Arguello Casteleiro Mercedes, Demetriou George, Read Warren, Fernandez Prieto Maria Jesus, Maroto Nava, Maseda Fernandez Diego, Nenadic Goran, Klein Julie, Keane John, Stevens Robert
School of Computer Science, University of Manchester, Manchester, UK.
Salford Languages, University of Salford, Salford, UK.
J Biomed Semantics. 2018 Apr 12;9(1):13. doi: 10.1186/s13326-018-0181-1.
Automatic identification of term variants or acceptable alternative free-text terms for gene and protein names from the millions of biomedical publications is a challenging task. Ontologies, such as the Cardiovascular Disease Ontology (CVDO), capture domain knowledge in a computational form and can provide context for gene/protein names as written in the literature. This study investigates: 1) if word embeddings from Deep Learning algorithms can provide a list of term variants for a given gene/protein of interest; and 2) if biological knowledge from the CVDO can improve such a list without modifying the word embeddings created.
We have manually annotated 105 gene/protein names from 25 PubMed titles/abstracts and mapped them to 79 unique UniProtKB entries corresponding to gene and protein classes from the CVDO. Using more than 14 M PubMed articles (titles and available abstracts), word embeddings were generated with CBOW and Skip-gram. We setup two experiments for a synonym detection task, each with four raters, and 3672 pairs of terms (target term and candidate term) from the word embeddings created. For Experiment I, the target terms for 64 UniProtKB entries were those that appear in the titles/abstracts; Experiment II involves 63 UniProtKB entries and the target terms are a combination of terms from PubMed titles/abstracts with terms (i.e. increased context) from the CVDO protein class expressions and labels.
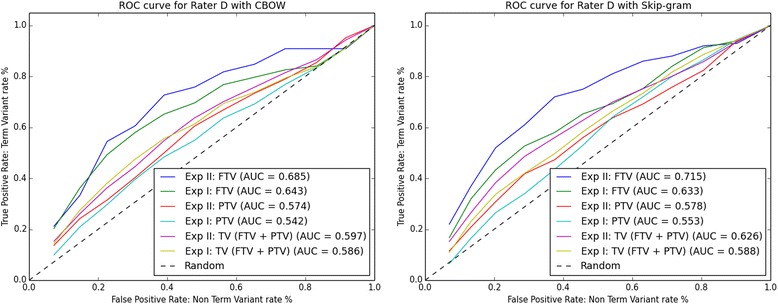
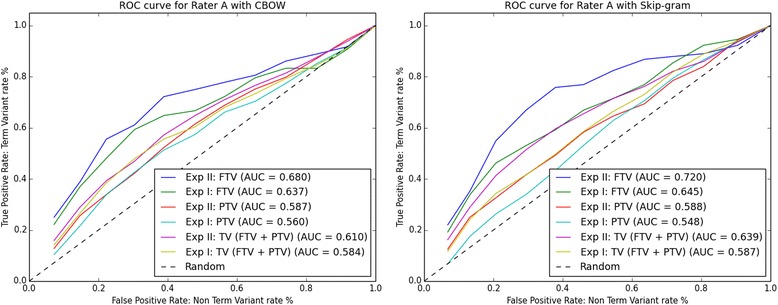
