Department of Biochemistry and Biophysics, University of North Carolina at Chapel Hill, Chapel Hill, NC, 27599-7260, USA.
Adv Exp Med Biol. 2017;966:103-148. doi: 10.1007/5584_2017_93.
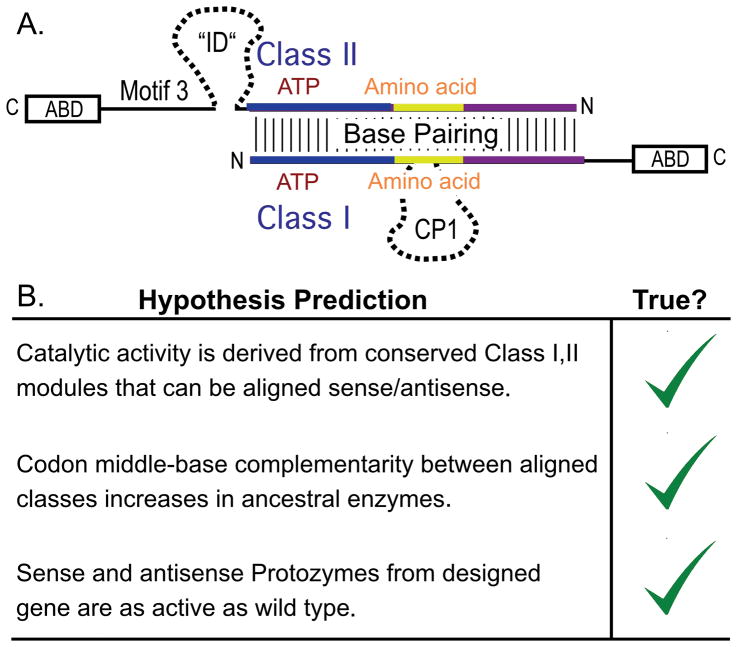
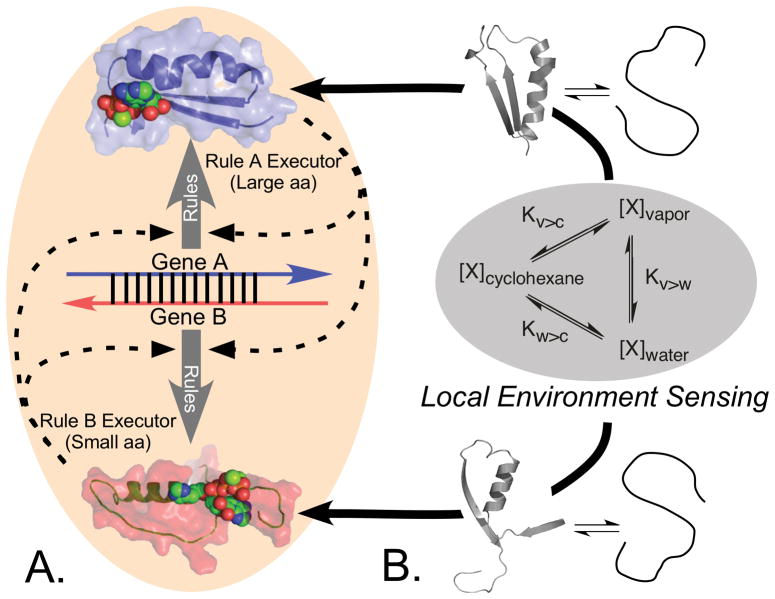
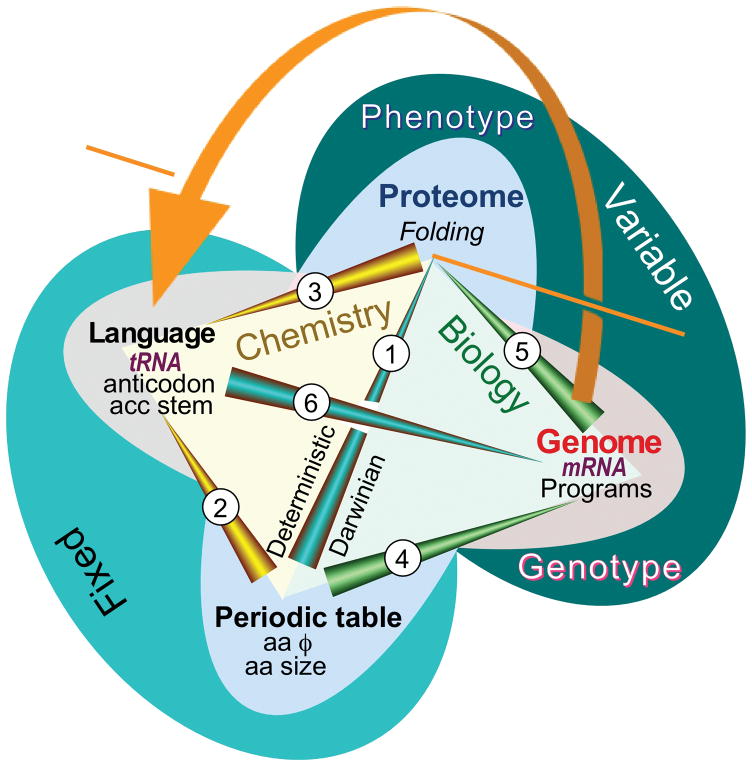
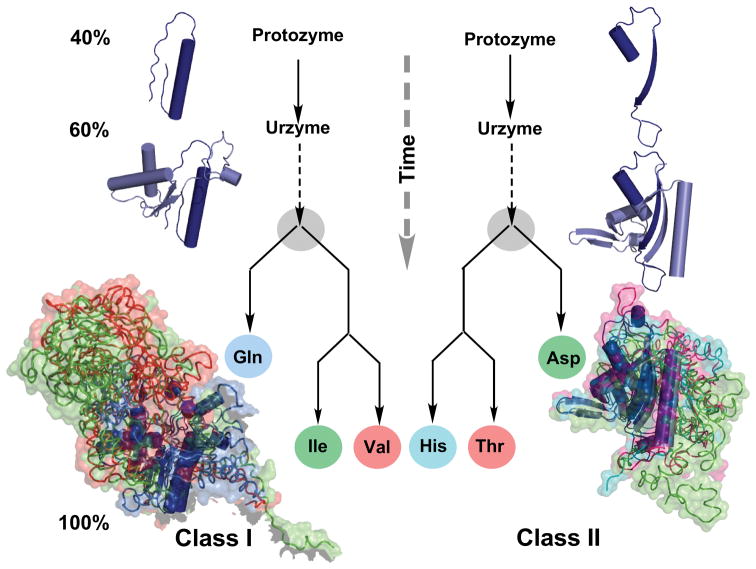
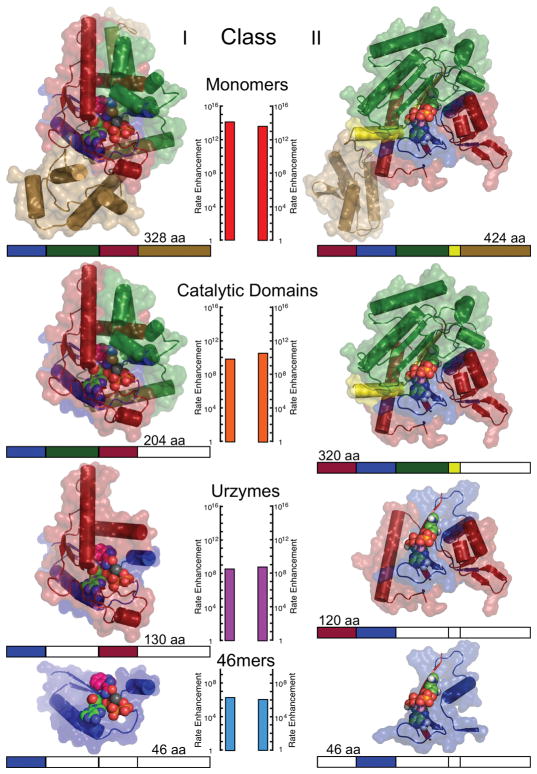
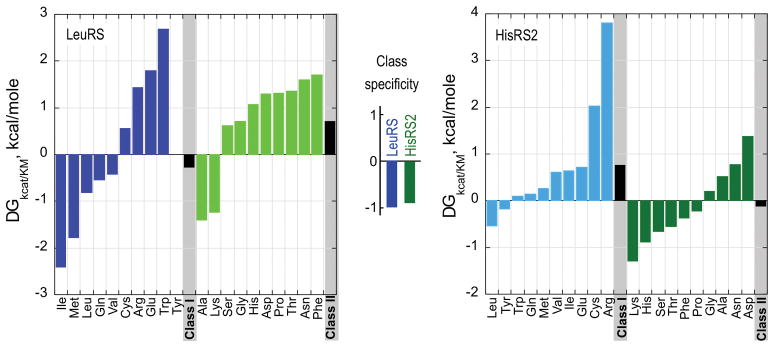
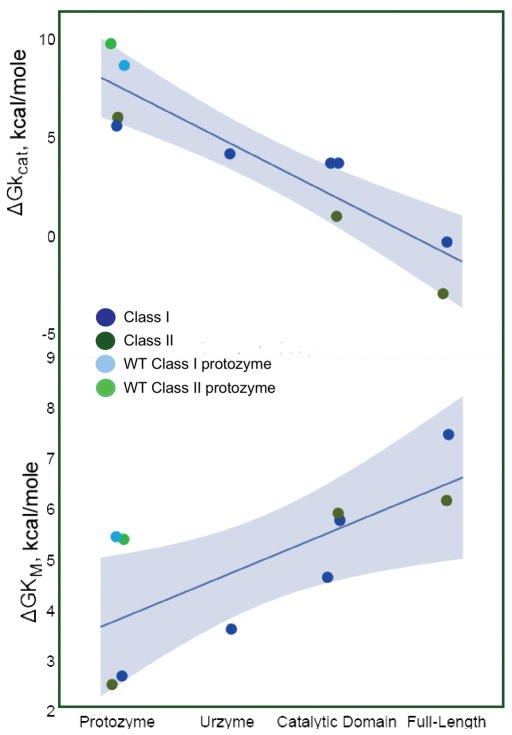
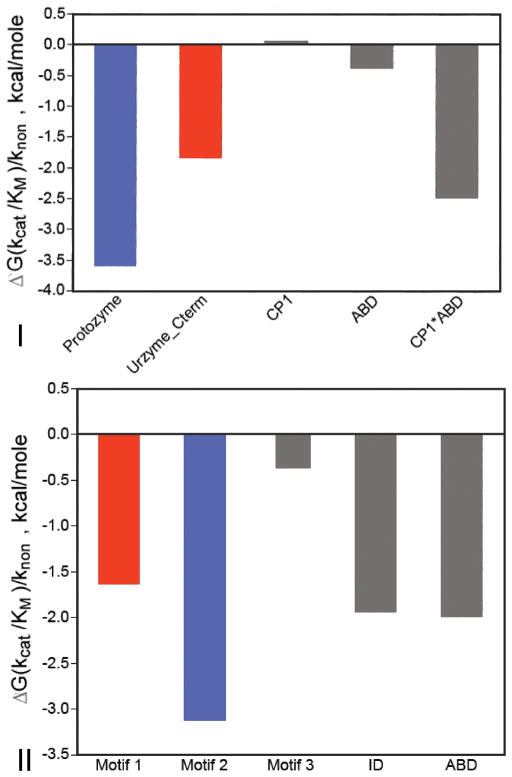
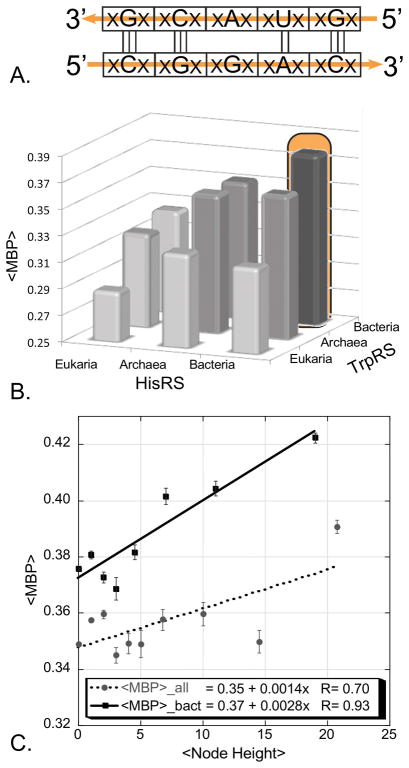
