European Molecular Biology Laboratory, European Bioinformatics Institute, Wellcome Genome Campus, Hinxton, Cambridge, CB10 1SD, UK.
Division of Genomic Medicine, National Human Genome Research Institute, National Institutes of Health, Bethesda, MD, 20892-9305, USA.
Genome Biol. 2018 Feb 15;19(1):21. doi: 10.1186/s13059-018-1396-2.
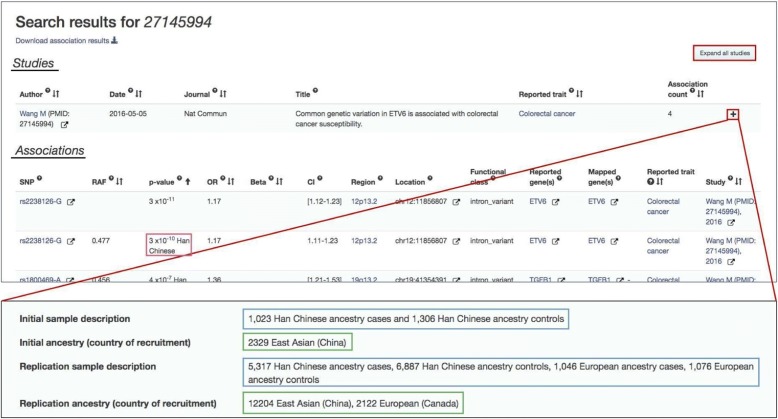
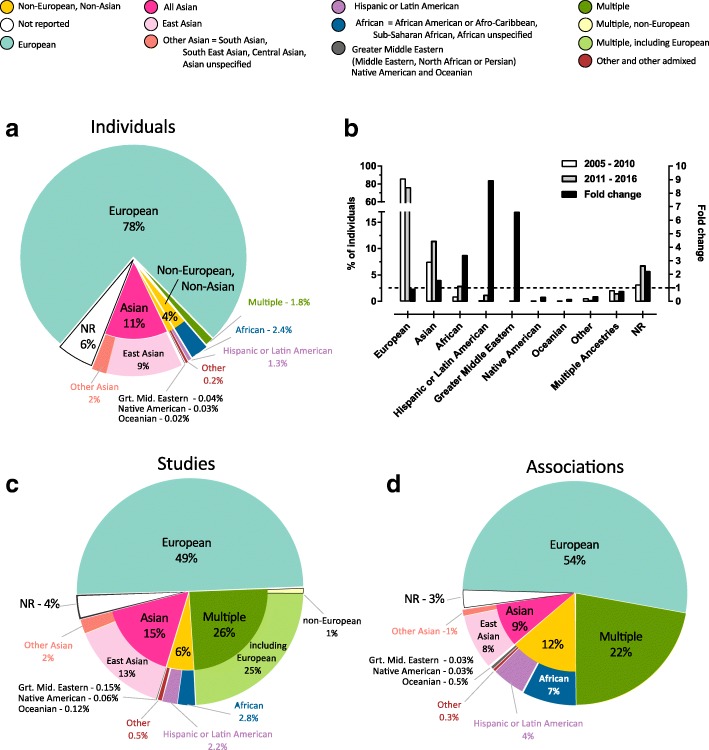
The accurate description of ancestry is essential to interpret, access, and integrate human genomics data, and to ensure that these benefit individuals from all ancestral backgrounds. However, there are no established guidelines for the representation of ancestry information. Here we describe a framework for the accurate and standardized description of sample ancestry, and validate it by application to the NHGRI-EBI GWAS Catalog. We confirm known biases and gaps in diversity, and find that African and Hispanic or Latin American ancestry populations contribute a disproportionately high number of associations. It is our hope that widespread adoption of this framework will lead to improved analysis, interpretation, and integration of human genomics data.
准确描述祖先背景对于解释、获取和整合人类基因组学数据至关重要,并且能够确保所有祖先背景的个体都能从中受益。然而,目前还没有关于描述祖先信息的既定准则。在这里,我们描述了一个用于准确和标准化描述样本祖先背景的框架,并通过将其应用于 NHGRI-EBI GWAS 目录进行了验证。我们确认了多样性方面已知的偏差和差距,并发现非洲裔和西班牙裔或拉丁裔人群贡献了不成比例的大量关联。我们希望广泛采用这一框架,从而提高人类基因组学数据的分析、解释和整合水平。