Heinze Georg, Wallisch Christine, Dunkler Daniela
Section for Clinical Biometrics, Center for Medical Statistics, Informatics and Intelligent Systems, Medical University of Vienna, Vienna, 1090, Austria.
Biom J. 2018 May;60(3):431-449. doi: 10.1002/bimj.201700067. Epub 2018 Jan 2.
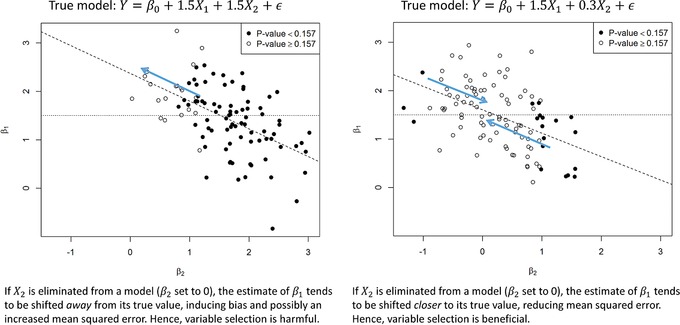
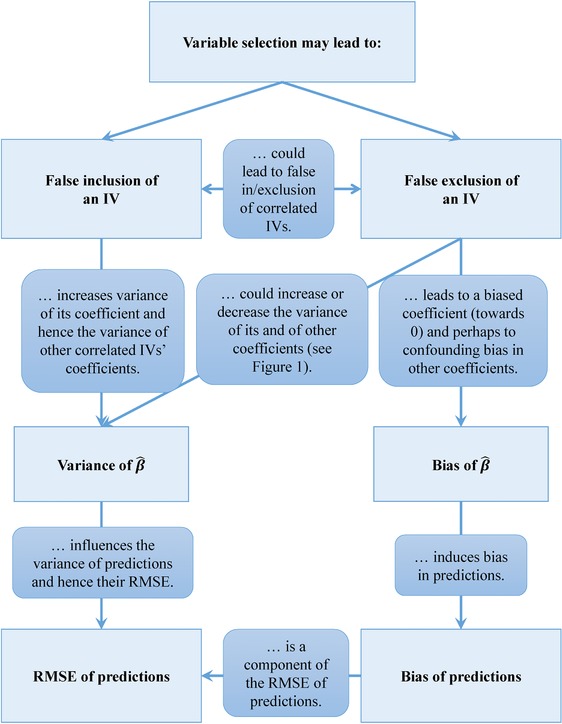
Statistical models support medical research by facilitating individualized outcome prognostication conditional on independent variables or by estimating effects of risk factors adjusted for covariates. Theory of statistical models is well-established if the set of independent variables to consider is fixed and small. Hence, we can assume that effect estimates are unbiased and the usual methods for confidence interval estimation are valid. In routine work, however, it is not known a priori which covariates should be included in a model, and often we are confronted with the number of candidate variables in the range 10-30. This number is often too large to be considered in a statistical model. We provide an overview of various available variable selection methods that are based on significance or information criteria, penalized likelihood, the change-in-estimate criterion, background knowledge, or combinations thereof. These methods were usually developed in the context of a linear regression model and then transferred to more generalized linear models or models for censored survival data. Variable selection, in particular if used in explanatory modeling where effect estimates are of central interest, can compromise stability of a final model, unbiasedness of regression coefficients, and validity of p-values or confidence intervals. Therefore, we give pragmatic recommendations for the practicing statistician on application of variable selection methods in general (low-dimensional) modeling problems and on performing stability investigations and inference. We also propose some quantities based on resampling the entire variable selection process to be routinely reported by software packages offering automated variable selection algorithms.
统计模型通过促进基于自变量的个体化结果预测或通过估计经协变量调整后的风险因素的效应来支持医学研究。如果要考虑的自变量集是固定的且数量较少,统计模型理论就已确立。因此,我们可以假设效应估计是无偏的,并且常用的置信区间估计方法是有效的。然而,在日常工作中,事先并不知道哪些协变量应包含在模型中,而且我们常常面临候选变量数量在10到30之间的情况。这个数量通常太大,无法在统计模型中进行考虑。我们概述了各种可用的变量选择方法,这些方法基于显著性或信息准则、惩罚似然、估计变化准则、背景知识或它们的组合。这些方法通常是在线性回归模型的背景下开发的,然后转移到更广义的线性模型或删失生存数据模型中。变量选择,特别是在用于解释性建模(其中效应估计是核心关注点)时,可能会损害最终模型的稳定性、回归系数的无偏性以及p值或置信区间的有效性。因此,我们就变量选择方法在一般(低维)建模问题中的应用以及进行稳定性研究和推断,向执业统计学家给出实用建议。我们还基于对整个变量选择过程进行重采样提出了一些量,供提供自动变量选择算法的软件包常规报告。