Zhu Yongjun, Yan Erjia, Wang Fei
Healthcare Policy and Research, Weill Cornell Medicine, Cornell University, New York, NY, USA.
College of Computing and Informatics, Drexel University, Philadelphia, PA, USA.
BMC Med Inform Decis Mak. 2017 Jul 3;17(1):95. doi: 10.1186/s12911-017-0498-1.
Understanding semantic relatedness and similarity between biomedical terms has a great impact on a variety of applications such as biomedical information retrieval, information extraction, and recommender systems. The objective of this study is to examine word2vec's ability in deriving semantic relatedness and similarity between biomedical terms from large publication data. Specifically, we focus on the effects of recency, size, and section of biomedical publication data on the performance of word2vec.
We download abstracts of 18,777,129 articles from PubMed and 766,326 full-text articles from PubMed Central (PMC). The datasets are preprocessed and grouped into subsets by recency, size, and section. Word2vec models are trained on these subtests. Cosine similarities between biomedical terms obtained from the word2vec models are compared against reference standards. Performance of models trained on different subsets are compared to examine recency, size, and section effects.
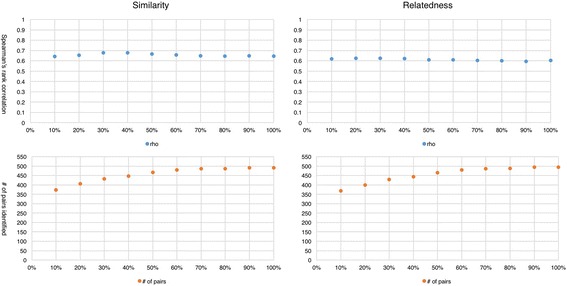
Models trained on recent datasets did not boost the performance. Models trained on larger datasets identified more pairs of biomedical terms than models trained on smaller datasets in relatedness task (from 368 at the 10% level to 494 at the 100% level) and similarity task (from 374 at the 10% level to 491 at the 100% level). The model trained on abstracts produced results that have higher correlations with the reference standards than the one trained on article bodies (i.e., 0.65 vs. 0.62 in the similarity task and 0.66 vs. 0.59 in the relatedness task). However, the latter identified more pairs of biomedical terms than the former (i.e., 344 vs. 498 in the similarity task and 339 vs. 503 in the relatedness task).
Increasing the size of dataset does not always enhance the performance. Increasing the size of datasets can result in the identification of more relations of biomedical terms even though it does not guarantee better precision. As summaries of research articles, compared with article bodies, abstracts excel in accuracy but lose in coverage of identifiable relations.
理解生物医学术语之间的语义相关性和相似性对生物医学信息检索、信息提取和推荐系统等多种应用有很大影响。本研究的目的是检验word2vec从大量出版物数据中推导生物医学术语之间语义相关性和相似性的能力。具体而言,我们关注生物医学出版物数据的时效性、规模和部分对word2vec性能的影响。
我们从PubMed下载了18,777,129篇文章的摘要,并从PubMed Central(PMC)下载了766,326篇全文文章。对数据集进行预处理,并按时效性、规模和部分进行分组。在这些子测试上训练word2vec模型。将从word2vec模型获得的生物医学术语之间的余弦相似度与参考标准进行比较。比较在不同子集上训练的模型的性能,以检验时效性、规模和部分的影响。
在近期数据集上训练的模型并没有提高性能。在相关性任务(从10%水平的368对到100%水平的494对)和相似性任务(从10%水平的374对到100%水平的491对)中,在较大数据集上训练的模型比在较小数据集上训练的模型识别出更多的生物医学术语对。在摘要上训练的模型产生的结果与参考标准的相关性高于在文章主体上训练的模型(即相似性任务中为0.65对0.62,相关性任务中为0.66对0.59)。然而,后者识别出的生物医学术语对比前者多(即相似性任务中为344对498对,相关性任务中为339对503对)。
增加数据集的规模并不总是能提高性能。增加数据集的规模可以导致识别出更多的生物医学术语关系,即使这并不能保证更高的精度。作为研究文章的摘要,与文章主体相比,摘要在准确性方面表现出色,但在可识别关系的覆盖范围方面有所欠缺。