Sogancioglu Gizem, Öztürk Hakime, Özgür Arzucan
Department of Computer Engineering, Bogazici University, Istanbul, Turkey.
R&D and Special Projects Department, Yapı Kredi Technology, Istanbul, Turkey.
Bioinformatics. 2017 Jul 15;33(14):i49-i58. doi: 10.1093/bioinformatics/btx238.
The amount of information available in textual format is rapidly increasing in the biomedical domain. Therefore, natural language processing (NLP) applications are becoming increasingly important to facilitate the retrieval and analysis of these data. Computing the semantic similarity between sentences is an important component in many NLP tasks including text retrieval and summarization. A number of approaches have been proposed for semantic sentence similarity estimation for generic English. However, our experiments showed that such approaches do not effectively cover biomedical knowledge and produce poor results for biomedical text.
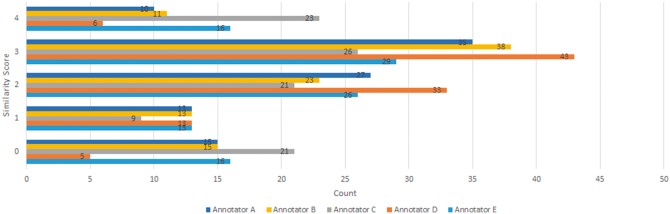
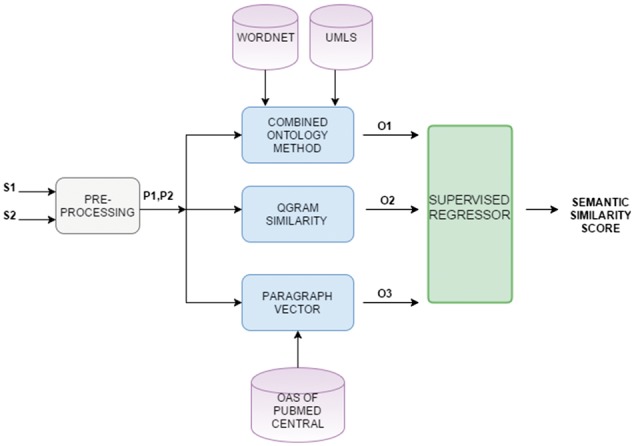
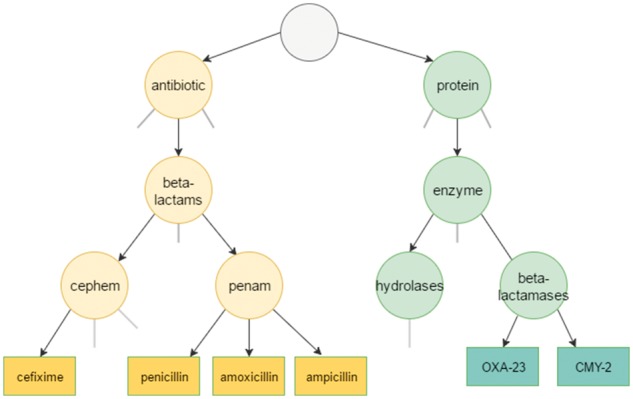
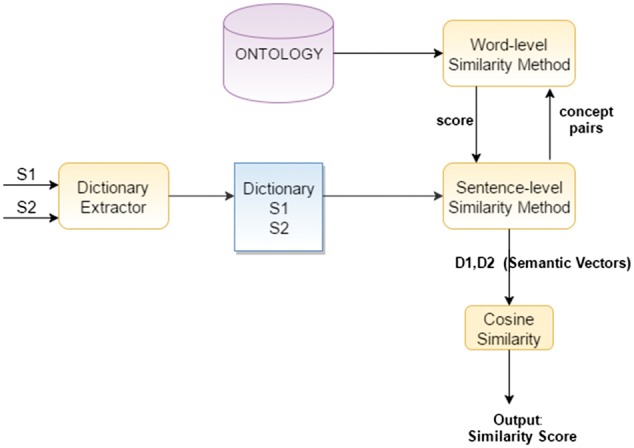
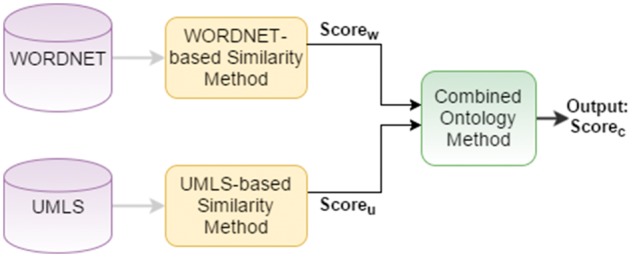
We propose several approaches for sentence-level semantic similarity computation in the biomedical domain, including string similarity measures and measures based on the distributed vector representations of sentences learned in an unsupervised manner from a large biomedical corpus. In addition, ontology-based approaches are presented that utilize general and domain-specific ontologies. Finally, a supervised regression based model is developed that effectively combines the different similarity computation metrics. A benchmark data set consisting of 100 sentence pairs from the biomedical literature is manually annotated by five human experts and used for evaluating the proposed methods.
The experiments showed that the supervised semantic sentence similarity computation approach obtained the best performance (0.836 correlation with gold standard human annotations) and improved over the state-of-the-art domain-independent systems up to 42.6% in terms of the Pearson correlation metric.
A web-based system for biomedical semantic sentence similarity computation, the source code, and the annotated benchmark data set are available at: http://tabilab.cmpe.boun.edu.tr/BIOSSES/ .
生物医学领域中以文本格式存在的信息量正在迅速增长。因此,自然语言处理(NLP)应用对于促进这些数据的检索和分析变得越来越重要。计算句子之间的语义相似度是许多NLP任务(包括文本检索和摘要)中的一个重要组成部分。已经提出了许多方法来估计通用英语的语义句子相似度。然而,我们的实验表明,这些方法不能有效地涵盖生物医学知识,并且对于生物医学文本会产生较差的结果。
我们提出了几种用于生物医学领域句子级语义相似度计算的方法,包括字符串相似度度量和基于从大型生物医学语料库中无监督学习得到的句子分布式向量表示的度量。此外,还提出了基于本体的方法,这些方法利用了通用和特定领域的本体。最后,开发了一种基于监督回归的模型,该模型有效地结合了不同的相似度计算指标。一个由来自生物医学文献的100个句子对组成的基准数据集由五名人类专家进行人工标注,并用于评估所提出的方法。
实验表明,监督语义句子相似度计算方法获得了最佳性能(与黄金标准人工标注的相关性为0.836),并且在皮尔逊相关度量方面比最先进的独立于领域的系统提高了42.6%。
用于生物医学语义句子相似度计算的基于网络的系统、源代码和带注释的基准数据集可在以下网址获得:http://tabilab.cmpe.boun.edu.tr/BIOSSES/ 。