Department of Computing, Cork Institute of Technology, Cork, Ireland.
NSilico Life Sciences Ltd., Cork, Ireland.
Gigascience. 2018 Apr 1;7(4). doi: 10.1093/gigascience/giy036.
Bioinformatic research is increasingly dependent on large-scale datasets, accessed either from private or public repositories. An example of a public repository is National Center for Biotechnology Information's (NCBI's) Reference Sequence (RefSeq). These repositories must decide in what form to make their data available. Unstructured data can be put to almost any use but are limited in how access to them can be scaled. Highly structured data offer improved performance for specific algorithms but limit the wider usefulness of the data. We present an alternative: lightly structured data stored in Apache Kafka in a way that is amenable to parallel access and streamed processing, including subsequent transformations into more highly structured representations. We contend that this approach could provide a flexible and powerful nexus of bioinformatic data, bridging the gap between low structure on one hand, and high performance and scale on the other. To demonstrate this, we present a proof-of-concept version of NCBI's RefSeq database using this technology. We measure the performance and scalability characteristics of this alternative with respect to flat files.
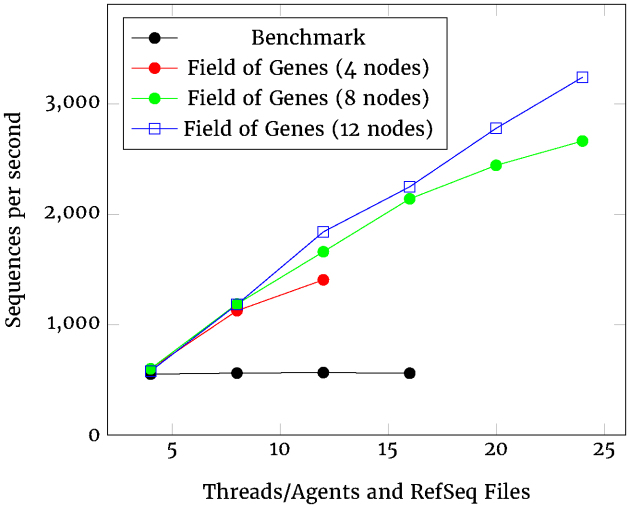
The proof of concept scales almost linearly as more compute nodes are added, outperforming the standard approach using files.
Apache Kafka merits consideration as a fast and more scalable but general-purpose way to store and retrieve bioinformatic data, for public, centralized reference datasets such as RefSeq and for private clinical and experimental data.
生物信息学研究越来越依赖于大规模数据集,可以从私人或公共存储库中获取。公共存储库的一个例子是国家生物技术信息中心(NCBI)的参考序列(RefSeq)。这些存储库必须决定以何种形式提供其数据。非结构化数据几乎可以用于任何用途,但在访问方式上存在限制。高度结构化的数据为特定算法提供了更好的性能,但限制了数据的更广泛用途。我们提出了一种替代方案:以可并行访问和流处理的方式存储在 Apache Kafka 中的轻度结构化数据,包括随后转换为更高度结构化的表示形式。我们认为,这种方法可以提供一个灵活而强大的生物信息学数据枢纽,弥合低结构与高性能和大规模之间的差距。为了证明这一点,我们使用这种技术展示了 NCBI 的 RefSeq 数据库的概念验证版本。我们针对平面文件测量了这种替代方案的性能和可伸缩性特征。
随着添加更多计算节点,该概念验证几乎呈线性扩展,性能优于使用文件的标准方法。
Apache Kafka 值得考虑作为一种快速且更具可伸缩性但用途广泛的方法,用于存储和检索生物信息学数据,适用于公共的、集中式参考数据集,如 RefSeq,以及私人的临床和实验数据。