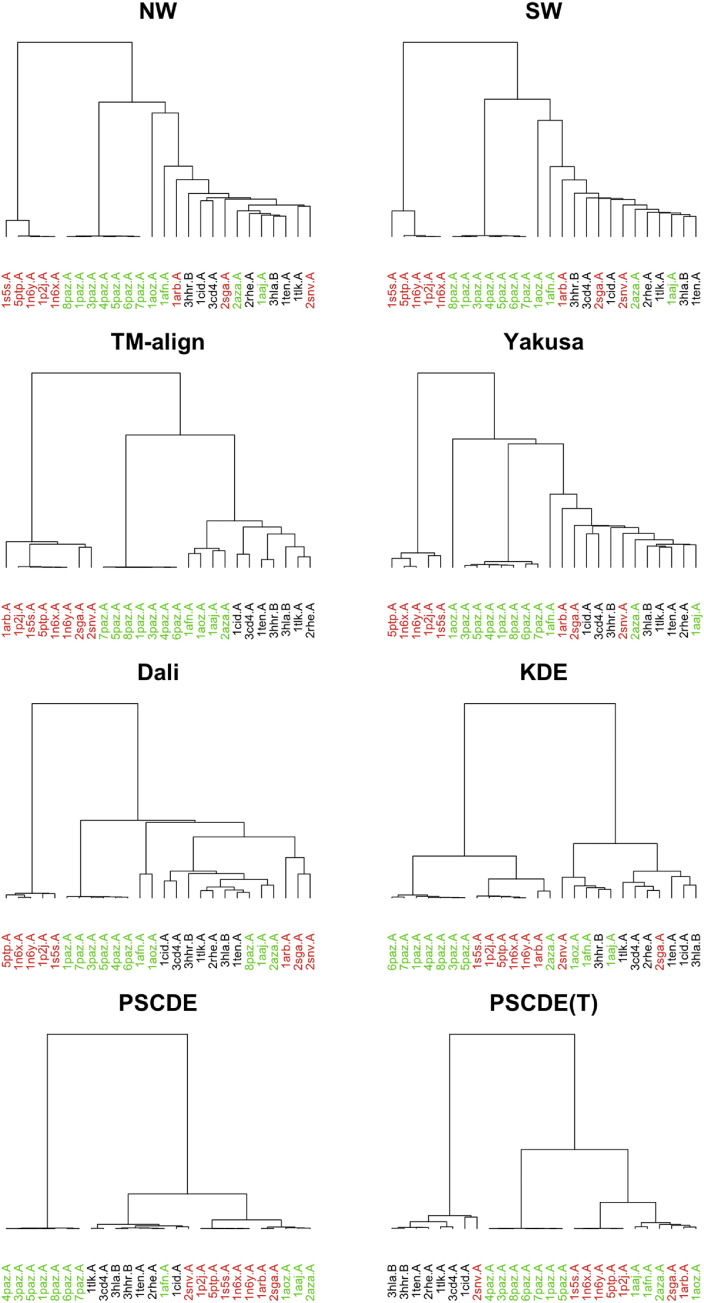
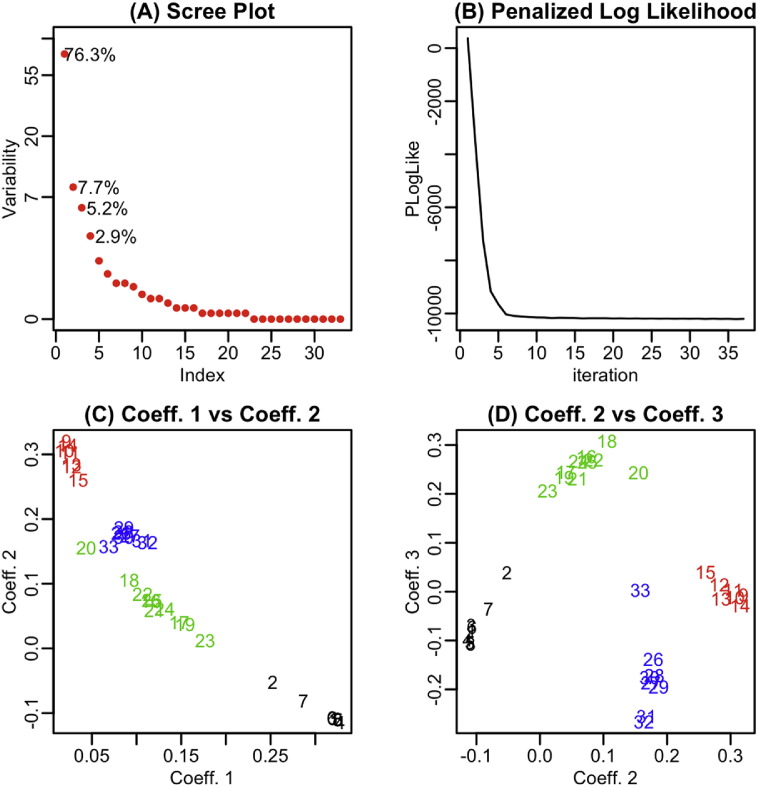
Recently, the study of protein structures using angular representations has attracted much attention among structural biologists. The main challenge is how to efficiently model the continuous conformational space of the protein structures based on the differences and similarities between different Ramachandran plots. Despite the presence of statistical methods for modeling angular data of proteins, there is still a substantial need for more sophisticated and faster statistical tools to model the large-scale circular datasets. To address this need, we have developed a nonparametric method for collective estimation of multiple bivariate density functions for a collection of populations of protein backbone angles. The proposed method takes into account the circular nature of the angular data using trigonometric spline which is more efficient compared to existing methods. This collective density estimation approach is widely applicable when there is a need to estimate multiple density functions from different populations with common features. Moreover, the coefficients of adaptive basis expansion for the fitted densities provide a low-dimensional representation that is useful for visualization, clustering, and classification of the densities. The proposed method provides a novel and unique perspective to two important and challenging problems in protein structure research: structure-based protein classification and angular-sampling-based protein loop structure prediction.
最近,使用角度表示法研究蛋白质结构在结构生物学家中引起了广泛关注。主要挑战在于如何基于不同拉马钱德兰图之间的差异和相似性,有效地对蛋白质结构的连续构象空间进行建模。尽管存在用于对蛋白质角度数据进行建模的统计方法,但仍然迫切需要更复杂、更快的统计工具来对大规模圆形数据集进行建模。为满足这一需求,我们开发了一种非参数方法,用于对蛋白质主链角度群体集合的多个二元密度函数进行集体估计。所提出的方法使用三角样条考虑了角度数据的圆形性质,与现有方法相比效率更高。当需要从具有共同特征的不同群体中估计多个密度函数时,这种集体密度估计方法具有广泛的适用性。此外,拟合密度的自适应基展开系数提供了一种低维表示,可用于密度的可视化、聚类和分类。所提出的方法为蛋白质结构研究中的两个重要且具有挑战性的问题提供了新颖独特的视角:基于结构的蛋白质分类和基于角度采样的蛋白质环结构预测。