Alfonso-García Alba, Paugh Jerry, Farid Marjan, Garg Sumit, Jester James V, Potma Eric O
Department of Biomedical Engineering, University of California, Irvine.
Department of Chemistry, University of California, Irvine.
J Raman Spectrosc. 2017 Jun;48(6):803-812. doi: 10.1002/jrs.5118. Epub 2017 Apr 11.
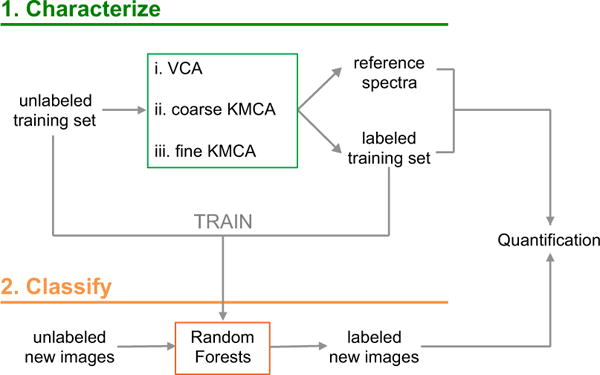
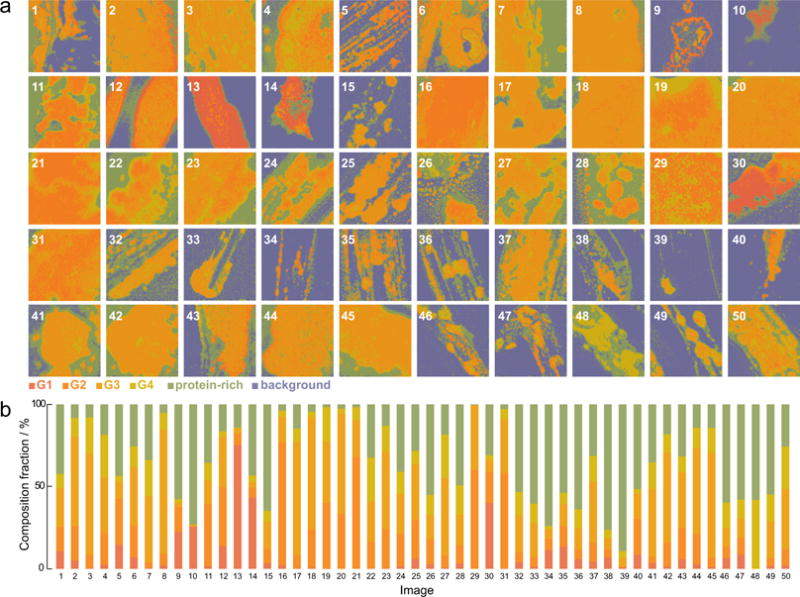
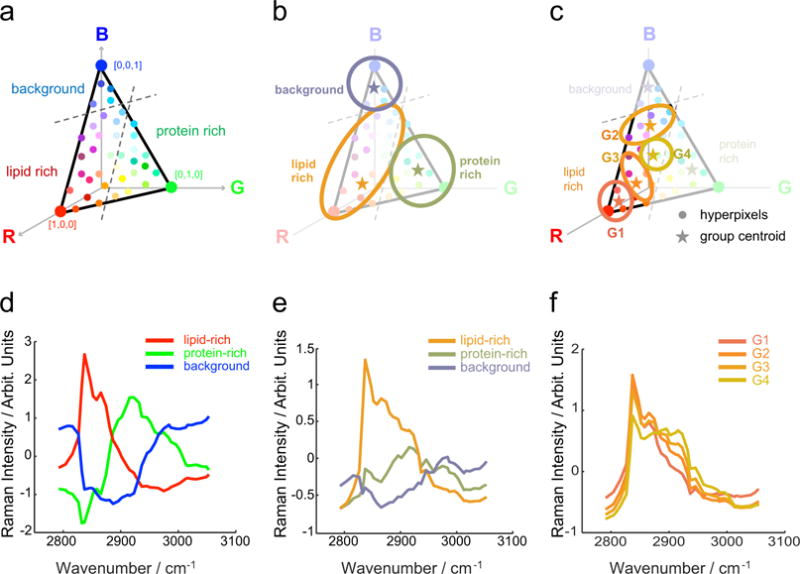
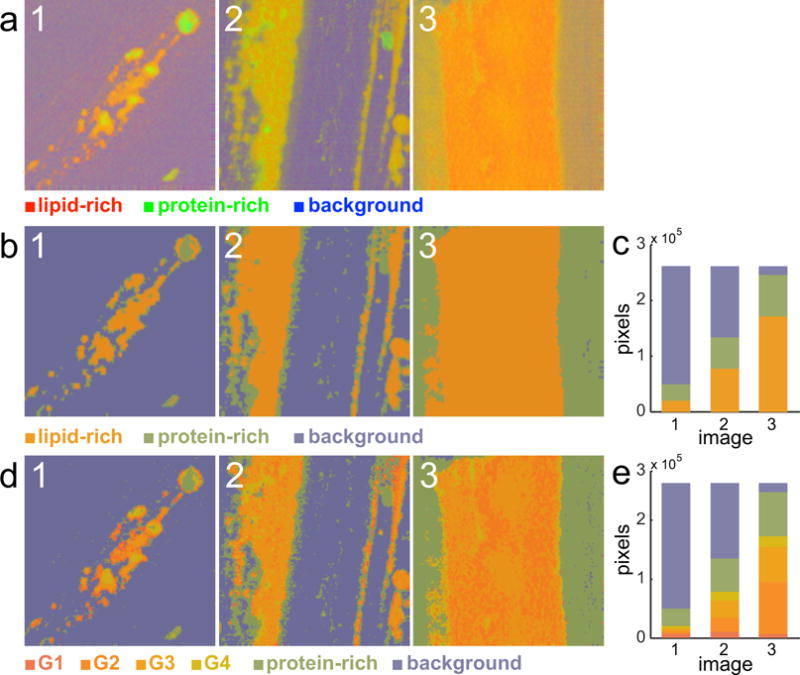
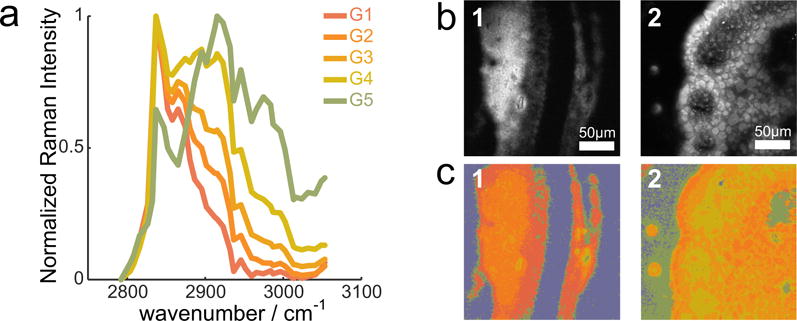
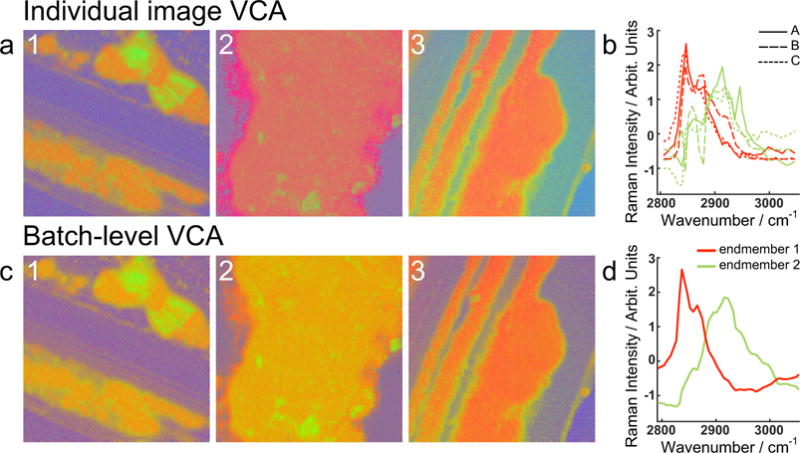
We develop and discuss a methodology for batch-level analysis of hyperspectral stimulated Raman scattering (hsSRS) data sets of human meibum in the CH-stretching vibrational range. The analysis consists of two steps. The first step uses a training set (n=19) to determine chemically meaningful reference spectra that jointly constitute a basis set for the sample. This procedure makes use of batch-level vertex component analysis (VCA), followed by