Djokic-Petrovic Marija, Cvjetkovic Vladimir, Yang Jeremy, Zivanovic Marko, Wild David J
Virtual World Services GmbH, Asperner Heldenplatz 6, 1220, Wien, Austria.
Department of Mathematics and Informatics, Faculty of Science, University of Kragujevac, Radoja Domanovica 12, Kragujevac, 34000, Serbia.
J Biomed Semantics. 2017 Sep 20;8(1):42. doi: 10.1186/s13326-017-0151-z.
There are a huge variety of data sources relevant to chemical, biological and pharmacological research, but these data sources are highly siloed and cannot be queried together in a straightforward way. Semantic technologies offer the ability to create links and mappings across datasets and manage them as a single, linked network so that searching can be carried out across datasets, independently of the source. We have developed an application called PIBAS FedSPARQL that uses semantic technologies to allow researchers to carry out such searching across a vast array of data sources.
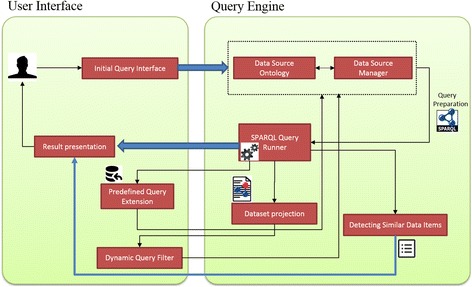
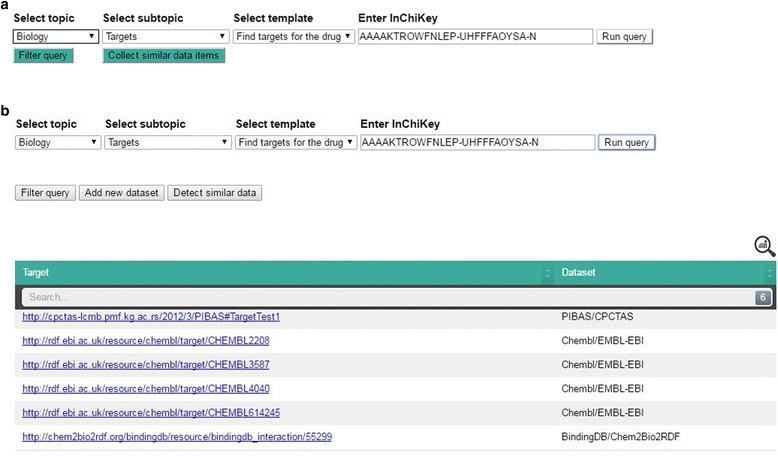
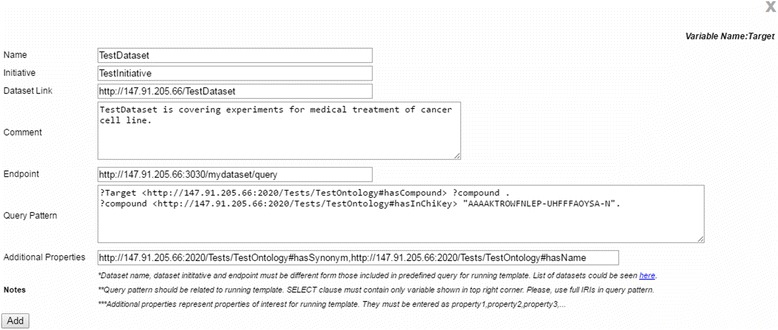
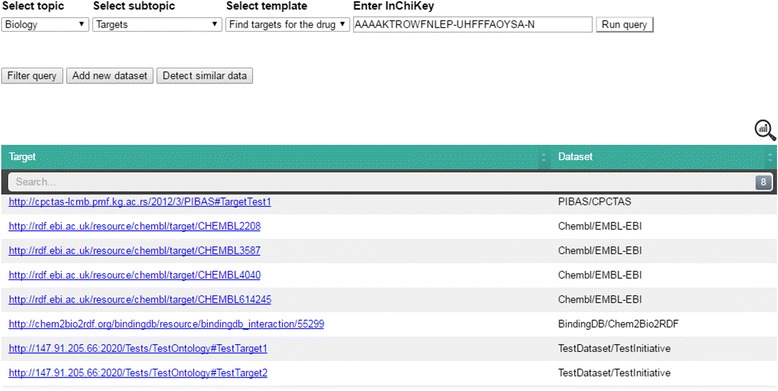
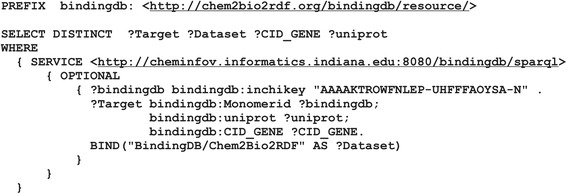
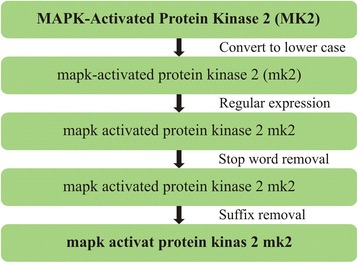
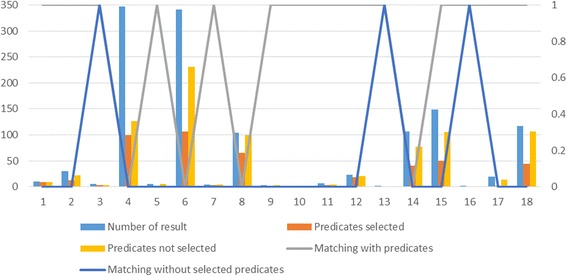
PIBAS FedSPARQL is a web-based query builder and result set visualizer of bioinformatics data. As an advanced feature, our system can detect similar data items identified by different Uniform Resource Identifiers (URIs), using a text-mining algorithm based on the processing of named entities to be used in Vector Space Model and Cosine Similarity Measures. According to our knowledge, PIBAS FedSPARQL was unique among the systems that we found in that it allows detecting of similar data items. As a query builder, our system allows researchers to