Posch Lisa, Panahiazar Maryam, Dumontier Michel, Gevaert Olivier
GESIS - Leibniz Institute for the Social Sciences, Cologne, Germany.
Institute for Web Science and Technologies, University of Koblenz-Landau, Koblenz, Germany.
Database (Oxford). 2016 Jan 1;2016. doi: 10.1093/database/baw080.
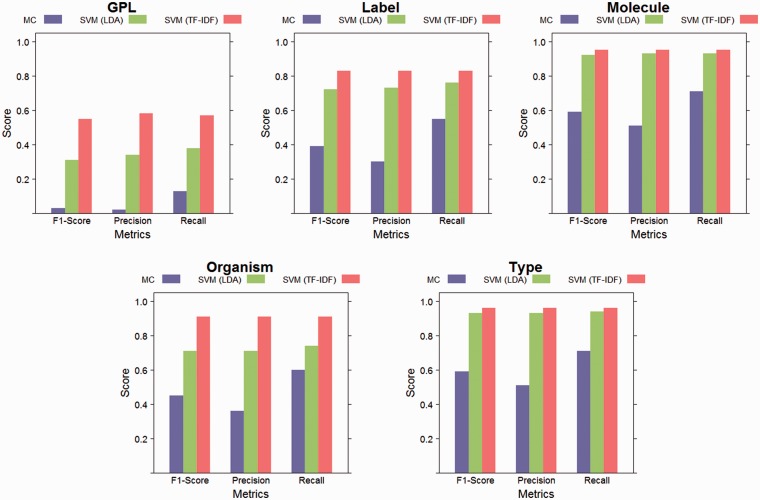
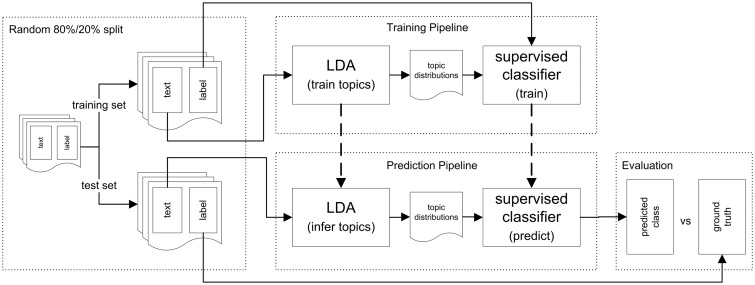
Enormous amounts of biomedical data have been and are being produced by investigators all over the world. However, one crucial and limiting factor in data reuse is accurate, structured and complete description of the data or data about the data-defined as metadata. We propose a framework to predict structured metadata terms from unstructured metadata for improving quality and quantity of metadata, using the Gene Expression Omnibus (GEO) microarray database. Our framework consists of classifiers trained using term frequency-inverse document frequency (TF-IDF) features and a second approach based on topics modeled using a Latent Dirichlet Allocation model (LDA) to reduce the dimensionality of the unstructured data. Our results on the GEO database show that structured metadata terms can be the most accurately predicted using the TF-IDF approach followed by LDA both outperforming the majority vote baseline. While some accuracy is lost by the dimensionality reduction of LDA, the difference is small for elements with few possible values, and there is a large improvement over the majority classifier baseline. Overall this is a promising approach for metadata prediction that is likely to be applicable to other datasets and has implications for researchers interested in biomedical metadata curation and metadata prediction.
世界各地的研究人员已经并正在产生大量的生物医学数据。然而,数据再利用中的一个关键限制因素是对数据或关于数据的数据(定义为元数据)进行准确、结构化和完整的描述。我们提出了一个框架,利用基因表达综合数据库(GEO)微阵列数据库,从非结构化元数据中预测结构化元数据术语,以提高元数据的质量和数量。我们的框架由使用词频-逆文档频率(TF-IDF)特征训练的分类器和基于潜在狄利克雷分配模型(LDA)建模的主题的第二种方法组成,以降低非结构化数据的维度。我们在GEO数据库上的结果表明,使用TF-IDF方法可以最准确地预测结构化元数据术语,其次是LDA,两者都优于多数投票基线。虽然LDA的降维会损失一些准确性,但对于可能值较少的元素,差异很小,并且比多数分类器基线有很大改进。总体而言,这是一种有前途的元数据预测方法,可能适用于其他数据集,对生物医学元数据管理和元数据预测感兴趣的研究人员具有重要意义。