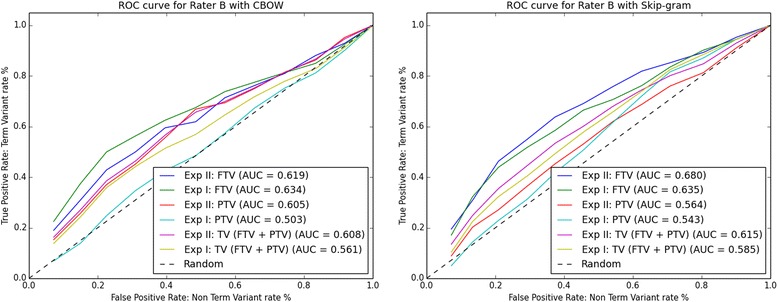
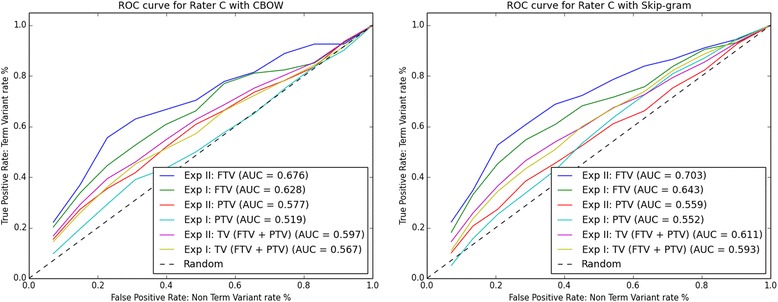
In Experiment I, Skip-gram finds term variants (full and/or partial) for 89% of the 64 UniProtKB entries, while CBOW finds term variants for 67%. In Experiment II (with the aid of the CVDO), Skip-gram finds term variants for 95% of the 63 UniProtKB entries, while CBOW finds term variants for 78%. Combining the results of both experiments, Skip-gram finds term variants for 97% of the 79 UniProtKB entries, while CBOW finds term variants for 81%.
This study shows performance improvements for both CBOW and Skip-gram on a gene/protein synonym detection task by adding knowledge formalised in the CVDO and without modifying the word embeddings created. Hence, the CVDO supplies context that is effective in inducing term variability for both CBOW and Skip-gram while reducing ambiguity. Skip-gram outperforms CBOW and finds more pertinent term variants for gene/protein names annotated from the scientific literature.
从数百万篇生物医学出版物中自动识别基因和蛋白质名称的术语变体或可接受的替代自由文本术语是一项具有挑战性的任务。本体,如心血管疾病本体(CVDO),以计算形式捕获领域知识,并可为文献中所写的基因/蛋白质名称提供上下文。本研究调查:1)深度学习算法中的词嵌入能否为给定的感兴趣基因/蛋白质提供术语变体列表;2)CVDO中的生物知识能否在不修改所创建词嵌入的情况下改进这样的列表。
我们从25篇PubMed标题/摘要中手动注释了105个基因/蛋白质名称,并将它们映射到79个唯一的UniProtKB条目,这些条目对应于CVDO中的基因和蛋白质类别。使用超过1400万篇PubMed文章(标题和可用摘要),通过连续词袋模型(CBOW)和跳字模型(Skip-gram)生成词嵌入。我们针对同义词检测任务设置了两个实验,每个实验有四名评分者,以及从所创建的词嵌入中选取的3672对术语(目标术语和候选术语)。对于实验I,64个UniProtKB条目的目标术语是那些出现在标题/摘要中的术语;实验II涉及63个UniProtKB条目,目标术语是来自PubMed标题/摘要的术语与来自CVDO蛋白质类别表达和标签的术语(即增加的上下文)的组合。
在实验I中,跳字模型为64个UniProtKB条目中的89%找到了术语变体(完整和/或部分),而连续词袋模型为67%找到了术语变体。在实验II(借助CVDO)中,跳字模型为63个UniProtKB条目中的95%找到了术语变体,而连续词袋模型为78%找到了术语变体。综合两个实验的结果,跳字模型为79个UniProtKB条目中的97%找到了术语变体,而连续词袋模型为81%找到了术语变体。
本研究表明,通过添加CVDO中形式化的知识且不修改所创建的词嵌入,连续词袋模型和跳字模型在基因/蛋白质同义词检测任务上的性能都有所提高。因此,CVDO提供的上下文对于连续词袋模型和跳字模型在诱导术语变异性同时减少歧义方面是有效的。跳字模型优于连续词袋模型,并且为从科学文献中注释的基因/蛋白质名称找到了更多相关的术语变体。