Beaulieu-Jones Brett K, Lavage Daniel R, Snyder John W, Moore Jason H, Pendergrass Sarah A, Bauer Christopher R
Genomics and Computational Biology Graduate Group, Perelman School of Medicine, University of Pennsylvania, Philadelphia, PA, United States.
Institute for Biomedical Informatics, University of Pennsylvania, Philadelphia, PA, United States.
JMIR Med Inform. 2018 Feb 23;6(1):e11. doi: 10.2196/medinform.8960.
Missing data is a challenge for all studies; however, this is especially true for electronic health record (EHR)-based analyses. Failure to appropriately consider missing data can lead to biased results. While there has been extensive theoretical work on imputation, and many sophisticated methods are now available, it remains quite challenging for researchers to implement these methods appropriately. Here, we provide detailed procedures for when and how to conduct imputation of EHR laboratory results.
The objective of this study was to demonstrate how the mechanism of missingness can be assessed, evaluate the performance of a variety of imputation methods, and describe some of the most frequent problems that can be encountered.
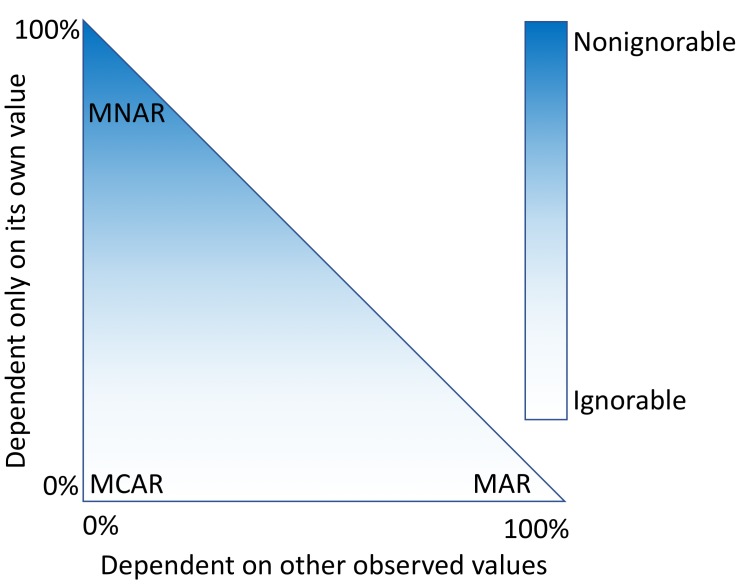
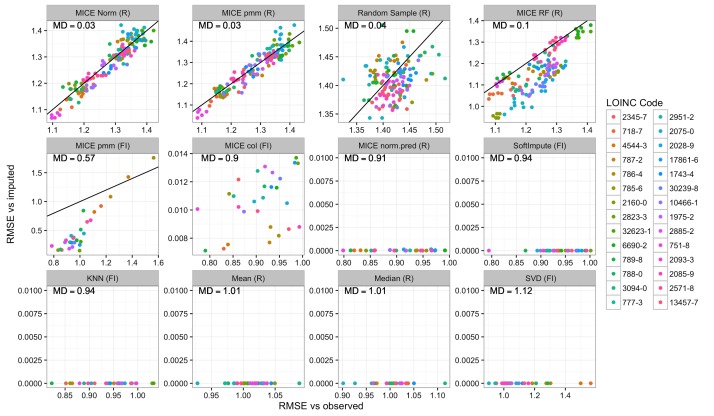
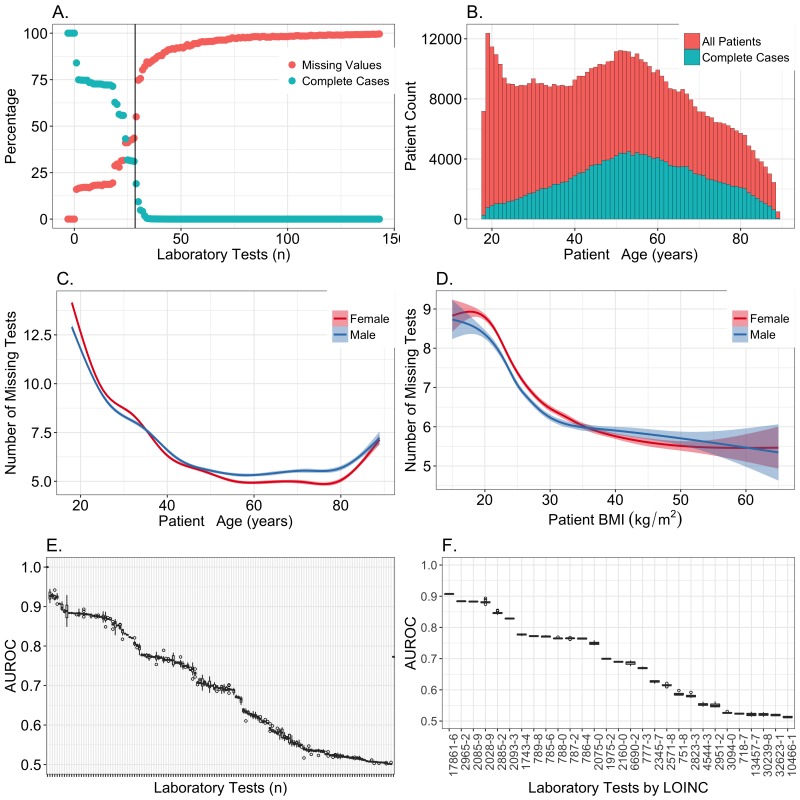
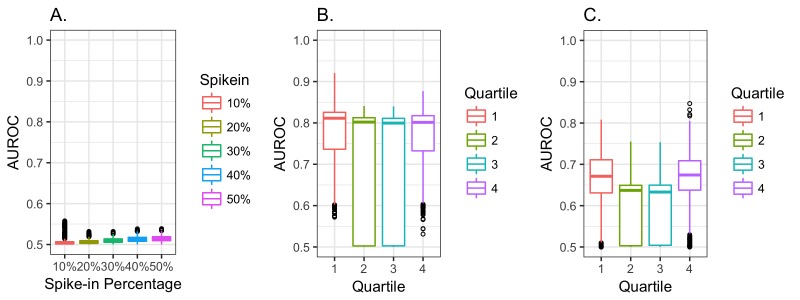
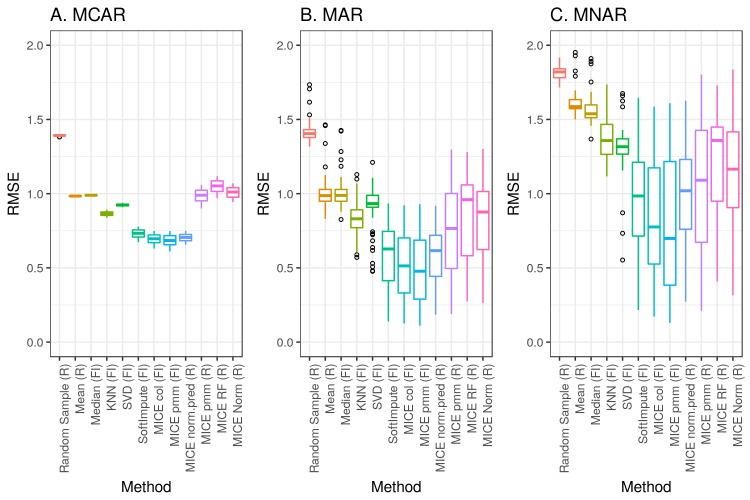
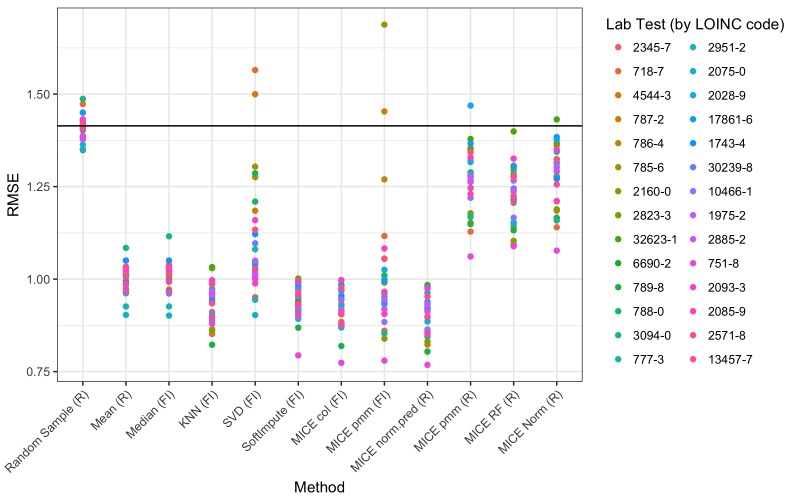