unsupervised k-means clustering to express the data set in terms of spectra that represent lipid and protein mixtures in changing proportions. The second step uses a random forest classifier to rapidly classify hsSRS stacks in terms of the pre-determined basis set. The overall procedure allows a rapid quantitative analysis of large hsSRS data sets, enabling a direct comparison among samples using a single set of reference spectra. We apply this procedure to assess 50 specimens of expressed human meibum, rich in both protein and lipid, and show that the batch-level analysis reveals marked variation among samples that potentially correlate with meibum health quality.
我们开发并讨论了一种用于批量分析人体睑脂在碳氢键拉伸振动范围内的高光谱受激拉曼散射(hsSRS)数据集的方法。该分析包括两个步骤。第一步使用一个训练集(n = 19)来确定具有化学意义的参考光谱,这些光谱共同构成样本的一个基集。此过程利用批量顶点成分分析(VCA),随后进行无监督k均值聚类,以便根据代表不同比例脂质和蛋白质混合物的光谱来表达数据集。第二步使用随机森林分类器根据预先确定的基集对hsSRS堆栈进行快速分类。整个过程允许对大型hsSRS数据集进行快速定量分析,从而能够使用一组参考光谱对样本进行直接比较。我们应用此程序评估了50个富含蛋白质和脂质的人体睑脂标本,并表明批量分析揭示了样本之间显著的差异,这些差异可能与睑脂健康质量相关。