intuitively construct and run Federated SPARQL queries across multiple data sources, including global initiatives, such as Bio2RDF, Chem2Bio2RDF, EMBL-EBI, and one local initiative called CPCTAS, as well as additional user-specified data source. From the input topic, subtopic, template and keyword, a corresponding initial Federated SPARQL query is created and executed. Based on the data obtained, end users have the ability to choose the most appropriate data sources in their area of interest and exploit their Resource Description Framework (RDF) structure, which allows users to select certain properties of data to enhance query results.
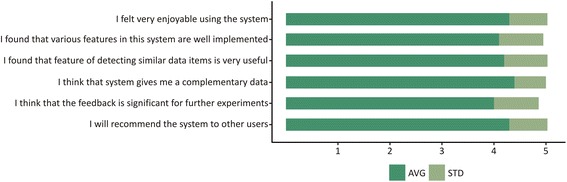
The developed system is flexible and allows intuitive creation and execution of queries for an extensive range of bioinformatics topics. Also, the novel "similar data items detection" algorithm can be particularly useful for suggesting new data sources and cost optimization for new experiments. PIBAS FedSPARQL can be expanded with new topics, subtopics and templates on demand, rendering information retrieval more robust.
与化学、生物学和药理学研究相关的数据来源种类繁多,但这些数据来源高度分散,无法直接一起查询。语义技术提供了跨数据集创建链接和映射并将它们作为单个链接网络进行管理的能力,以便可以独立于数据源跨数据集进行搜索。我们开发了一个名为PIBAS FedSPARQL的应用程序,它使用语义技术使研究人员能够跨大量数据源进行此类搜索。
PIBAS FedSPARQL是一个基于网络的生物信息学数据查询构建器和结果集可视化工具。作为一项高级功能,我们的系统可以使用基于命名实体处理的文本挖掘算法来检测由不同统一资源标识符(URI)标识的相似数据项,该算法将用于向量空间模型和余弦相似性度量。据我们所知,PIBAS FedSPARQL在我们找到的系统中是独一无二的,因为它允许检测相似数据项。作为一个查询构建器,我们的系统允许研究人员直观地构建和运行跨多个数据源的联邦SPARQL查询,包括全球倡议,如Bio2RDF、Chem2Bio2RDF、EMBL-EBI,以及一个名为CPCTAS的本地倡议,以及其他用户指定的数据源。根据输入的主题、子主题、模板和关键词,创建并执行相应的初始联邦SPARQL查询。基于获得的数据,最终用户能够在其感兴趣的领域中选择最合适的数据源,并利用其资源描述框架(RDF)结构,这允许用户选择数据的某些属性以增强查询结果。
所开发的系统很灵活,允许为广泛的生物信息学主题直观地创建和执行查询。此外,新颖的“相似数据项检测”算法对于建议新的数据来源和优化新实验的成本可能特别有用。PIBAS FedSPARQL可以根据需要使用新的主题、子主题和模板进行扩展,使信息检索更加强大。