Panahiazar Maryam, Dumontier Michel, Gevaert Olivier
Stanford Center for Biomedical Informatics Research, Center for Data Annotation and Retrieval, Department of Medicine, Stanford University, Stanford, 94305, United States.
Stanford Center for Biomedical Informatics Research, Center for Data Annotation and Retrieval, Department of Medicine, Stanford University, Stanford, 94305, United States.
J Biomed Inform. 2017 Aug;72:132-139. doi: 10.1016/j.jbi.2017.06.017. Epub 2017 Jun 16.
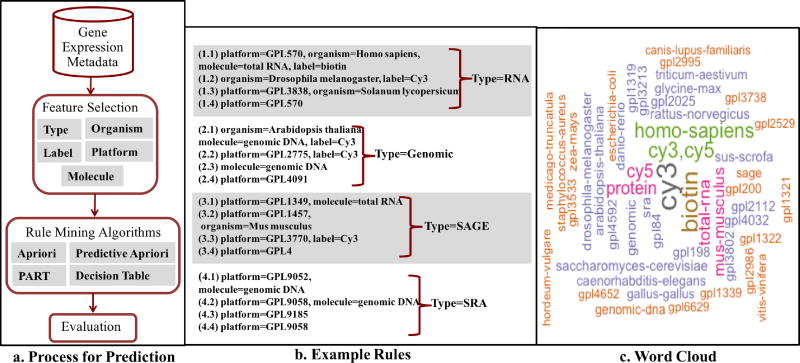
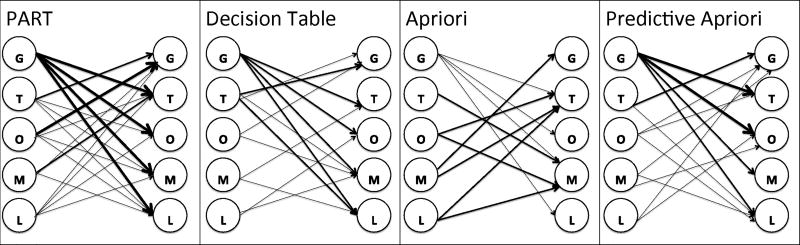
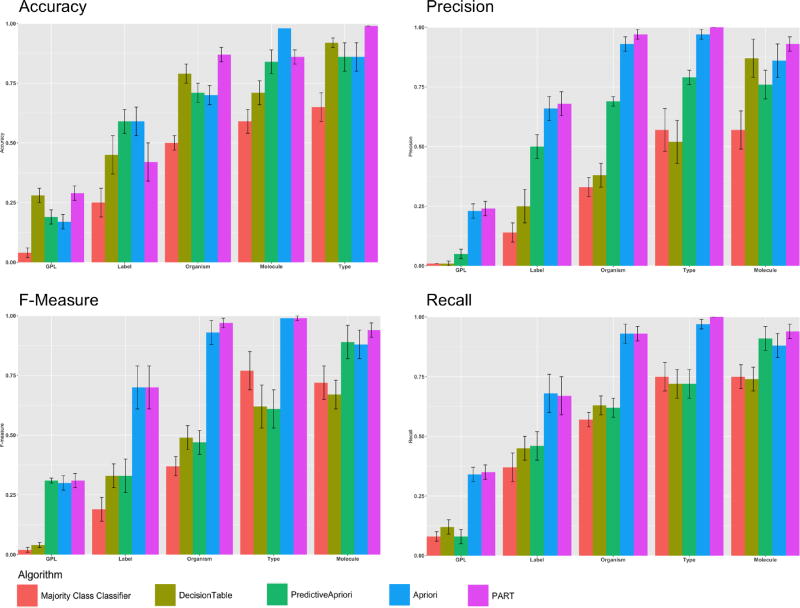
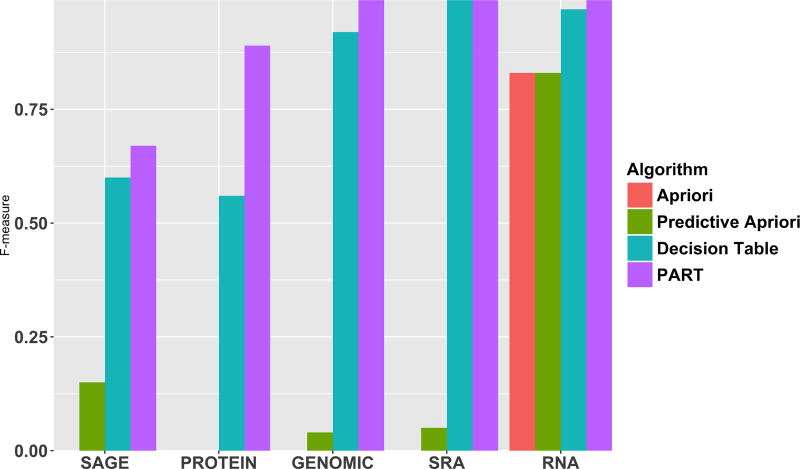
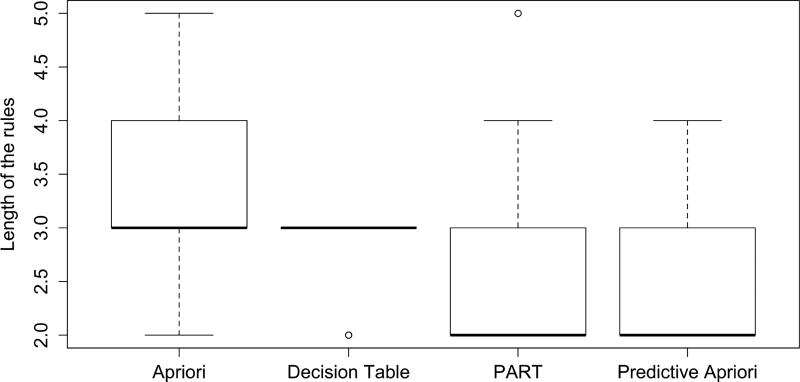
A crucial and limiting factor in data reuse is the lack of accurate, structured, and complete descriptions of data, known as metadata. Towards improving the quantity and quality of metadata, we propose a novel metadata prediction framework to learn associations from existing metadata that can be used to predict metadata values. We evaluate our framework in the context of experimental metadata from the Gene Expression Omnibus (GEO). We applied four rule mining algorithms to the most common structured metadata elements (sample type, molecular type, platform, label type and organism) from over 1.3million GEO records. We examined the quality of well supported rules from each algorithm and visualized the dependencies among metadata