Berger Christopher C, Gonzalez-Franco Mar, Tajadura-Jiménez Ana, Florencio Dinei, Zhang Zhengyou
Microsoft Research, Redmond, WA, United States.
Division of Biology and Biological Engineering, California Institute of Technology, Pasadena, CA, United States.
Front Neurosci. 2018 Feb 2;12:21. doi: 10.3389/fnins.2018.00021. eCollection 2018.
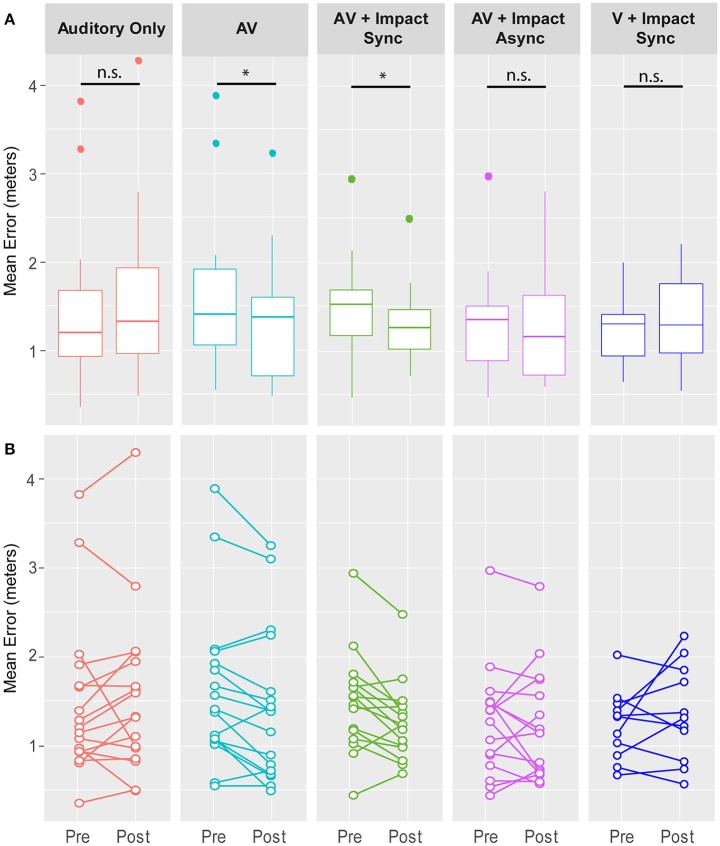
Auditory spatial localization in humans is performed using a combination of interaural time differences, interaural level differences, as well as spectral cues provided by the geometry of the ear. To render spatialized sounds within a virtual reality (VR) headset, either individualized or generic Head Related Transfer Functions (HRTFs) are usually employed. The former require arduous calibrations, but enable accurate auditory source localization, which may lead to a heightened sense of presence within VR. The latter obviate the need for individualized calibrations, but result in less accurate auditory source localization. Previous research on auditory source localization in the real world suggests that our representation of acoustic space is highly plastic. In light of these findings, we investigated whether auditory source localization could be improved for users of generic HRTFs via cross-modal learning. The results show that pairing a dynamic auditory stimulus, with a spatio-temporally aligned visual counterpart, enabled users of generic HRTFs to improve subsequent auditory source localization. Exposure to the auditory stimulus alone or to asynchronous audiovisual stimuli did not improve auditory source localization. These findings have important implications for human perception as well as the development of VR systems as they indicate that generic HRTFs may be enough to enable good auditory source localization in VR.
人类的听觉空间定位是通过双耳时间差、双耳声级差以及耳朵几何形状提供的频谱线索的组合来完成的。为了在虚拟现实(VR)头戴式设备中呈现空间化声音,通常会采用个性化或通用的头部相关传递函数(HRTF)。前者需要进行艰巨的校准,但能够实现精确的声源定位,这可能会增强VR中的临场感。后者无需进行个性化校准,但会导致声源定位不够准确。先前关于现实世界中声源定位的研究表明,我们对声学空间的表征具有高度可塑性。鉴于这些发现,我们研究了是否可以通过跨模态学习来改善通用HRTF用户的声源定位。结果表明,将动态听觉刺激与时空对齐的视觉对应物配对,能够使通用HRTF用户改善后续的声源定位。仅接触听觉刺激或异步视听刺激并不能改善声源定位。这些发现对人类感知以及VR系统的开发具有重要意义,因为它们表明通用HRTF可能足以在VR中实现良好的声源定位。