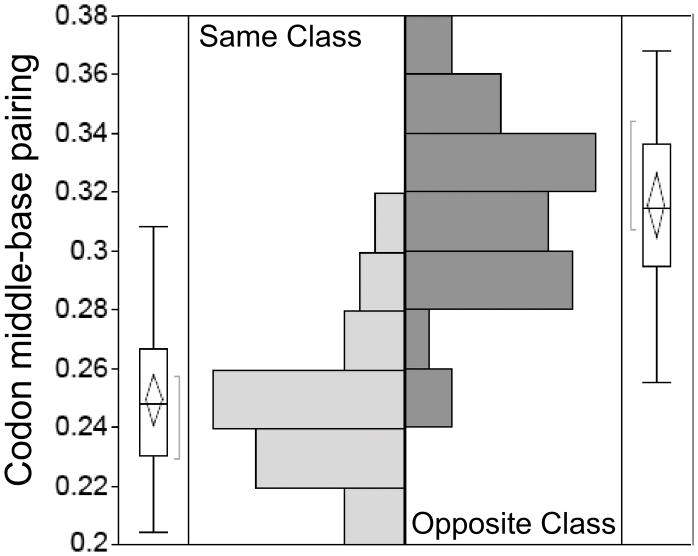
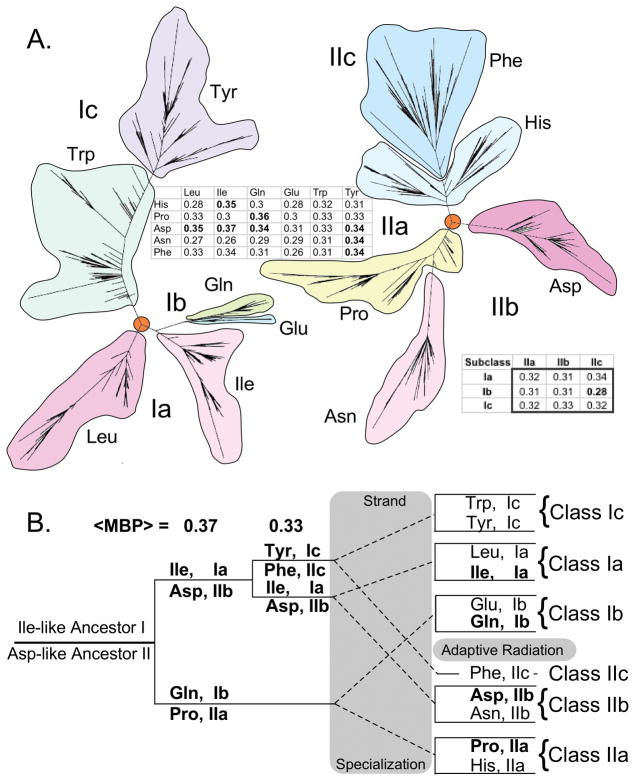
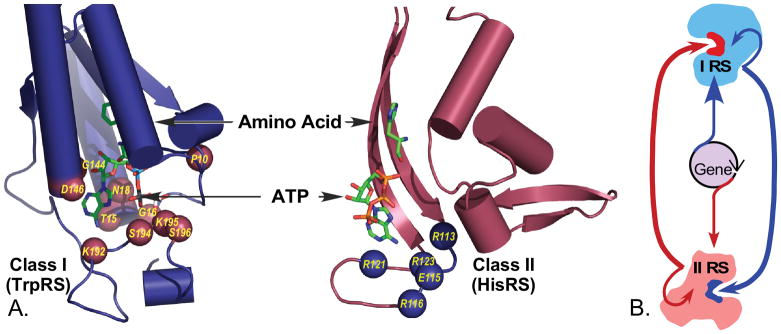
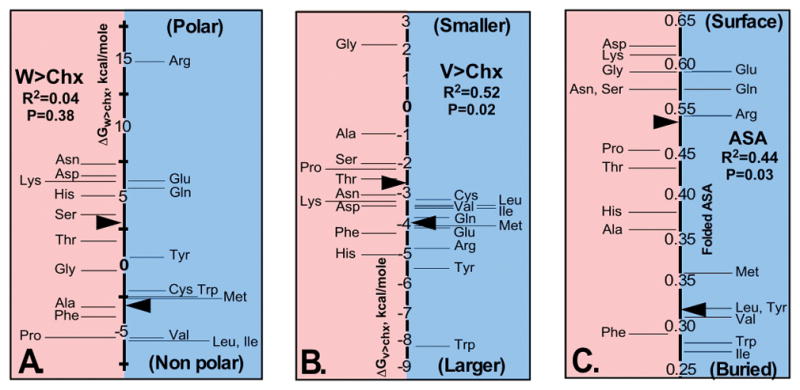
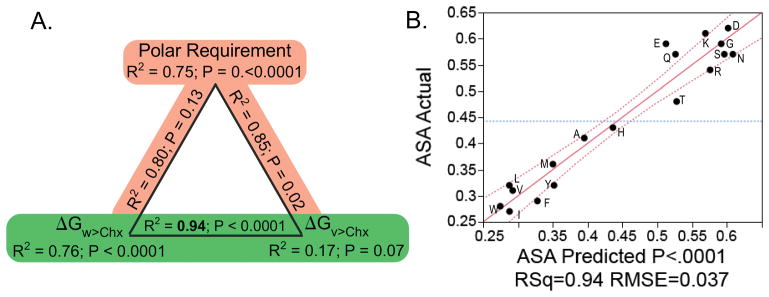
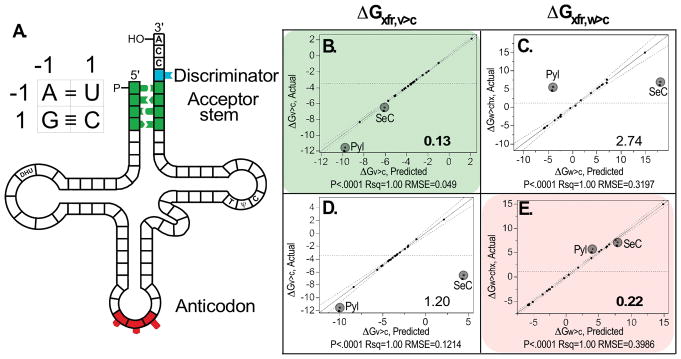
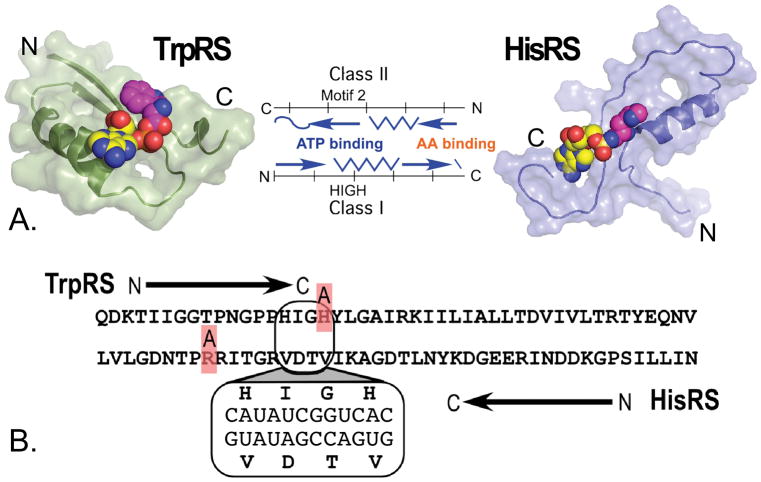
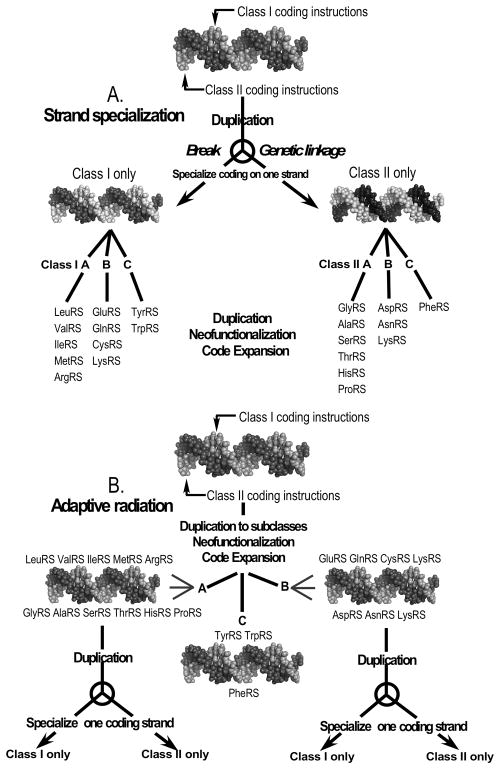
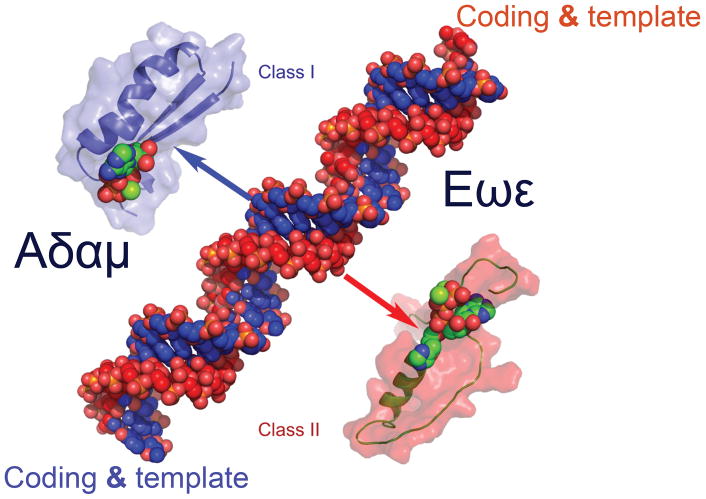
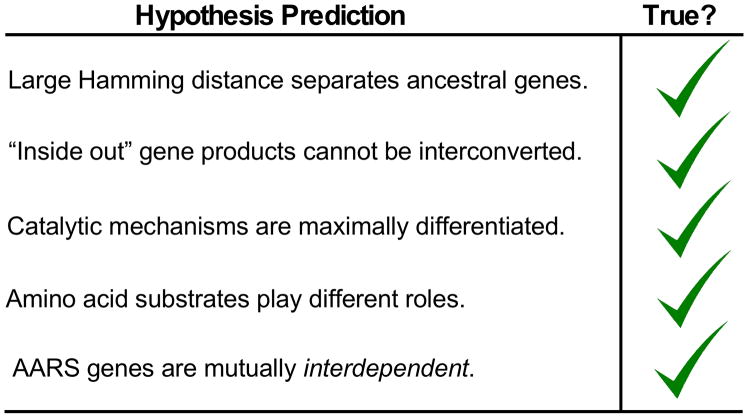
The aminoacyl-tRNA synthetases and their cognate transfer RNAs translate the universal genetic code. The twenty canonical amino acids are sufficiently