Hitz Benjamin C, Rowe Laurence D, Podduturi Nikhil R, Glick David I, Baymuradov Ulugbek K, Malladi Venkat S, Chan Esther T, Davidson Jean M, Gabdank Idan, Narayana Aditi K, Onate Kathrina C, Hilton Jason, Ho Marcus C, Lee Brian T, Miyasato Stuart R, Dreszer Timothy R, Sloan Cricket A, Strattan J Seth, Tanaka Forrest Y, Hong Eurie L, Cherry J Michael
Stanford University School of Medicine, Department of Genetics, Stanford, California, United States of America.
University of California Santa Cruz, Baskin School of Engineering, Center for Biomolecular Science and Engineering, Santa Cruz, California, United States of America.
PLoS One. 2017 Apr 12;12(4):e0175310. doi: 10.1371/journal.pone.0175310. eCollection 2017.
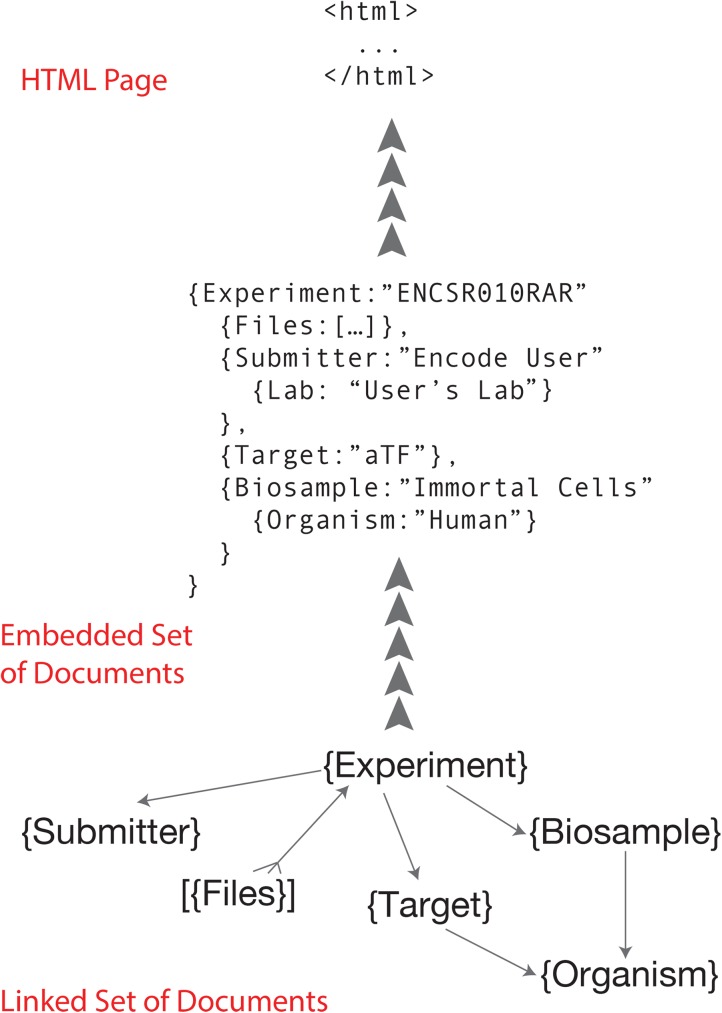
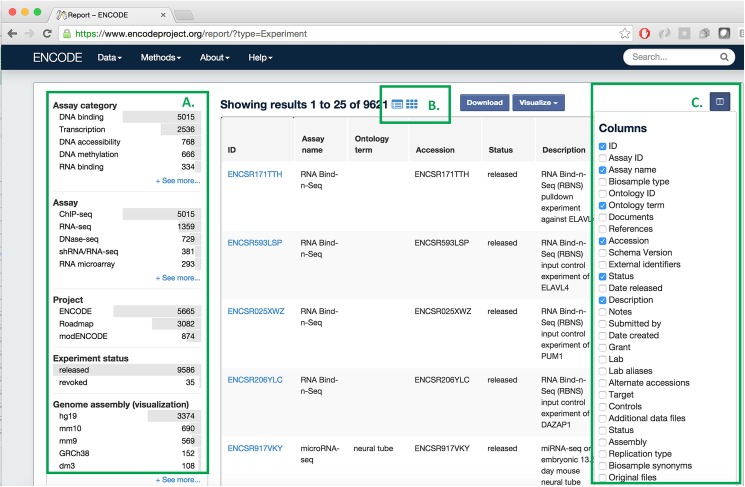
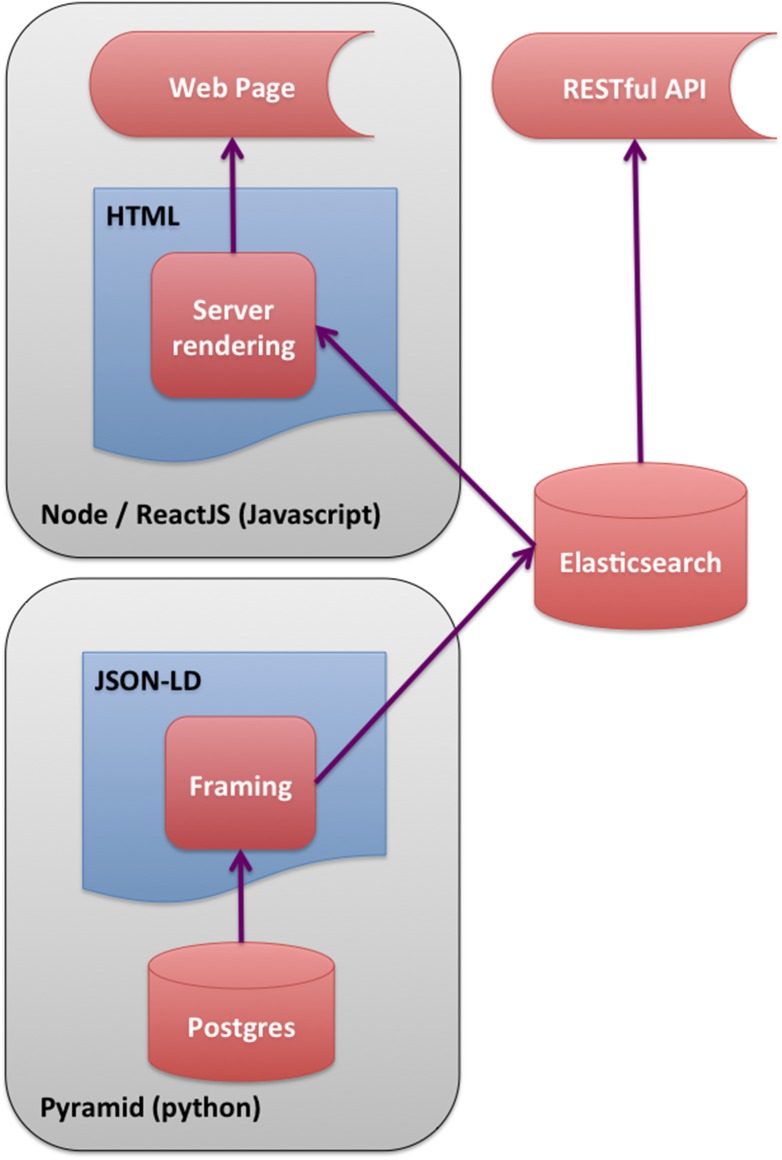
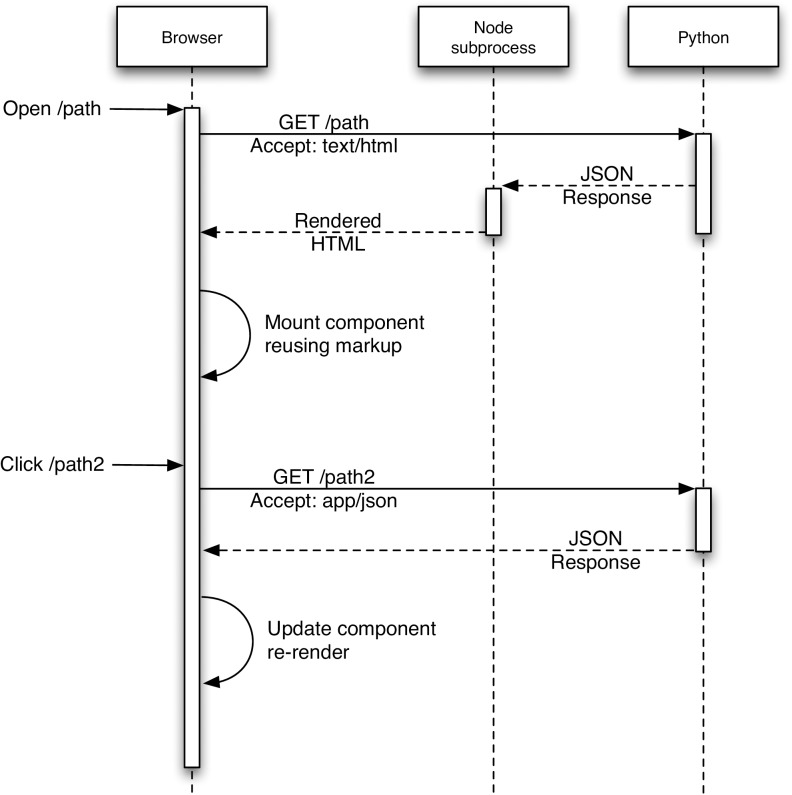
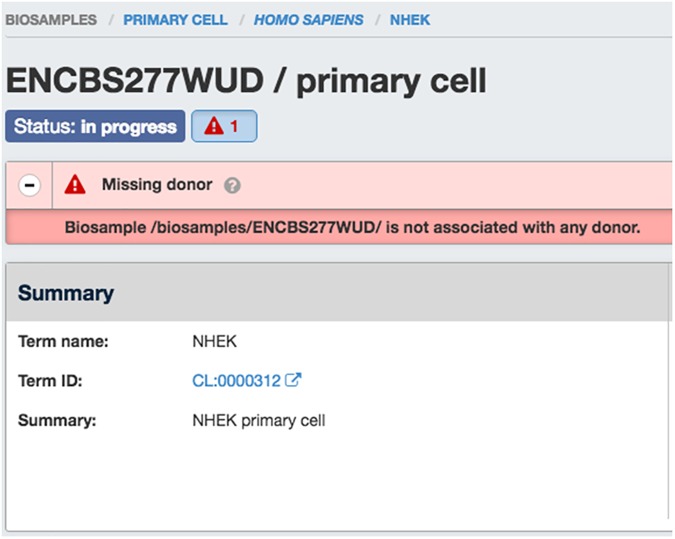
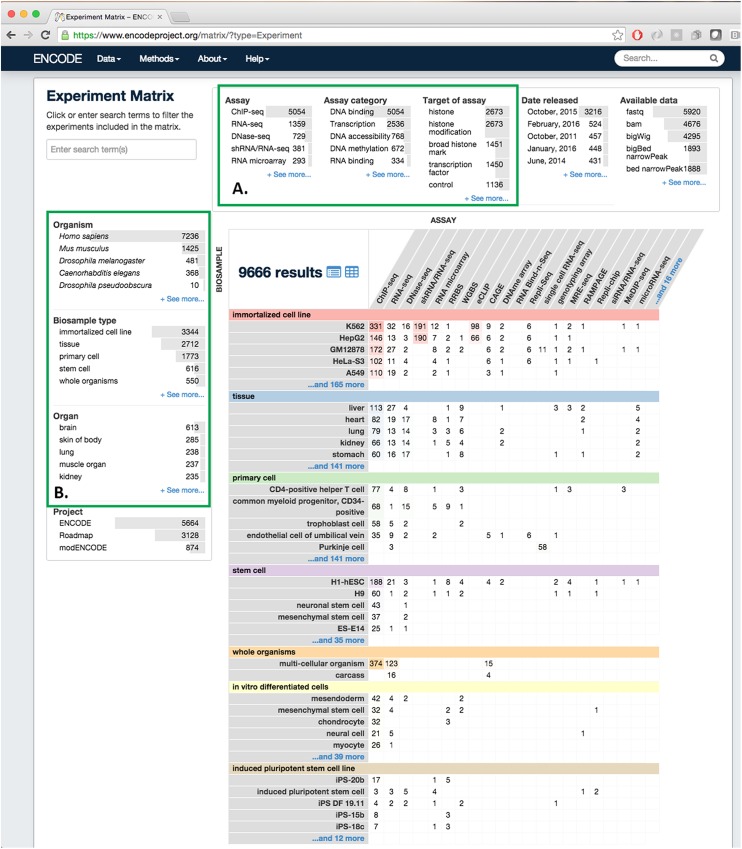
