Eftimov Tome, Koroušić Seljak Barbara, Korošec Peter
Computer Systems Department, Jožef Stefan Institute, Ljubljana, Slovenia.
Jožef Stefan International Postgraduate School, Ljubljana, Slovenia.
PLoS One. 2017 Jun 23;12(6):e0179488. doi: 10.1371/journal.pone.0179488. eCollection 2017.
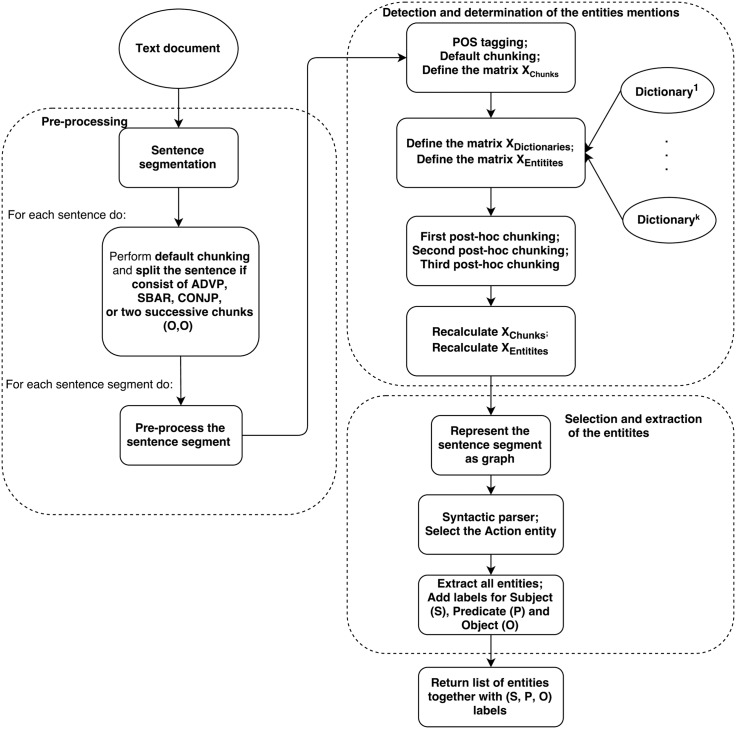
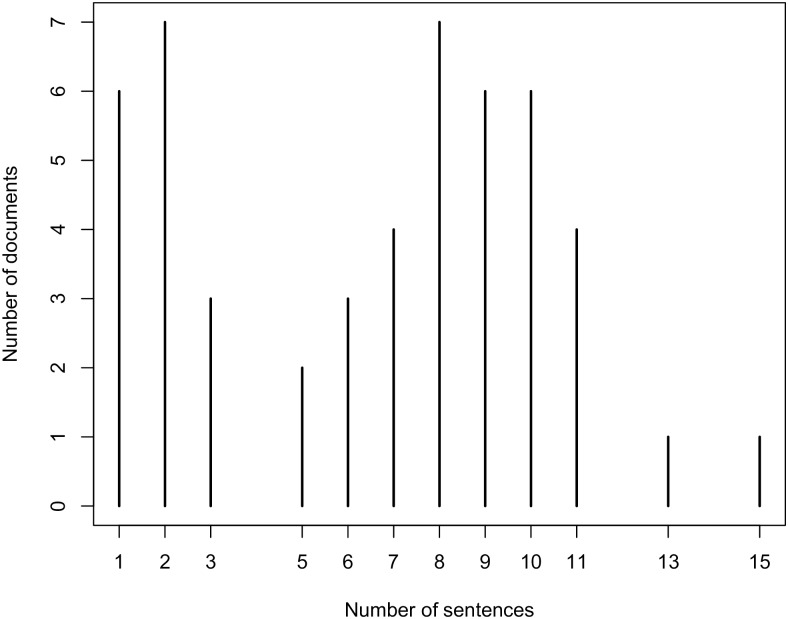
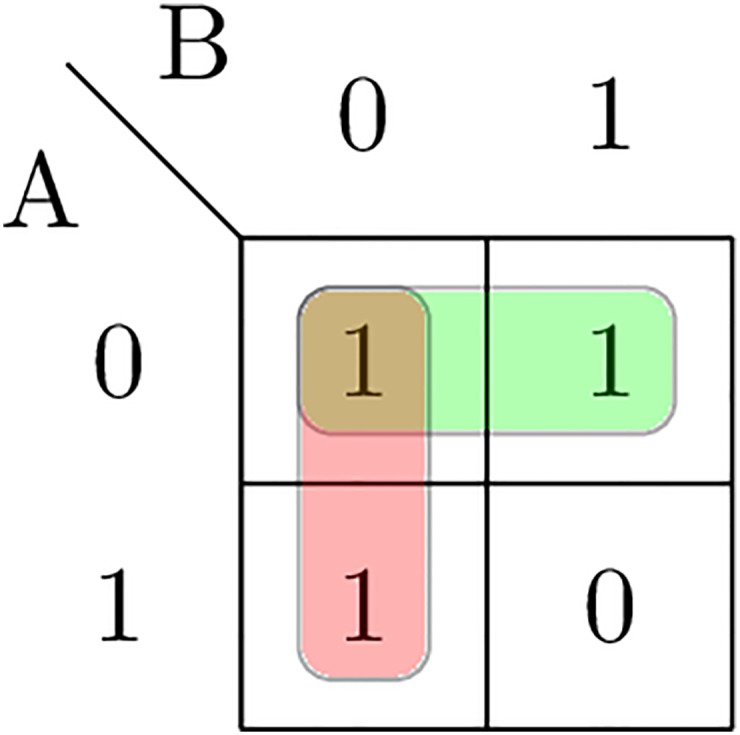
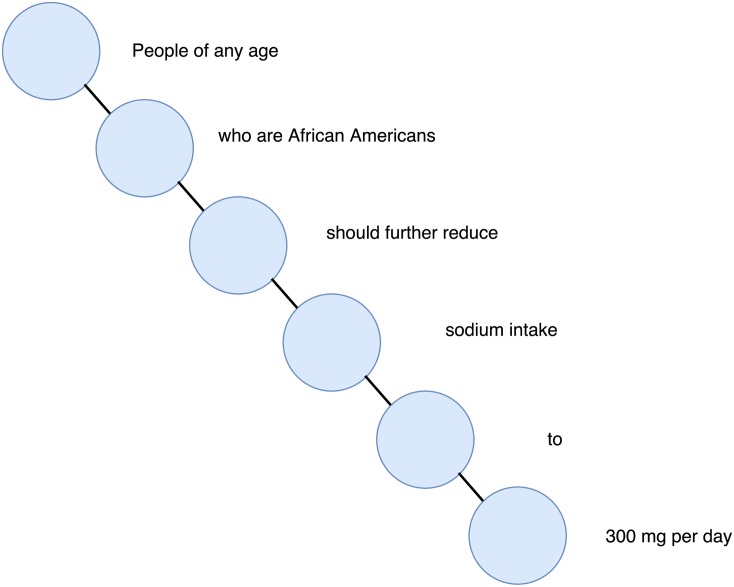
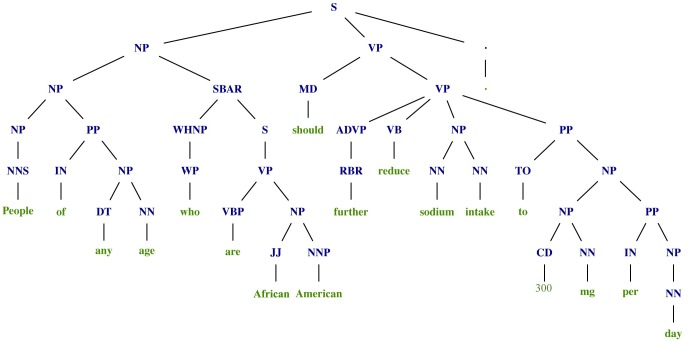
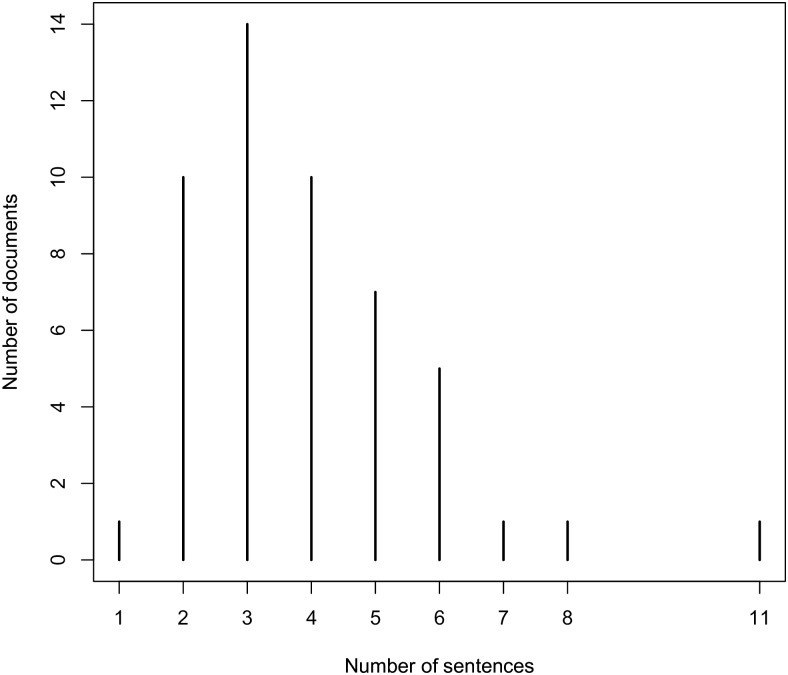
Evidence-based dietary information represented as unstructured text is a crucial information that needs to be accessed in order to help dietitians follow the new knowledge arrives daily with newly