Tang Fei, Ishwaran Hemant
Division of Biostatistics, University of Miami.
Stat Anal Data Min. 2017 Dec;10(6):363-377. doi: 10.1002/sam.11348. Epub 2017 Jun 13.
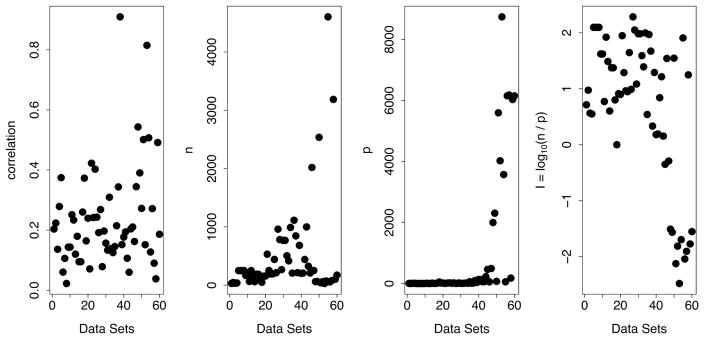
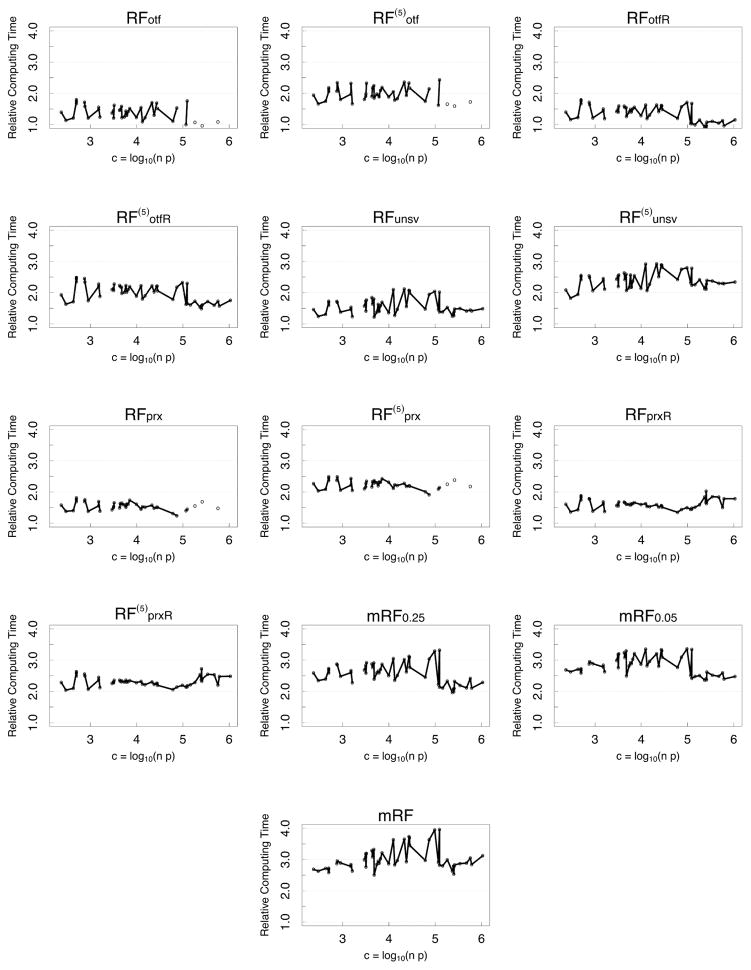
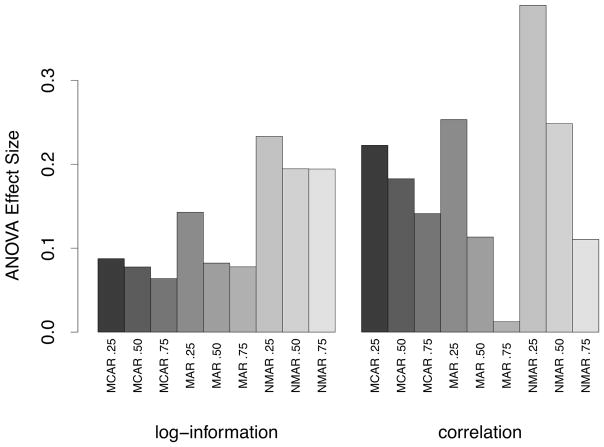
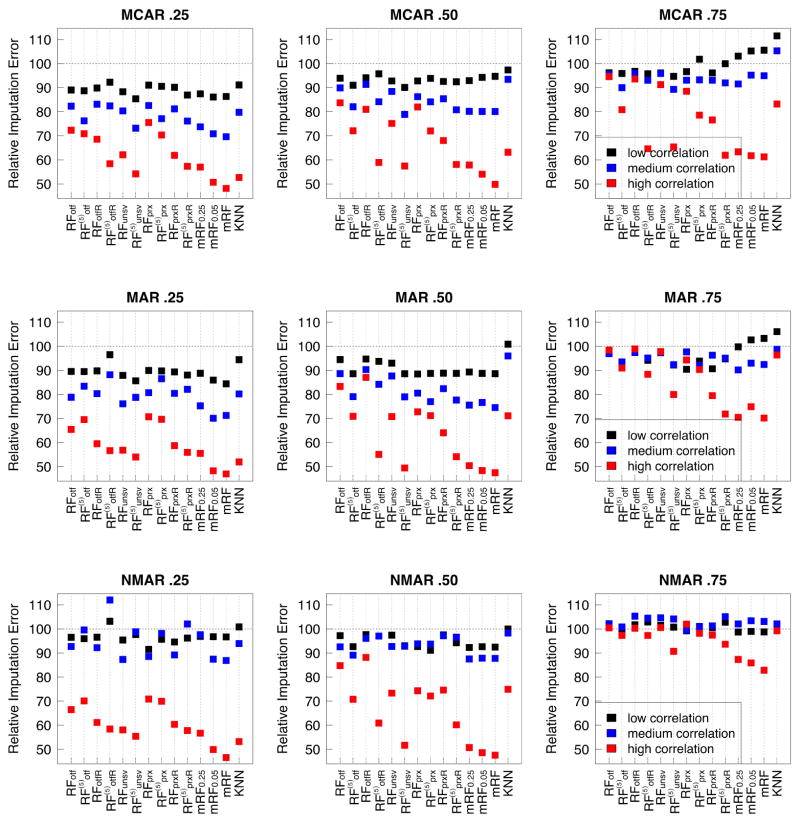
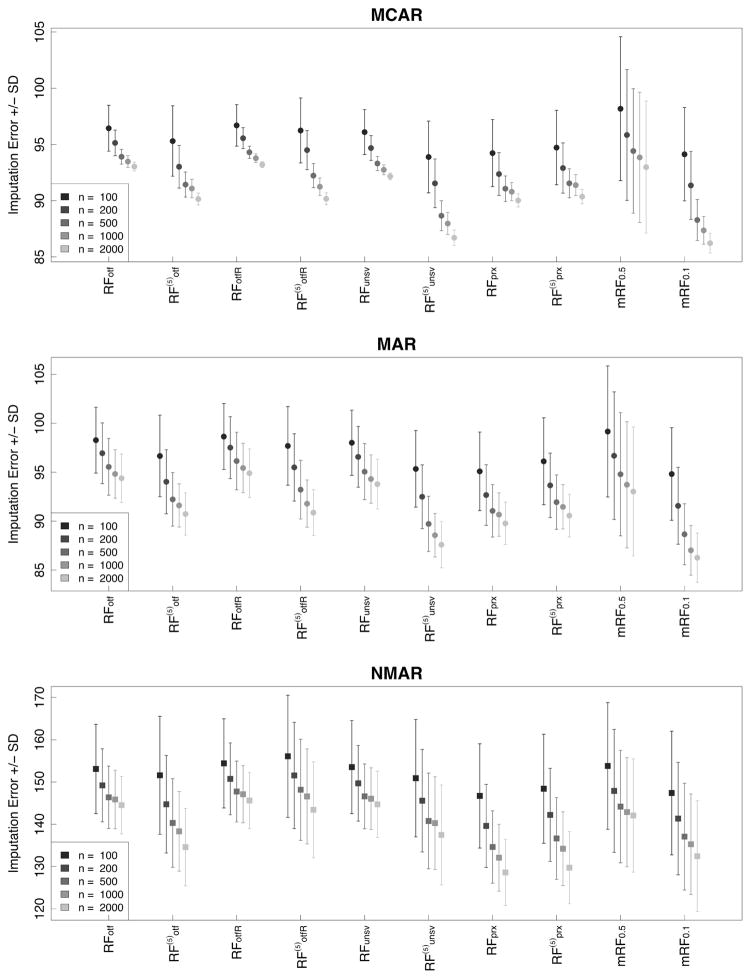
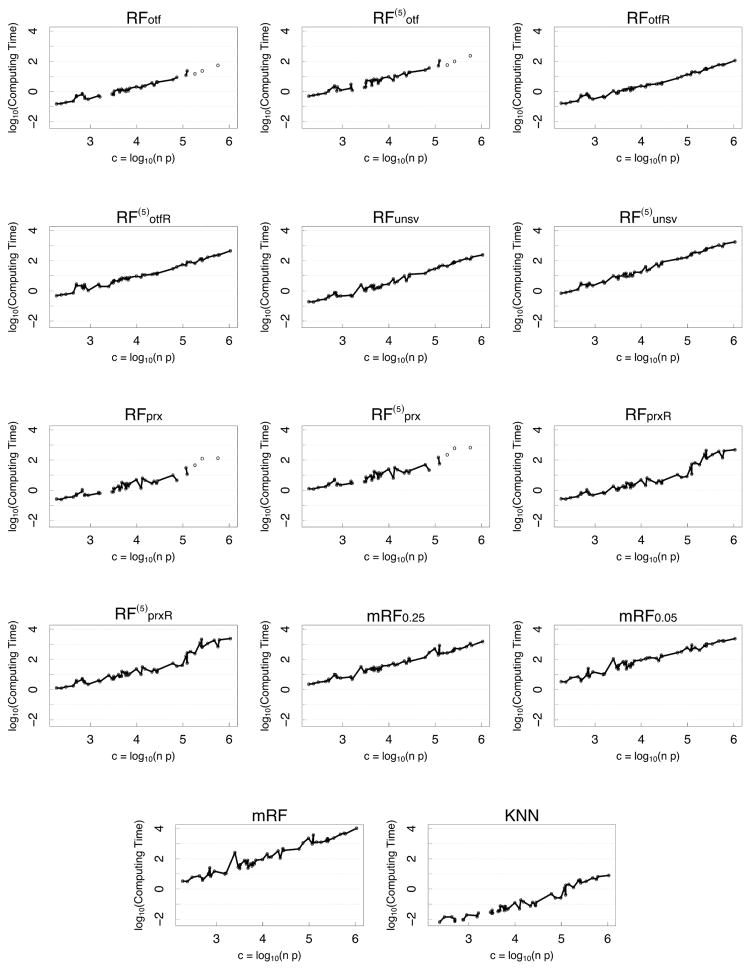
Random forest (RF) missing data algorithms are an attractive approach for imputing missing data. They have the desirable properties of being able to handle mixed types of missing