Das Ranajit, Upadhyai Priyanka
Manipal Centre for Natural Sciences (MCNS), Manipal Academy of Higher Education, Madhav Nagar, Manipal, 576104, Karnataka, India.
Department of Medical Genetics, Kasturba Medical College, Manipal Academy of Higher Education, Manipal, Karnataka, India.
BMC Genet. 2017 Dec 28;18(Suppl 1):109. doi: 10.1186/s12863-017-0579-2.
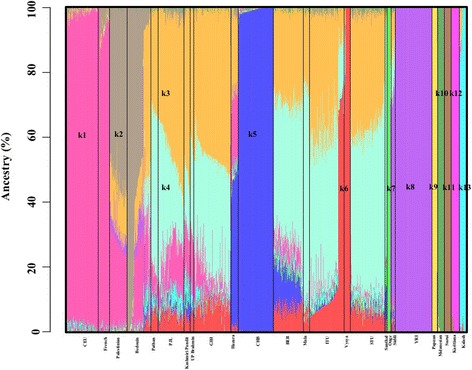
The utilization of biological data to infer the geographic origins of human populations has been a long standing quest for biologists and anthropologists. Several biogeographical analysis tools have been developed to infer the geographical origins of human populations utilizing genetic data. However due to the inherent complexity of genetic information these approaches are prone to misinterpretations. The Geographic Population Structure (GPS) algorithm is an admixture based tool for biogeographical analyses and has been employed for the geo-localization of various populations worldwide. Here we sought to dissect its sensitivity and accuracy for localizing highly admixed groups. Given the complex history of population dispersal and gene flow in the Indian subcontinent, we have employed the GPS tool to localize five South Asian populations, Punjabi, Gujarati, Tamil, Telugu and Bengali from the 1000 Genomes project, some of whom were recent migrants to USA and UK, using populations from the Indian subcontinent available in Human Genome Diversity Panel (HGDP) and those previously described as reference.
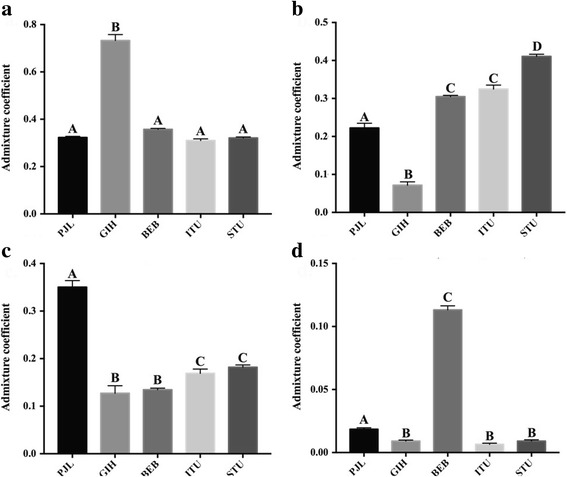
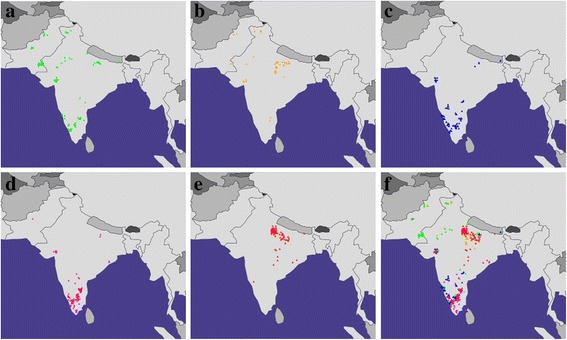
Our findings demonstrate reasonably high accuracy with regards to GPS assignment even for recent migrant populations sampled elsewhere, namely the Tamil, Telugu and Gujarati individuals, where 96%, 87% and 79% of the individuals, respectively, were positioned within 600 km of their native locations. While the absence of appropriate reference populations resulted in moderate-to-low levels of precision in positioning of Punjabi and Bengali genomes.
Our findings reflect that the GPS approach is useful but likely overtly dependent on the relative proportions of admixture in the reference populations for determination of the biogeographical origins of test individuals. We conclude that further modifications are desired to make this approach more suitable for highly admixed individuals.
利用生物数据推断人类群体的地理起源一直是生物学家和人类学家长期以来的追求。已经开发了几种生物地理分析工具,以利用遗传数据推断人类群体的地理起源。然而,由于遗传信息固有的复杂性,这些方法容易产生误解。地理种群结构(GPS)算法是一种基于混合的生物地理分析工具,已被用于全球各种群体的地理定位。在这里,我们试图剖析其对高度混合群体进行定位的敏感性和准确性。鉴于印度次大陆人口迁移和基因流动的复杂历史,我们使用人类基因组多样性面板(HGDP)中可用的印度次大陆群体以及先前描述为参考群体的群体,运用GPS工具对来自千人基因组计划的五个南亚群体(旁遮普人、古吉拉特人、泰米尔人、泰卢固人和孟加拉人)进行定位,其中一些人是最近移民到美国和英国的。
我们的研究结果表明,即使对于在其他地方采样的近期移民群体,即泰米尔人、泰卢固人和古吉拉特人个体,GPS分配也具有相当高的准确性,分别有96%、87%和79%的个体被定位在其原籍地600公里范围内。而由于缺乏合适的参考群体,旁遮普人和孟加拉人基因组的定位精度处于中低水平。
我们的研究结果表明,GPS方法是有用的,但在确定测试个体的生物地理起源时,可能过度依赖参考群体中的混合相对比例。我们得出结论,需要进一步改进以使这种方法更适合高度混合的个体。