We analyzed clinical laboratory measures from 602,366 patients in the EHR of Geisinger Health System in Pennsylvania, USA. Using these data, we constructed a representative set of complete cases and assessed the performance of 12 different imputation methods for missing data that was simulated based on 4 mechanisms of missingness (missing completely at random, missing not at random, missing at random, and real data modelling).
Our results showed that several methods, including variations of Multivariate Imputation by Chained Equations (MICE) and softImpute, consistently imputed missing values with low error; however, only a subset of the MICE methods was suitable for multiple imputation.
The analyses we describe provide an outline of considerations for dealing with missing EHR data, steps that researchers can perform to characterize missingness within their own data, and an evaluation of methods that can be applied to impute clinical data. While the performance of methods may vary between datasets, the process we describe can be generalized to the majority of structured data types that exist in EHRs, and all of our methods and code are publicly available.
缺失数据对所有研究而言都是一项挑战;然而,对于基于电子健康记录(EHR)的分析来说尤其如此。未能恰当地考虑缺失数据可能导致有偏差的结果。虽然在插补方面已有大量的理论工作,并且现在有许多复杂的方法可用,但研究人员要恰当地实施这些方法仍然颇具挑战性。在此,我们提供关于何时以及如何对EHR实验室结果进行插补的详细程序。
本研究的目的是演示如何评估缺失机制,评估各种插补方法的性能,并描述可能遇到的一些最常见问题。
我们分析了美国宾夕法尼亚州盖辛格医疗系统EHR中602366名患者的临床实验室指标。利用这些数据,我们构建了一组具有代表性的完整病例,并评估了基于4种缺失机制(完全随机缺失、非随机缺失、随机缺失和真实数据建模)模拟的12种不同缺失数据插补方法的性能。
我们的结果表明,包括链式方程多元插补(MICE)变体和softImpute在内的几种方法,在插补缺失值时误差始终较低;然而,只有一部分MICE方法适用于多重插补。
我们所描述的分析提供了处理缺失EHR数据的考虑要点概述、研究人员可以采取的用于刻画自身数据中缺失情况的步骤,以及对可用于插补临床数据的方法的评估。虽然不同数据集上方法的性能可能有所不同,但我们所描述的过程可推广到EHR中存在的大多数结构化数据类型,并且我们所有的方法和代码都是公开可用的。