Jana Tanmoy, Ghosh Abhirupa, Das Mandal Sukhen, Banerjee Raja, Saha Sudipto
Bioinformatics Centre, Bose Institute, P 1/12, C.I.T. Road, Scheme-VII (M), Kolkata, West Bengal, India.
Department of Bioinformatics, Bose Institute, P 1/12, C.I.T. Road, Scheme-VII (M), Kolkata, West Bengal, India.
R Soc Open Sci. 2017 Apr 19;4(4):160501. doi: 10.1098/rsos.160501. eCollection 2017 Apr.
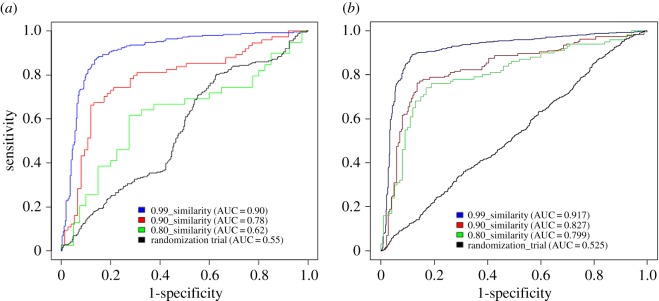
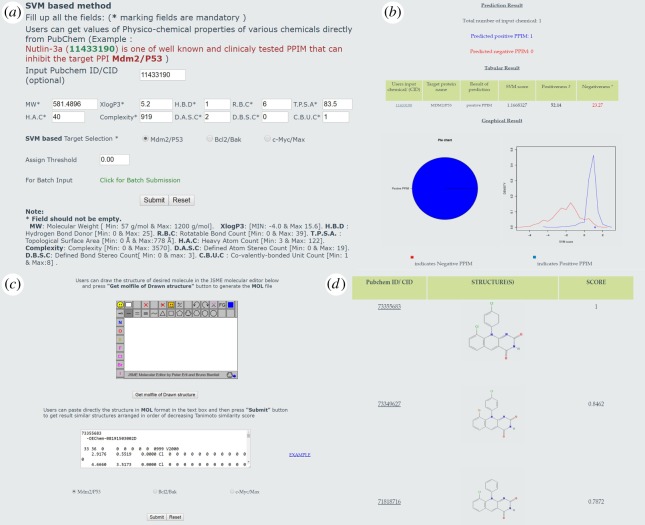
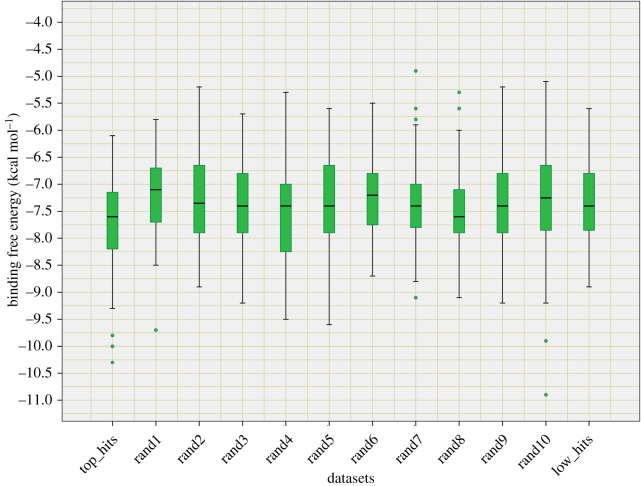
PPIMpred is a web server that allows high-throughput screening of small molecules for targeting specific protein-protein interactions, namely Mdm2/P53, Bcl2/Bak and c-Myc/Max. Three different kernels of support vector machine (SVM), namely, linear, polynomial and radial basis function (RBF), and two other machine learning techniques including Naive Bayes and Random Forest were used to train the models. A fivefold cross-validation technique was used to measure the performance of these classifiers. The RBF kernel of SVM outperformed and/or was comparable with all other methods with accuracy values of 83%, 79% and 90% for Mdm2/P53, Bcl2/Bak and c-Myc/Max, respectively. About 80% of the predicted SVM scores of training/testing datasets from Mdm2/P53 and Bcl2/Bak have significant IC50 values and docking scores. The proposed models achieved an accuracy of 66-90% with blind sets. The three mentioned (Mdm2/P53, Bcl2/Bak and c-Myc/Max) proposed models were screened in a large dataset of 265 242 small chemicals from National Cancer Institute open database. To further realize the robustness of this approach, hits with high and random SVM scores were used for molecular docking in AutoDock Vina wherein the molecules with high and random predicted SVM scores yielded moderately significant docking scores (-values < 0.1). In addition to the above-mentioned classification scheme, this web server also allows users to get the structural and chemical similarities with known chemical modulators or drug-like molecules based on Tanimoto coefficient similarity search algorithm. PPIMpred is freely available at http://bicresources.jcbose.ac.in/ssaha4/PPIMpred/.
PPIMpred是一个网络服务器,可用于高通量筛选小分子以靶向特定的蛋白质-蛋白质相互作用,即Mdm2/P53、Bcl2/Bak和c-Myc/Max。使用支持向量机(SVM)的三种不同内核,即线性、多项式和径向基函数(RBF),以及包括朴素贝叶斯和随机森林在内的另外两种机器学习技术来训练模型。采用五重交叉验证技术来衡量这些分类器的性能。SVM的RBF内核表现优于和/或与所有其他方法相当,对于Mdm2/P53、Bcl2/Bak和c-Myc/Max,其准确率分别为83%、79%和90%。来自Mdm2/P53和Bcl2/Bak的训练/测试数据集的预测SVM分数中约80%具有显著的IC50值和对接分数。所提出的模型在盲集上的准确率达到66%-90%。在来自美国国立癌症研究所开放数据库中的265242种小化学物质的大数据集中筛选了上述三种(Mdm2/P53、Bcl2/Bak和c-Myc/Max)提出的模型。为了进一步实现这种方法的稳健性,将具有高SVM分数和随机SVM分数的命中物用于AutoDock Vina中的分子对接,其中具有高预测SVM分数和随机预测SVM分数的分子产生了适度显著的对接分数(-值<0.1)。除了上述分类方案外,该网络服务器还允许用户基于Tanimoto系数相似性搜索算法获得与已知化学调节剂或类药物分子的结构和化学相似性。可在http://bicresources.jcbose.ac.in/ssaha4/PPIMpred/免费获取PPIMpred。