Department of Medical Informatics and Clinical Epidemiology, Oregon Health and Sciences University, Portland, OR, United States.
J Med Internet Res. 2024 Apr 22;26:e54419. doi: 10.2196/54419.
Medical documentation plays a crucial role in clinical practice, facilitating accurate patient management and communication among health care professionals. However, inaccuracies in medical notes can lead to miscommunication and diagnostic errors. Additionally, the demands of documentation contribute to physician burnout. Although intermediaries like medical scribes and speech recognition software have been used to ease this burden, they have limitations in terms of accuracy and addressing provider-specific metrics. The integration of ambient artificial intelligence (AI)-powered solutions offers a promising way to improve documentation while fitting seamlessly into existing workflows.
This study aims to assess the accuracy and quality of Subjective, Objective, Assessment, and Plan (SOAP) notes generated by ChatGPT-4, an AI model, using established transcripts of History and Physical Examination as the gold standard. We seek to identify potential errors and evaluate the model's performance across different categories.
We conducted simulated patient-provider encounters representing various ambulatory specialties and transcribed the audio files. Key reportable elements were identified, and ChatGPT-4 was used to generate SOAP notes based on these transcripts. Three versions of each note were created and compared to the gold standard via chart review; errors generated from the comparison were categorized as omissions, incorrect information, or additions. We compared the accuracy of data elements across versions, transcript length, and data categories. Additionally, we assessed note quality using the Physician Documentation Quality Instrument (PDQI) scoring system.
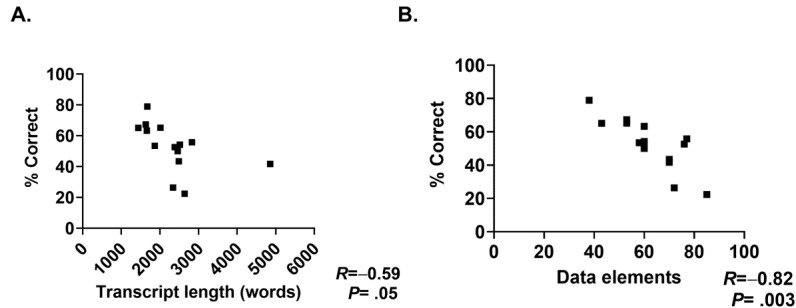
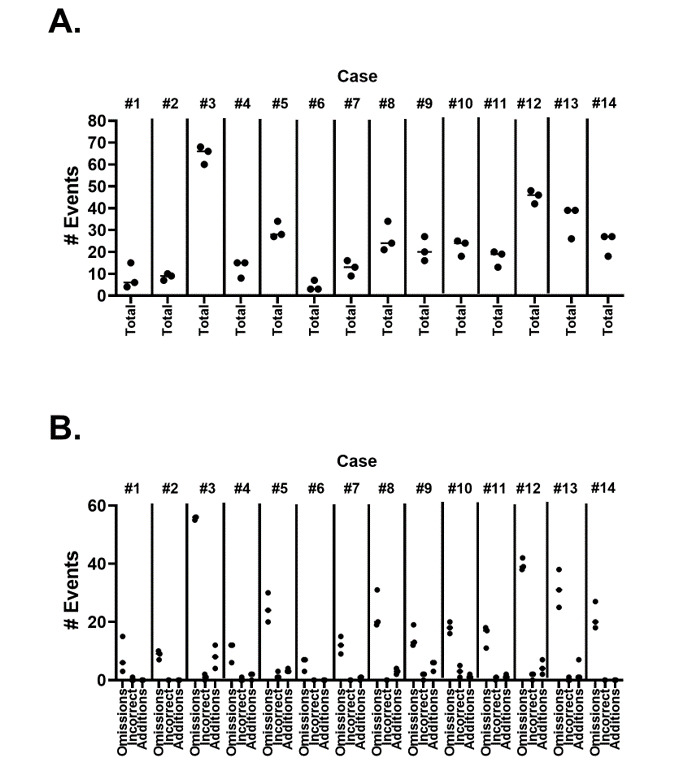
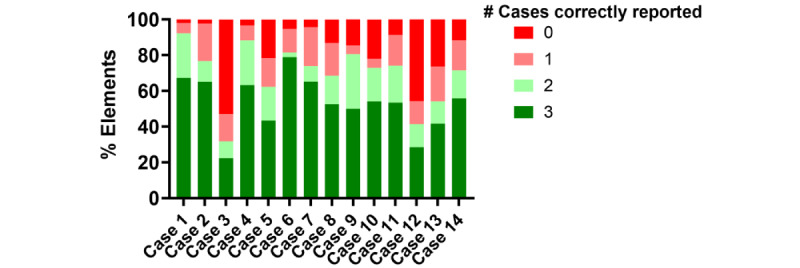
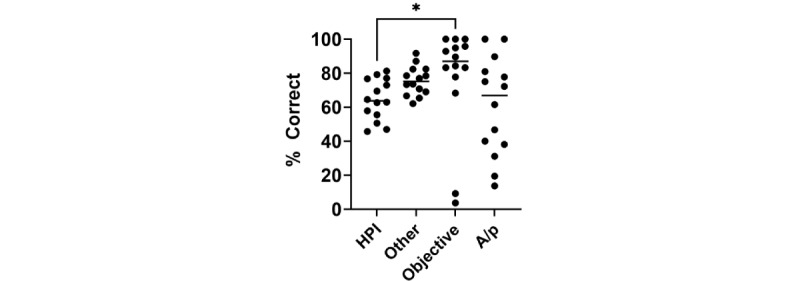
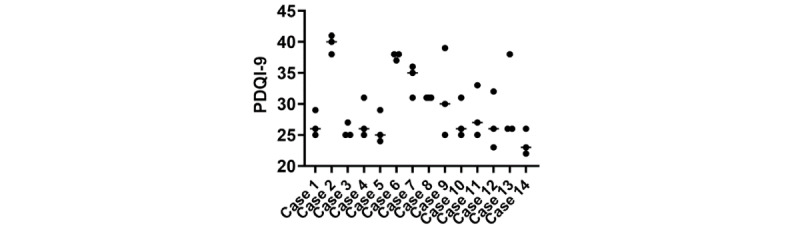