elements. Finally, we evaluated the performance of the algorithms in terms of accuracy, precision, recall, and F-measure. We found that PART is the best algorithm outperforming Apriori, Predictive Apriori, and Decision Table. All algorithms perform significantly better in predicting class values than the majority vote classifier. We found that the performance of the algorithms is related to the dimensionality of the GEO elements. The average performance of all algorithm increases due of the decreasing of dimensionality of the unique values of these elements (2697 platforms, 537 organisms, 454 labels, 9 molecules, and 5 types). Our work suggests that experimental metadata such as present in GEO can be accurately predicted using rule mining algorithms. Our work has implications for both prospective and retrospective augmentation of metadata quality, which are geared towards making data easier to find and reuse.
数据重用中的一个关键限制因素是缺乏对数据的准确、结构化和完整描述,即元数据。为了提高元数据的数量和质量,我们提出了一种新颖的元数据预测框架,以从现有元数据中学习关联,从而可用于预测元数据值。我们在来自基因表达综合数据库(GEO)的实验性元数据背景下评估了我们的框架。我们将四种规则挖掘算法应用于来自超过130万条GEO记录中最常见的结构化元数据元素(样本类型、分子类型、平台、标签类型和生物体)。我们检查了每种算法中得到充分支持的规则的质量,并直观展示了元数据元素之间的依赖性关系。最后,我们从准确性、精确性、召回率和F值方面评估了算法的性能。我们发现PART是优于Apriori、Predictive Apriori和决策表的最佳算法。所有算法在预测类别值方面的表现都明显优于多数投票分类器。我们发现算法的性能与GEO元素的维度有关。由于这些元素唯一值的维度降低(2697个平台、537个生物体、454个标签、9种分子和5种类型),所有算法的平均性能有所提高。我们的工作表明,使用规则挖掘算法可以准确预测GEO中存在的实验性元数据。我们的工作对前瞻性和回顾性提高元数据质量都有影响,这有助于使数据更易于查找和重用。