Ratner Alexander J, Ehrenberg Henry R, Hussain Zeshan, Dunnmon Jared, Ré Christopher
Stanford University.
Adv Neural Inf Process Syst. 2017 Dec;30:3239-3249.
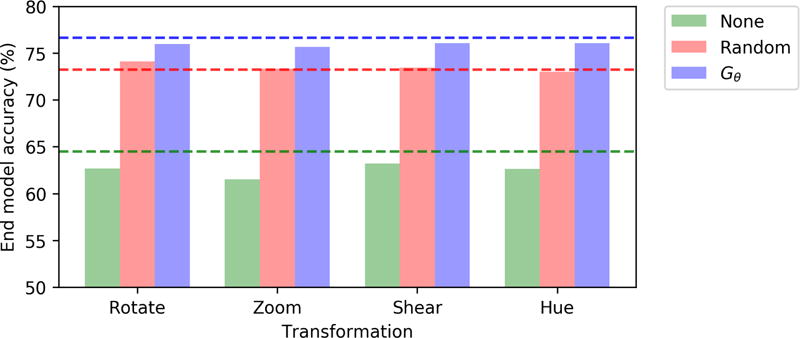
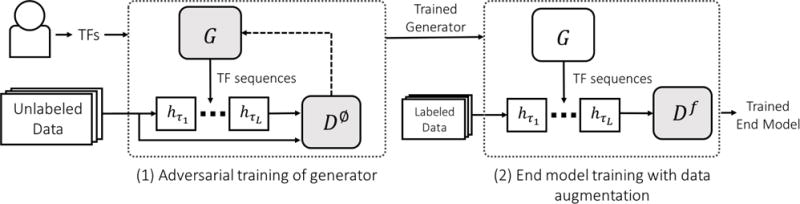
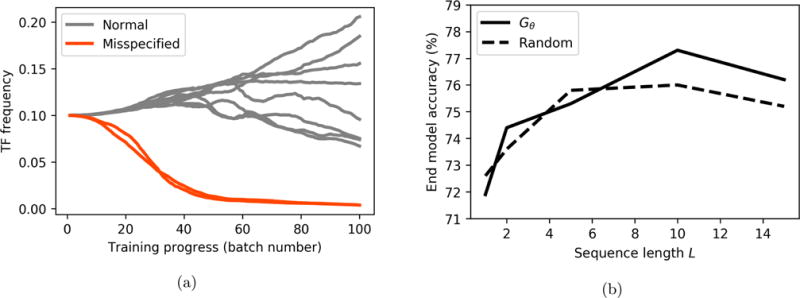
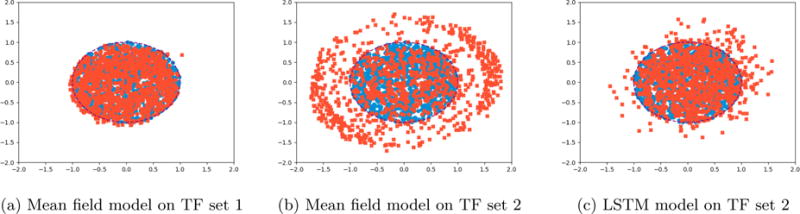
Data augmentation is a ubiquitous technique for increasing the size of labeled training sets by leveraging task-specific data transformations that preserve class labels. While it is often easy for domain experts to specify individual transformations, constructing and tuning the more sophisticated compositions typically needed to achieve state-of-the-art results is a time-consuming manual task in practice. We propose a method for automating this process by learning a generative sequence model over user-specified transformation functions using a generative adversarial approach. Our method can make use of arbitrary, non-deterministic transformation functions, is robust to misspecified user input, and is trained on unlabeled data. The learned transformation model can then be used to perform data augmentation for any end discriminative model. In our experiments, we show the efficacy of our approach on both image and text datasets, achieving improvements of 4.0 accuracy points on CIFAR-10, 1.4 F1 points on the ACE relation extraction task, and 3.4 accuracy points when using domain-specific transformation operations on a medical imaging dataset as compared to standard heuristic augmentation approaches.
数据增强是一种普遍使用的技术,通过利用保留类别标签的特定任务数据变换来增加标记训练集的大小。虽然领域专家通常很容易指定单个变换,但构建和调整实现最先进结果通常所需的更复杂的组合在实践中是一项耗时的手动任务。我们提出了一种方法,通过使用生成对抗方法在用户指定的变换函数上学习生成序列模型来自动化这个过程。我们的方法可以使用任意的、非确定性的变换函数,对错误指定的用户输入具有鲁棒性,并且在未标记数据上进行训练。然后,学习到的变换模型可以用于为任何最终判别模型执行数据增强。在我们的实验中,我们展示了我们的方法在图像和文本数据集上的有效性,与标准启发式增强方法相比,在CIFAR-10上准确率提高了4.0个百分点,在ACE关系提取任务上F1分数提高了1.4分,在医学成像数据集上使用特定领域变换操作时准确率提高了3.4个百分点。