Thaler Lore, Reich Galen M, Zhang Xinyu, Wang Dinghe, Smith Graeme E, Tao Zeng, Abdullah Raja Syamsul Azmir Bin Raja, Cherniakov Mikhail, Baker Christopher J, Kish Daniel, Antoniou Michail
Department of Psychology, Durham University, Science Site, Durham, United Kingdom.
Department of Electronic Electrical and Systems Engineering, School of Engineering, University of Birmingham, Edgbaston, Birmingham, United Kingdom.
PLoS Comput Biol. 2017 Aug 31;13(8):e1005670. doi: 10.1371/journal.pcbi.1005670. eCollection 2017 Aug.
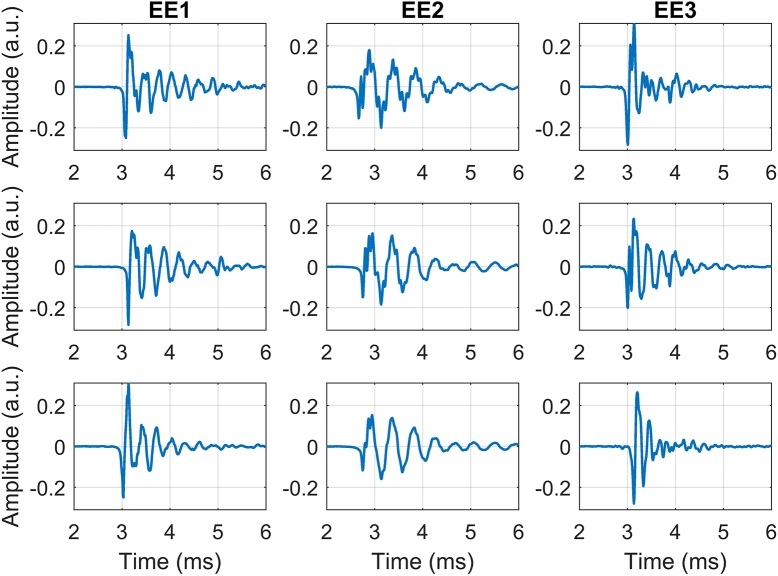
Echolocation is the ability to use sound-echoes to infer spatial information about the environment. Some blind people have developed extraordinary proficiency in echolocation using mouth-clicks. The first step of human biosonar is the transmission (mouth click) and subsequent reception of the resultant sound through the ear. Existing head-related transfer function (HRTF) data bases provide descriptions of reception of the resultant sound. For the current report, we collected a large database of click emissions with three blind people expertly trained in echolocation, which allowed us to perform unprecedented analyses. Specifically, the current report provides the first ever description of the spatial distribution (i.e. beam pattern) of human expert echolocation transmissions, as well as spectro-temporal descriptions at a level of detail not available before. Our data show that transmission levels are fairly constant within a 60° cone emanating from the mouth, but levels drop gradually at further angles, more than for speech. In terms of spectro-temporal features, our data show that emissions are consistently very brief (~3ms duration) with peak frequencies 2-4kHz, but with energy also at 10kHz. This differs from previous reports of durations 3-15ms and peak frequencies 2-8kHz, which were based on less detailed measurements. Based on our measurements we propose to model transmissions as sum of monotones modulated by a decaying exponential, with angular attenuation by a modified cardioid. We provide model parameters for each echolocator. These results are a step towards developing computational models of human biosonar. For example, in bats, spatial and spectro-temporal features of emissions have been used to derive and test model based hypotheses about behaviour. The data we present here suggest similar research opportunities within the context of human echolocation. Relatedly, the data are a basis to develop synthetic models of human echolocation that could be virtual (i.e. simulated) or real (i.e. loudspeaker, microphones), and which will help understanding the link between physical principles and human behaviour.
回声定位是一种利用声音回声来推断周围环境空间信息的能力。一些盲人通过发出口腔咔哒声在回声定位方面发展出了非凡的技能。人类生物声纳的第一步是发出声音(口腔咔哒声),随后通过耳朵接收产生的声音。现有的头部相关传递函数(HRTF)数据库描述了对产生的声音的接收情况。在本报告中,我们收集了一个大型的口腔咔哒声发射数据库,该数据库来自三位经过回声定位专业训练的盲人,这使我们能够进行前所未有的分析。具体而言,本报告首次描述了人类专家回声定位发射的空间分布(即波束模式),以及前所未有的详细程度的频谱 - 时间描述。我们的数据表明,在从口腔发出的60°圆锥范围内,发射水平相当恒定,但在更大角度时水平会逐渐下降,下降程度比语音更大。在频谱 - 时间特征方面,我们的数据表明发射持续时间始终非常短暂(约3毫秒),峰值频率在2 - 4千赫兹,但在10千赫兹处也有能量。这与之前基于不太详细测量的持续时间为3 - 15毫秒、峰值频率为2 - 8千赫兹的报告不同。基于我们的测量,我们建议将发射建模为一个由衰减指数调制的单调函数之和,并通过修正的心形函数进行角度衰减。我们为每个回声定位者提供了模型参数。这些结果是朝着开发人类生物声纳计算模型迈出的一步。例如,在蝙蝠中,发射的空间和频谱 - 时间特征已被用于推导和测试基于模型的行为假设。我们在此展示的数据表明在人类回声定位背景下存在类似的研究机会。相关地,这些数据是开发人类回声定位合成模型的基础,该模型可以是虚拟的(即模拟的)或真实的(即扬声器、麦克风),这将有助于理解物理原理与人类行为之间的联系。