diverse to create a selective advantage for dividing amino acid activation between two distinct, apparently unrelated superfamilies of synthetases, Class I amino acids being generally larger and less polar, Class II amino acids smaller and more polar. Biochemical, bioinformatic, and protein engineering experiments support the hypothesis that the two Classes descended from opposite strands of the same ancestral gene. Parallel experimental deconstructions of Class I and II synthetases reveal parallel losses in catalytic proficiency at two novel modular levels-protozymes and Urzymes-associated with the evolution of catalytic activity. Bi-directional coding supports an important unification of the proteome; affords a genetic relatedness metric-middle base-pairing frequencies in sense/antisense alignments-that probes more deeply into the evolutionary history of translation than do single multiple sequence alignments; and has facilitated the analysis of hitherto unknown coding relationships in tRNA sequences. Reconstruction of native synthetases by modular thermodynamic cycles facilitated by domain engineering emphasizes the subtlety associated with achieving high specificity, shedding new light on allosteric relationships in contemporary synthetases. Synthetase Urzyme structural biology suggests that they are catalytically-active molten globules, broadening the potential manifold of polypeptide catalysts accessible to primitive genetic coding and motivating revisions of the origins of catalysis. Finally, bi-directional genetic coding of some of the oldest genes in the proteome places major limitations on the likelihood that any RNA World preceded the origins of coded proteins.