The Encyclopedia of DNA elements (ENCODE) project is an ongoing collaborative effort to create a comprehensive catalog of functional elements initiated shortly after the completion of the Human Genome Project. The current database exceeds 6500 experiments across more than 450 cell lines and tissues using a wide array of experimental techniques to study the chromatin structure, regulatory and transcriptional landscape of the H. sapiens and M. musculus genomes. All ENCODE experimental data, metadata, and associated computational analyses are submitted to the ENCODE Data Coordination Center (DCC) for validation, tracking, storage, unified processing, and distribution to community resources and the scientific community. As the volume of data increases, the identification and organization of experimental details becomes increasingly intricate and demands careful curation. The ENCODE DCC has created a general purpose software system, known as SnoVault, that supports metadata and file submission, a database used for metadata storage, web pages for displaying the metadata and a robust API for querying the metadata. The software is fully open-source, code and installation instructions can be found at: http://github.com/ENCODE-DCC/snovault/ (for the generic database) and http://github.com/ENCODE-DCC/encoded/ to store genomic data in the manner of ENCODE. The core database engine, SnoVault (which is completely independent of ENCODE, genomic data, or bioinformatic data) has been released as a separate Python package.
DNA 元件百科全书(ENCODE)计划是一项正在进行的合作项目,旨在创建一份功能元件的综合目录,该项目在人类基因组计划完成后不久就启动了。当前的数据库包含超过450种细胞系和组织的6500多个实验,使用了广泛的实验技术来研究智人和小家鼠基因组的染色质结构、调控和转录图谱。所有ENCODE实验数据、元数据以及相关的计算分析都提交给ENCODE数据协调中心(DCC)进行验证、跟踪、存储、统一处理,并分发给社区资源和科学界。随着数据量的增加,实验细节的识别和组织变得越来越复杂,需要仔细管理。ENCODE DCC创建了一个通用软件系统,称为SnoVault,它支持元数据和文件提交、用于存储元数据的数据库、用于显示元数据的网页以及用于查询元数据的强大API。该软件是完全开源的,代码和安装说明可在以下网址找到:http://github.com/ENCODE-DCC/snovault/(用于通用数据库)以及http://github.com/ENCODE-DCC/encoded/,用于以ENCODE的方式存储基因组数据。核心数据库引擎SnoVault(它完全独立于ENCODE、基因组数据或生物信息数据)已作为一个单独的Python包发布。