Chair of Systems Design, ETH Zurich, Weinbergstrasse 56/58, 8092 Zurich, Switzerland. Email:
Sci Adv. 2017 Aug 4;3(8):e1701172. doi: 10.1126/sciadv.1701172. eCollection 2017 Aug.
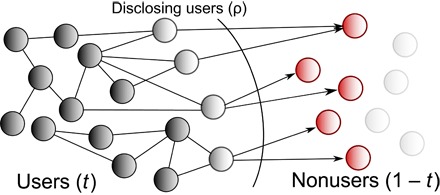
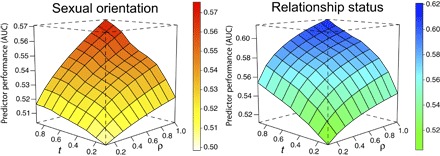
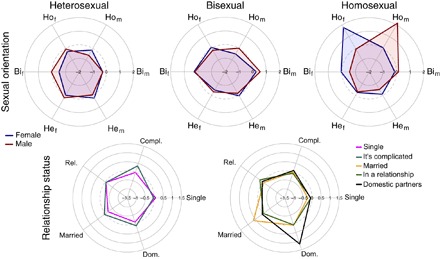
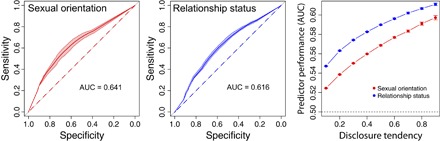
Social interaction and data integration in the digital society can affect the control that individuals have on their privacy. Social networking sites can access data from other services, including user contact lists where nonusers are listed too. Although most research on online privacy has focused on inference of personal information of users, this data integration poses the question of whether it is possible to predict personal information of nonusers. This article tests the shadow profile hypothesis, which postulates that the data given by the users of an online service predict personal information of nonusers. Using data from a disappeared social networking site, we perform a historical audit to evaluate whether personal data of nonusers could have been predicted with the personal data and contact lists shared by the users of the site. We analyze personal information of sexual orientation and relationship status, which follow regular mixing patterns in the social network. Going back in time over the growth of the network, we measure predictor performance as a function of network size and tendency of users to disclose their contact lists. This article presents robust evidence supporting the shadow profile hypothesis and reveals a multiplicative effect of network size and disclosure tendencies that accelerates the performance of predictors. These results call for new privacy paradigms that take into account the fact that individual privacy decisions do not happen in isolation and are mediated by the decisions of others.
在数字社会中,社交互动和数据集成可能会影响个人对隐私的控制。社交网站可以访问来自其他服务的数据,包括列出非用户的用户联系人列表。尽管大多数关于在线隐私的研究都集中在推断用户的个人信息上,但这种数据集成提出了一个问题,即是否可以预测非用户的个人信息。本文检验了影子档案假设,该假设认为,在线服务用户提供的数据可以预测非用户的个人信息。我们使用已消失的社交网站的数据进行历史审计,以评估是否可以使用该网站用户共享的个人数据和联系人列表来预测非用户的个人数据。我们分析了性取向和关系状态等个人信息,这些信息遵循社交网络中的常规混合模式。我们回溯网络的增长过程,根据网络规模和用户披露联系人列表的倾向,衡量预测器的性能。本文提供了有力的证据支持影子档案假设,并揭示了网络规模和披露倾向的相乘效应,这加速了预测器的性能。这些结果呼吁采用新的隐私范式,考虑到这样一个事实,即个人隐私决策不是孤立发生的,而是受到他人决策的影响。