氨酰-tRNA 合成酶及其对应的转移 RNA 将通用遗传密码翻译成蛋白质。二十种标准氨基酸具有足够的多样性,可以在两个截然不同的、显然不相关的合成酶超家族之间分配氨基酸激活,这为它们提供了选择性优势。I 类氨基酸通常较大且非极性,II 类氨基酸较小且极性更强。生化、生物信息学和蛋白质工程实验支持这样的假设:这两个类别是从同一祖先基因的相反链衍生而来的。对 I 类和 II 类合成酶的平行实验解构揭示了在两个新的模块化水平上催化效率的平行丧失——与催化活性进化相关的原始酶和 Urzymes。双向编码为蛋白质组提供了重要的统一;提供了遗传相关性度量——在有意义/反义对齐中的中间碱基对频率,比单个多重序列比对更深入地探测翻译的进化历史;并促进了对 tRNA 序列中未知编码关系的分析。通过域工程实现的模块化热力学循环重建天然合成酶强调了实现高特异性所涉及的微妙性,为当代合成酶中的变构关系提供了新的认识。合成酶 Urzymes 的结构生物学表明,它们是具有催化活性的熔融球蛋白,拓宽了原始遗传编码可获得的多肽催化剂的潜在范围,并激发了对催化起源的修订。最后,蛋白质组中一些最古老基因的双向遗传编码对 RNA 世界先于编码蛋白质起源的可能性施加了重大限制。