Paap Muirne C S, Kroeze Karel A, Terwee Caroline B, van der Palen Job, Veldkamp Bernard P
Department of Special Needs, Education, and Youth Care, Faculty of Behavioural and Social Sciences, University of Groningen, Grote Rozenstraat 38, 9712 TJ, Groningen, The Netherlands.
Centre for Educational Measurement at the University of Oslo (CEMO), Faculty of Educational Sciences, University of Oslo, Oslo, Norway.
Qual Life Res. 2017 Nov;26(11):2909-2918. doi: 10.1007/s11136-017-1624-3. Epub 2017 Jun 23.
Examining item usage is an important step in evaluating the performance of a computerized adaptive test (CAT). We study item usage for a newly developed multidimensional CAT which draws items from three PROMIS domains, as well as a disease-specific one.
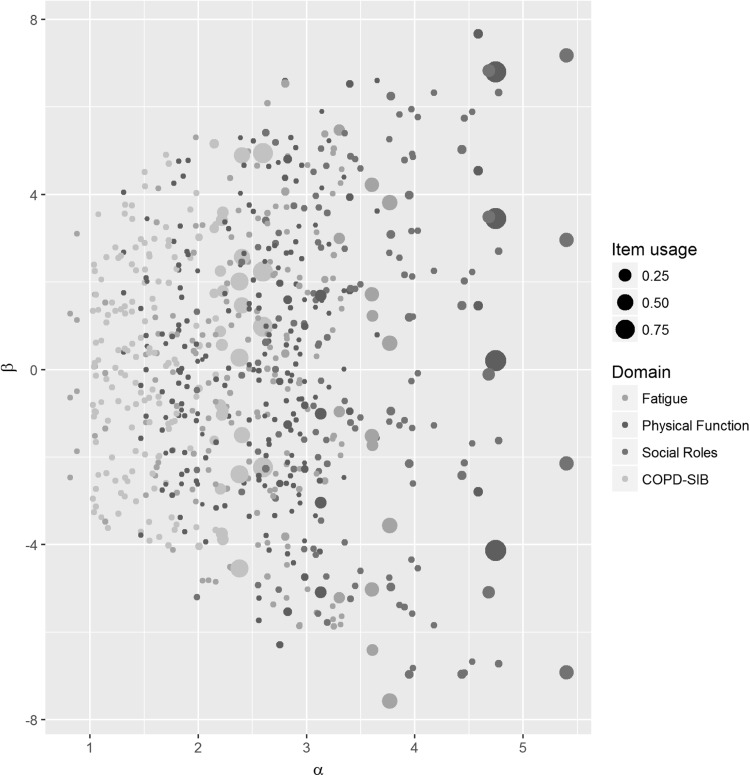
The multidimensional item bank used in the current study contained 194 items from four domains: the PROMIS domains fatigue, physical function, and ability to participate in social roles and activities, and a disease-specific domain (the COPD-SIB). The item bank was calibrated using the multidimensional graded response model and data of 795 patients with chronic obstructive pulmonary disease. To evaluate the item usage rates of all individual items in our item bank, CAT simulations were performed on responses generated based on a multivariate uniform distribution. The outcome variables included active bank size and item overuse (usage rate larger than the expected item usage rate).
For average θ-values, the overall active bank size was 9-10%; this number quickly increased as θ-values became more extreme. For values of -2 and +2, the overall active bank size equaled 39-40%. There was 78% overlap between overused items and active bank size for average θ-values. For more extreme θ-values, the overused items made up a much smaller part of the active bank size: here the overlap was only 35%.
Our results strengthen the claim that relatively short item banks may suffice when using polytomous items (and no content constraints/exposure control mechanisms), especially when using MCAT.
检查试题使用情况是评估计算机自适应测试(CAT)性能的重要一步。我们研究了一种新开发的多维CAT的试题使用情况,该测试从三个PROMIS领域以及一个疾病特定领域选取试题。
本研究中使用的多维试题库包含来自四个领域的194道试题:PROMIS领域中的疲劳、身体功能、参与社会角色和活动的能力,以及一个疾病特定领域(慢性阻塞性肺疾病自我效能量表,COPD-SIB)。使用多维分级反应模型和795例慢性阻塞性肺疾病患者的数据对试题库进行校准。为了评估我们试题库中所有单个试题的使用率,对基于多元均匀分布生成的回答进行了CAT模拟。结果变量包括有效题库规模和试题过度使用情况(使用率大于预期试题使用率)。
对于平均θ值,总体有效题库规模为9%-10%;随着θ值变得更加极端,这个数字迅速增加。对于-2和+2的值,总体有效题库规模等于39%-40%。对于平均θ值,过度使用的试题与有效题库规模之间的重叠率为78%。对于更极端的θ值,过度使用的试题在有效题库规模中所占比例要小得多:这里的重叠率仅为35%。
我们的结果进一步证明,在使用多分类试题(且没有内容限制/曝光控制机制)时,尤其是使用MCAT时,相对较短的试题库可能就足够了。