Belin Pascal, Boehme Bibi, McAleer Phil
La Timone Neuroscience Institute, Mixed Research Unit 7289 Centre National de la Recherche Scientifique and Aix-Marseille University, Marseille, France.
School of Psychology, Institute of Medicine Veterinary and Life Sciences, University of Glasgow, Glasgow, United Kingdom.
PLoS One. 2017 Oct 12;12(10):e0185651. doi: 10.1371/journal.pone.0185651. eCollection 2017.
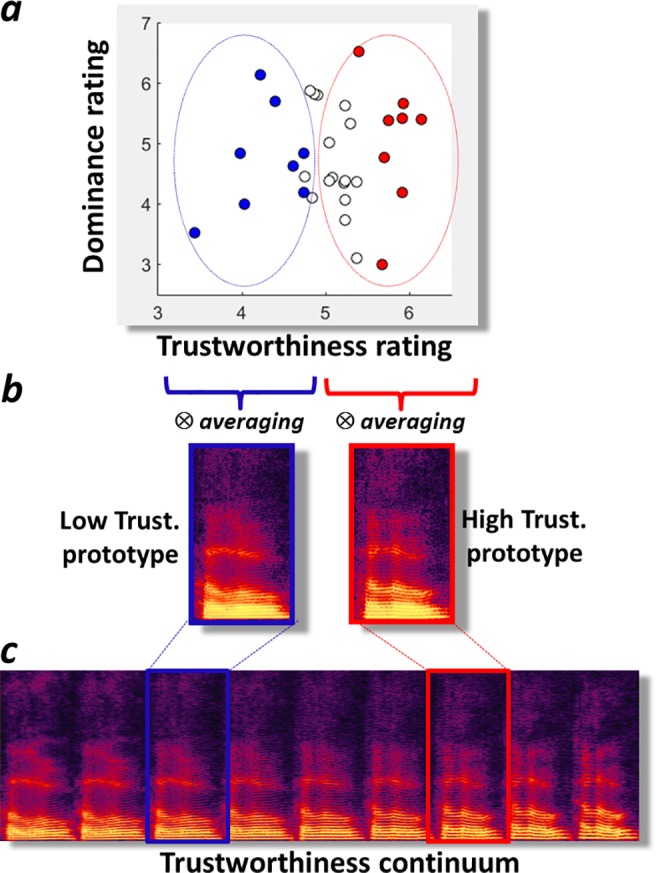
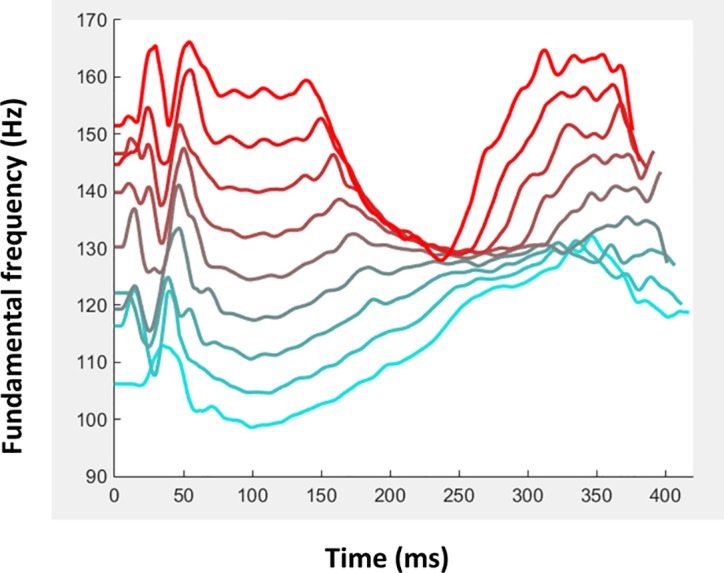
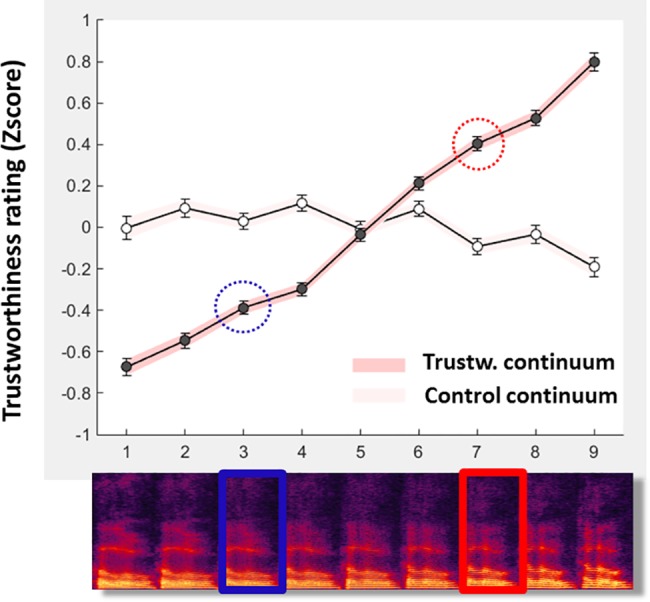
When we hear a new voice we automatically form a "first impression" of the voice owner's personality; a single word is sufficient to yield ratings highly consistent across listeners. Past studies have shown correlations between personality ratings and acoustical parameters of voice, suggesting a potential acoustical basis for voice personality impressions, but its nature and extent remain unclear. Here we used data-driven voice computational modelling to investigate the link between acoustics and perceived trustworthiness in the single word "hello". Two prototypical voice stimuli were generated based on the acoustical features of voices rated low or high in perceived trustworthiness, respectively, as well as a continuum of stimuli inter- and extrapolated between these two prototypes. Five hundred listeners provided trustworthiness ratings on the stimuli via an online interface. We observed an extremely tight relationship between trustworthiness ratings and position along the trustworthiness continuum (r = 0.99). Not only were trustworthiness ratings higher for the high- than the low-prototypes, but the difference could be modulated quasi-linearly by reducing or exaggerating the acoustical difference between the prototypes, resulting in a strong caricaturing effect. The f0 trajectory, or intonation, appeared a parameter of particular relevance: hellos rated high in trustworthiness were characterized by a high starting f0 then a marked decrease at mid-utterance to finish on a strong rise. These results demonstrate a strong acoustical basis for voice personality impressions, opening the door to multiple potential applications.
当我们听到一个新声音时,会自动对声音的主人形成“第一印象”;一个单词就足以让听众给出高度一致的评分。过去的研究表明,人格评分与声音的声学参数之间存在相关性,这表明声音人格印象可能存在声学基础,但其本质和程度仍不清楚。在此,我们使用数据驱动的语音计算模型来研究单个单词“hello”的声学与感知到的可信度之间的联系。分别基于在感知可信度方面被评为低或高的声音的声学特征生成了两个典型的语音刺激,以及在这两个原型之间内插和外推的一系列刺激。五百名听众通过在线界面提供了对这些刺激的可信度评分。我们观察到可信度评分与沿着可信度连续体的位置之间存在极其紧密的关系(r = 0.99)。不仅高原型的可信度评分高于低原型,而且通过减少或夸大原型之间的声学差异,可以准线性地调节这种差异,从而产生强烈的夸张效果。基频轨迹或语调似乎是一个特别相关的参数:在可信度方面被评为高的“hello”的特征是基频起始较高,然后在话语中间显著下降,最后以强烈上升结束。这些结果证明了声音人格印象存在强大的声学基础,为多种潜在应用打开了大门。