Department of Computer and Information Science, University of Macau, Taipa, Macau, China.
Sci Rep. 2018 Jan 26;8(1):1697. doi: 10.1038/s41598-018-19752-w.
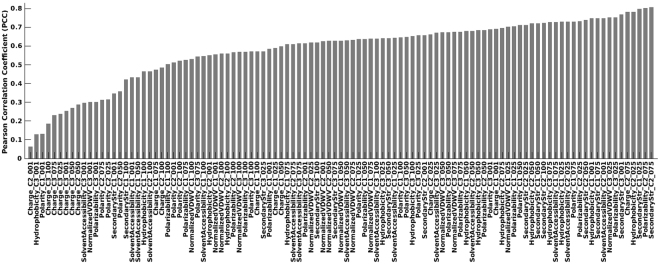
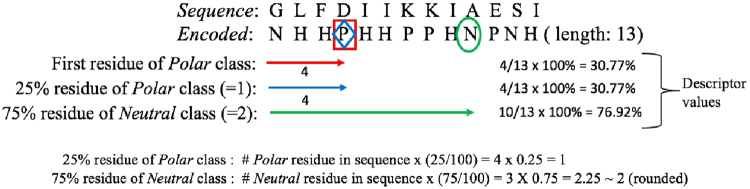
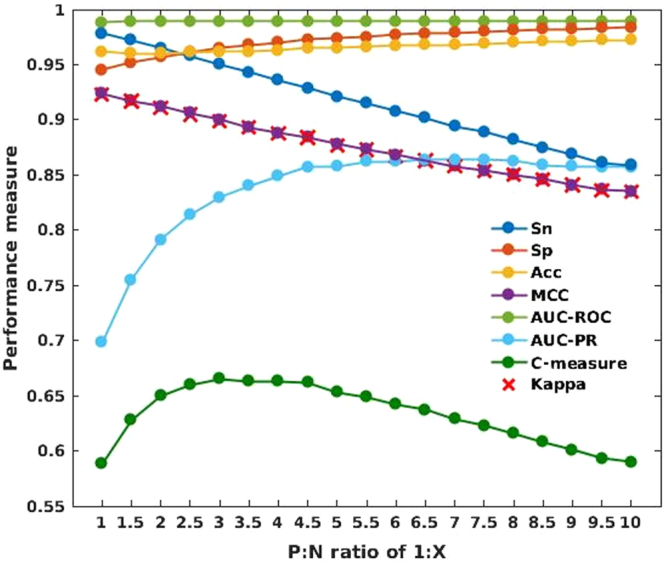
Antimicrobial peptides (AMPs) are promising candidates in the fight against multidrug-resistant pathogens owing to AMPs' broad range of activities and low toxicity. Nonetheless, identification of AMPs through wet-lab experiments is still expensive and time consuming. Here, we propose an accurate computational method for AMP prediction by the random forest algorithm. The prediction model is based on the distribution patterns of amino acid properties along the sequence. Using our collection of large and diverse sets of AMP and non-AMP data (3268 and 166791 sequences, respectively), we evaluated 19 random forest classifiers with different positive:negative data ratios by 10-fold cross-validation. Our optimal model, AmPEP with the 1:3 data ratio, showed high accuracy (96%), Matthew's correlation coefficient (MCC) of 0.9, area under the receiver operating characteristic curve (AUC-ROC) of 0.99, and the Kappa statistic of 0.9. Descriptor analysis of AMP/non-AMP distributions by means of Pearson correlation coefficients revealed that reduced feature sets (from a full-featured set of 105 to a minimal-feature set of 23) can result in comparable performance in all respects except for some reductions in precision. Furthermore, AmPEP outperformed existing methods in terms of accuracy, MCC, and AUC-ROC when tested on benchmark datasets.
抗菌肽 (AMPs) 由于其广泛的活性和低毒性,是对抗多药耐药病原体的有前途的候选物。尽管如此,通过湿实验室实验鉴定 AMP 仍然昂贵且耗时。在这里,我们提出了一种基于随机森林算法的 AMP 预测的准确计算方法。预测模型基于氨基酸性质沿序列分布的模式。使用我们收集的大量和多样化的 AMP 和非 AMP 数据集(分别为 3268 和 166791 个序列),我们通过 10 倍交叉验证评估了 19 个具有不同正:负数据比的随机森林分类器。我们的最优模型 AmPEP(数据比为 1:3)具有高准确性(96%)、马修相关系数(MCC)为 0.9、接收者操作特征曲线下的面积(AUC-ROC)为 0.99 和卡帕统计量为 0.9。通过皮尔逊相关系数对 AMP/非 AMP 分布的描述性分析表明,除了某些精度降低外,减少特征集(从全特征集 105 减少到最小特征集 23)可以在所有方面产生可比的性能。此外,当在基准数据集上进行测试时,AmPEP 在准确性、MCC 和 AUC-ROC 方面优于现有方法。