published scientific reports. Different named-entity recognition (NER) methods have been introduced previously to extract useful information from the biomedical literature. They are focused on, for example extracting gene mentions, proteins mentions, relationships between genes and proteins, chemical concepts and relationships between drugs and diseases. In this paper, we present a novel NER method, called drNER, for knowledge extraction of evidence-based dietary information. To the best of our knowledge this is the first attempt at extracting dietary concepts. DrNER is a rule-based NER that consists of two phases. The first one involves the detection and determination of the entities mention, and the second one involves the selection and extraction of the entities. We evaluate the method by using text corpora from heterogeneous sources, including text from several scientifically validated web sites and text from scientific publications. Evaluation of the method showed that drNER gives good results and can be used for knowledge extraction of evidence-based dietary recommendations.
以非结构化文本形式呈现的循证饮食信息是至关重要的信息,为帮助营养师跟上随着新发表的科学报告每日涌现的新知识,需要获取这些信息。此前已引入不同的命名实体识别(NER)方法,从生物医学文献中提取有用信息。例如,它们专注于提取基因提及、蛋白质提及、基因与蛋白质之间的关系、化学概念以及药物与疾病之间的关系。在本文中,我们提出了一种名为drNER的新型NER方法,用于循证饮食信息的知识提取。据我们所知,这是首次尝试提取饮食概念。DrNER是一种基于规则的NER,由两个阶段组成。第一个阶段涉及实体提及的检测和确定,第二个阶段涉及实体的选择和提取。我们通过使用来自异构源的文本语料库来评估该方法,这些源包括来自几个经过科学验证的网站的文本和科学出版物中的文本。对该方法的评估表明,drNER取得了良好的结果,可用于循证饮食建议的知识提取。