data, they are adaptive to interactions and nonlinearity, and they have the potential to scale to big data settings. Currently there are many different RF imputation algorithms, but relatively little guidance about their efficacy. Using a large, diverse collection of data sets, imputation performance of various RF algorithms was assessed under different missing data mechanisms. Algorithms included proximity imputation, on the fly imputation, and imputation utilizing multivariate unsupervised and supervised splitting-the latter class representing a generalization of a new promising imputation algorithm called missForest. Our findings reveal RF imputation to be generally robust with performance improving with increasing correlation. Performance was good under moderate to high missingness, and even (in certain cases) when data was missing not at random.
随机森林(RF)缺失数据算法是一种用于插补缺失数据的有吸引力的方法。它们具有能够处理混合类型缺失数据的理想特性,能适应交互作用和非线性,并且有扩展到大数据设置的潜力。目前有许多不同的随机森林插补算法,但关于它们功效的指导相对较少。使用大量多样的数据集,在不同的缺失数据机制下评估了各种随机森林算法的插补性能。算法包括临近值插补、即时插补,以及利用多变量无监督和有监督分裂的插补——后一类代表了一种名为missForest的新的有前景的插补算法的推广。我们的研究结果表明,随机森林插补通常具有稳健性,性能会随着相关性的增加而提高。在中度到高度缺失的情况下,甚至(在某些情况下)当数据非随机缺失时,性能也良好。