Although ChatGPT-4 consistently generated SOAP-style notes, there were, on average, 23.6 errors per clinical case, with errors of omission (86%) being the most common, followed by addition errors (10.5%) and inclusion of incorrect facts (3.2%). There was significant variance between replicates of the same case, with only 52.9% of data elements reported correctly across all 3 replicates. The accuracy of data elements varied across cases, with the highest accuracy observed in the "Objective" section. Consequently, the measure of note quality, assessed by PDQI, demonstrated intra- and intercase variance. Finally, the accuracy of ChatGPT-4 was inversely correlated to both the transcript length (P=.05) and the number of scorable data elements (P=.05).
Our study reveals substantial variability in errors, accuracy, and note quality generated by ChatGPT-4. Errors were not limited to specific sections, and the inconsistency in error types across replicates complicated predictability. Transcript length and data complexity were inversely correlated with note accuracy, raising concerns about the model's effectiveness in handling complex medical cases. The quality and reliability of clinical notes produced by ChatGPT-4 do not meet the standards required for clinical use. Although AI holds promise in health care, caution should be exercised before widespread adoption. Further research is needed to address accuracy, variability, and potential errors. ChatGPT-4, while valuable in various applications, should not be considered a safe alternative to human-generated clinical documentation at this time.
医学文献在临床实践中起着至关重要的作用,有助于准确管理患者并促进医疗保健专业人员之间的沟通。然而,医疗记录中的不准确之处可能导致沟通失误和诊断错误。此外,文献记录的需求导致医生倦怠。尽管已经使用了医疗抄写员和语音识别软件等中介来减轻这种负担,但它们在准确性和满足特定提供者的指标方面存在局限性。集成环境人工智能 (AI) 驱动的解决方案提供了一种有前途的方法,可以在无缝融入现有工作流程的同时提高文档质量。
本研究旨在评估 ChatGPT-4(一种 AI 模型)生成的主观、客观、评估和计划 (SOAP) 记录的准确性和质量,使用历史和体检的既定记录作为黄金标准。我们旨在识别潜在错误并评估模型在不同类别中的性能。
我们进行了模拟的医患就诊,代表了各种门诊专业,并对音频文件进行了转录。确定了可报告的关键要素,并使用这些记录生成 ChatGPT-4 生成基于这些记录的 SOAP 记录。为每个记录创建了三个版本,并通过图表审查与黄金标准进行比较;通过比较生成的错误被归类为遗漏、信息错误或添加。我们比较了不同版本、转录长度和数据类别之间的数据元素的准确性。此外,我们使用医师文献质量工具 (PDQI) 评分系统评估记录质量。
尽管 ChatGPT-4 始终如一地生成 SOAP 风格的记录,但平均每个临床病例有 23.6 个错误,遗漏错误(86%)最为常见,其次是添加错误(10.5%)和包含不正确事实(3.2%)。同一病例的重复之间存在显著差异,所有 3 个重复中只有 52.9%的数据元素报告正确。数据元素的准确性因病例而异,在“客观”部分观察到最高的准确性。因此,通过 PDQI 评估的记录质量衡量标准表现出了病例内和病例间的差异。最后,ChatGPT-4 的准确性与转录长度(P=.05)和可评分数据元素数量(P=.05)呈负相关。
我们的研究揭示了 ChatGPT-4 生成的错误、准确性和记录质量存在很大差异。错误不仅限于特定部分,并且重复之间错误类型的不一致使得可预测性变得复杂。转录长度和数据复杂性与记录准确性呈负相关,这引发了对模型处理复杂医疗病例的有效性的担忧。ChatGPT-4 生成的临床记录的质量和可靠性不符合临床使用的标准。虽然人工智能在医疗保健中有很大的应用前景,但在广泛采用之前应该谨慎行事。需要进一步研究以解决准确性、可变性和潜在错误问题。ChatGPT-4 在各种应用中很有价值,但在现阶段不应被视为人类生成的临床文档的安全替代方案。