Pranaat Robert, Mohan Vishnu, O'Reilly Megan, Hirsh Maxwell, McGrath Karess, Scholl Gretchen, Woodcock Deborah, Gold Jeffrey A
Medical Informatics, Oregon Health & Sciences University, Portland, OR, United States.
Obstetrics and Gynecology, Oregon Health & Sciences University, Portland, OR, United States.
JMIR Med Inform. 2017 Sep 20;5(3):e30. doi: 10.2196/medinform.7883.
The increasing adoption of electronic health records (EHRs) has been associated with a number of unintended negative consequences with provider efficiency and job satisfaction. To address this, there has been a dramatic increase in the use of medical scribes to perform many of the required EHR functions. Despite this rapid growth, little has been published on the training or assessment tools to appraise the safety and efficacy of scribe-related EHR activities. Given the number of reports documenting that other professional groups suffer from a number of performance errors in EHR interface and data gathering, scribes likely face similar challenges. This highlights the need for new assessment tools for medical scribes.
The objective of this study was to develop a virtual video-based simulation to demonstrate and quantify the variability and accuracy of scribes' transcribed notes in the EHR.
From a pool of 8 scribes in one department, a total of 5 female scribes, intent on pursuing careers in health care, with at least 6 months of experience were recruited for our simulation study. We created three simulated patient-provider scenarios. Each scenario contained a corresponding medical record in our simulation instance of our EHR. For each scenario, we video-recorded a standardized patient-provider encounter. Five scribes with at least 6 months of experience both with our EHR and in the specialty of the simulated cases were recruited. Each scribe watched the simulated encounter and transcribed notes into a simulated EHR environment. Transcribed notes were evaluated for interscribe variability and compared with a gold standard for accuracy.
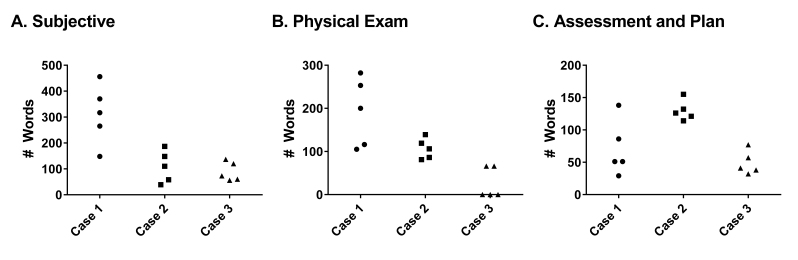
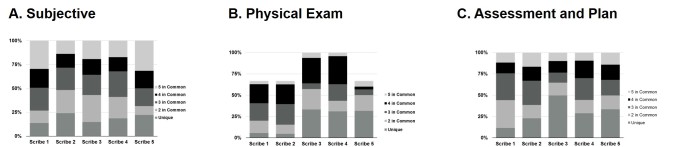
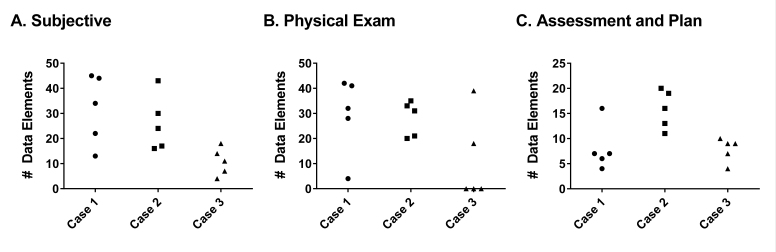
All scribes completed all simulated cases. There was significant interscribe variability in note structure and content. Overall, only 26% of all data elements were unique to the scribe writing them. The term data element was used to define the individual pieces of data that scribes perceived from the simulation. Note length was determined by counting the number of words varied by 31%, 37%, and 57% between longest and shortest note between the three cases, and word economy ranged between 23% and 71%. Overall, there was a wide inter- and intrascribe variation in accuracy for each section of the notes with ranges from 50% to 76%, resulting in an overall positive predictive value for each note between 38% and 81%.
We created a high-fidelity, video-based EHR simulation, capable of assessing multiple performance indicators in medical scribes. In this cohort, we demonstrate significant variability both in terms of structure and accuracy in clinical documentation. This form of simulation can provide a valuable tool for future development of scribe curriculum and assessment of competency.
电子健康记录(EHRs)的日益普及与一些对医疗服务提供者效率和工作满意度产生的意外负面后果相关。为了解决这一问题,使用医疗抄写员来执行许多所需的电子健康记录功能的情况急剧增加。尽管增长迅速,但关于评估抄写员相关电子健康记录活动的安全性和有效性的培训或评估工具的报道却很少。鉴于有许多报告记录了其他专业群体在电子健康记录界面和数据收集方面存在一些操作失误,抄写员可能也面临类似的挑战。这凸显了为医疗抄写员开发新评估工具的必要性。
本研究的目的是开发一种基于虚拟视频的模拟,以展示和量化抄写员在电子健康记录中抄录笔记的可变性和准确性。
从一个部门的8名抄写员中,总共招募了5名有意从事医疗保健职业且至少有6个月经验的女性抄写员参与我们的模拟研究。我们创建了三个模拟的医患场景。每个场景在我们电子健康记录的模拟实例中都包含一份相应的病历。对于每个场景,我们对标准化的医患会面进行了视频录制。招募了5名在我们的电子健康记录系统以及模拟病例所属专业领域都至少有6个月经验的抄写员。每位抄写员观看模拟会面,并在模拟的电子健康记录环境中抄录笔记。对抄录的笔记进行抄写员间可变性评估,并与准确性的金标准进行比较。
所有抄写员都完成了所有模拟病例。笔记结构和内容在抄写员之间存在显著差异。总体而言,所有数据元素中只有26%是记录这些数据的抄写员所独有的。数据元素一词用于定义抄写员从模拟中感知到的各个数据片段。笔记长度通过计算单词数量来确定,三个病例中最长和最短笔记之间的单词数量差异分别为31%、37%和57%,用词精简程度在23%至71%之间。总体而言,笔记各部分的准确性在抄写员之间和抄写员内部都存在很大差异,范围从50%到76%,导致每份笔记的总体阳性预测值在38%到81%之间。
我们创建了一种高保真的、基于视频的电子健康记录模拟,能够评估医疗抄写员的多个绩效指标。在这个队列中,我们证明了临床文档在结构和准确性方面都存在显著差异。这种模拟形式可以为未来抄写员课程的开发和能力评估提供一个有价值的工具。