School of Biomedical Informatics, The University of Texas Health Science Center at Houston, Houston, TX 77030, USA.
St. John's School, Houston, TX 77019, USA.
J Biomed Inform. 2017 Nov;75S:S129-S137. doi: 10.1016/j.jbi.2017.06.014. Epub 2017 Jun 15.
Mental health is becoming an increasingly important topic in healthcare. Psychiatric symptoms, which consist of subjective descriptions of the patient's experience, as well as the nature and severity of mental disorders, are critical to support the phenotypic classification for personalized prevention, diagnosis, and intervention of mental disorders. However, few automated approaches have been proposed to extract psychiatric symptoms from clinical text, mainly due to (a) the lack of annotated corpora, which are time-consuming and costly to build, and (b) the inherent linguistic difficulties that symptoms present as they are not well-defined clinical concepts like diseases. The goal of this study is to investigate techniques for recognizing psychiatric symptoms in clinical text without labeled data. Instead, external knowledge in the form of publicly available "seed" lists of symptoms is leveraged using unsupervised distributional representations.
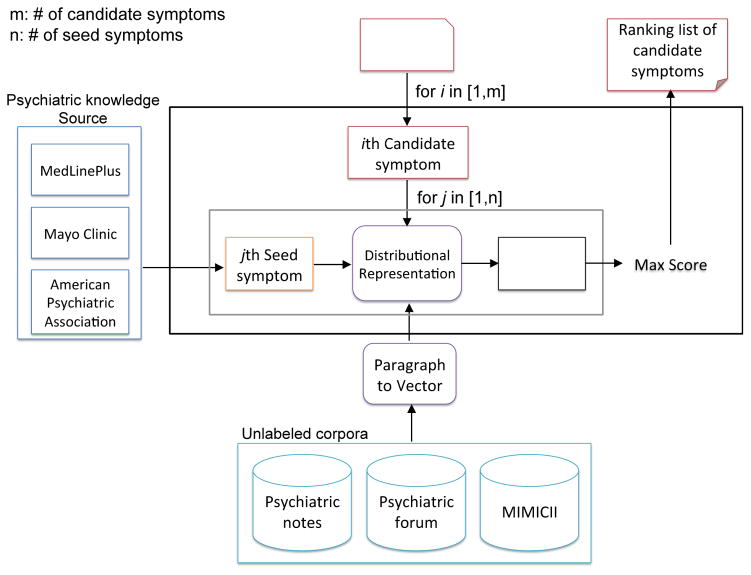
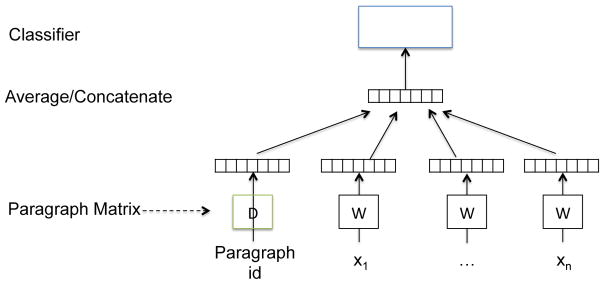
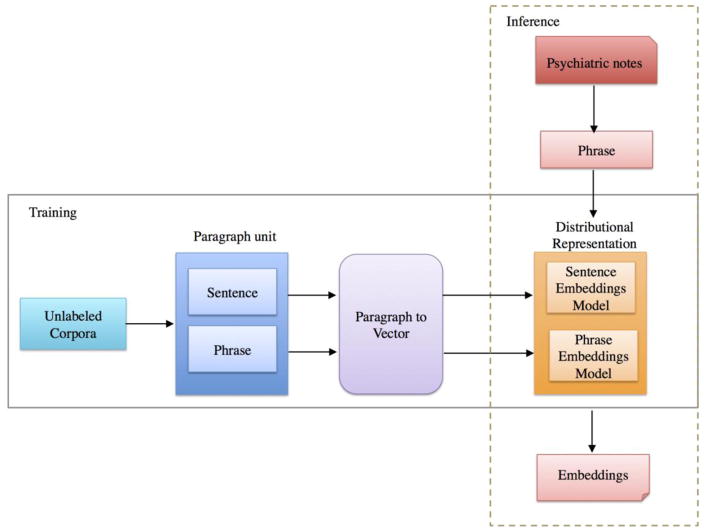
First, psychiatric symptoms are collected from three online repositories of healthcare knowledge for consumers-MedlinePlus, Mayo Clinic, and the American Psychiatric Association-for use as seed terms. Candidate symptoms in psychiatric notes are automatically extracted using phrasal syntax patterns. In particular, the 2016 CEGS N-GRID challenge data serves as the psychiatric note corpus. Second, three corpora-psychiatric notes, psychiatric forum data, and MIMIC II-are adopted to generate distributional representations with paragraph2vec. Finally, semantic similarity between the distributional representations of the seed symptoms and candidate symptoms is calculated to assess the relevance of a phrase. Experiments were performed on a set of psychiatric notes from the CEGS N-GRID 2016 Challenge.
RESULTS & CONCLUSION: Our method demonstrates good performance at extracting symptoms from an unseen corpus, including symptoms with no word overlap with the provided seed terms. Semantic similarity based on the distributional representation outperformed baseline methods. Our experiment yielded two interesting results. First, distributional representations built from social media data outperformed those built from clinical data. And second, the distributional representation model built from sentences resulted in better representations of phrases than the model built from phrase alone.
心理健康正成为医疗保健领域日益重要的议题。精神症状包括对患者体验的主观描述以及精神障碍的性质和严重程度,对支持精神障碍的表型分类以实现个性化预防、诊断和干预至关重要。然而,由于(a) 缺乏注释语料库,构建起来既耗时又昂贵,以及(b) 症状本身作为非疾病等明确的临床概念存在固有语言困难,因此很少有自动化方法被提出用于从临床文本中提取精神症状。本研究旨在研究在无标记数据的情况下识别临床文本中精神症状的技术。相反,利用未标记数据的分布式表示形式,以公开可用的“种子”症状列表形式利用外部知识。
首先,从三个在线消费者医疗保健知识库(MedlinePlus、梅奥诊所和美国精神病学协会)中收集精神症状,用作种子术语。使用短语语法模式自动提取精神科病历中的候选症状。特别是,2016 年 CEGS N-GRID 挑战赛数据作为精神科病历语料库。其次,采用三个语料库(精神科病历、精神科论坛数据和 MIMIC II)使用 paragraph2vec 生成分布式表示。最后,计算种子症状和候选症状的分布式表示之间的语义相似度,以评估短语的相关性。在 CEGS N-GRID 2016 挑战赛的一组精神科病历上进行了实验。
我们的方法在从未见语料库中提取症状方面表现出良好的性能,包括与提供的种子术语无词重叠的症状。基于分布式表示的语义相似性优于基线方法。实验产生了两个有趣的结果。首先,从社交媒体数据构建的分布式表示优于从临床数据构建的分布式表示。其次,从句子构建的分布式表示模型比仅从短语构建的模型更能表示短语。