National Center for Biotechnology Information (NCBI), National Library of Medicine (NLM), National Institutes of Health (NIH), 8600 Rockville Pike, Bethesda, MD 20894, USA.
Nucleic Acids Res. 2018 Jul 2;46(W1):W530-W536. doi: 10.1093/nar/gky355.
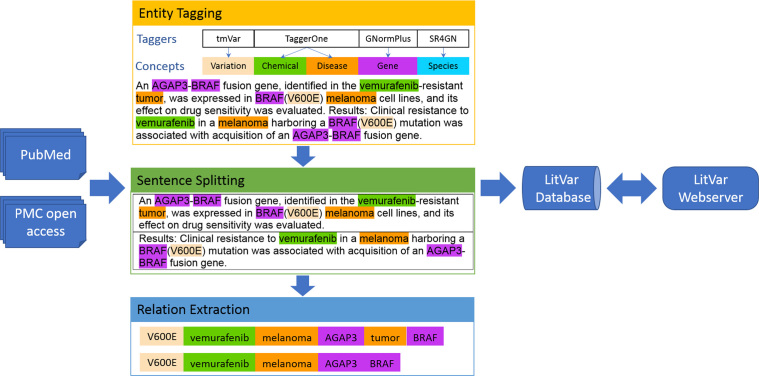
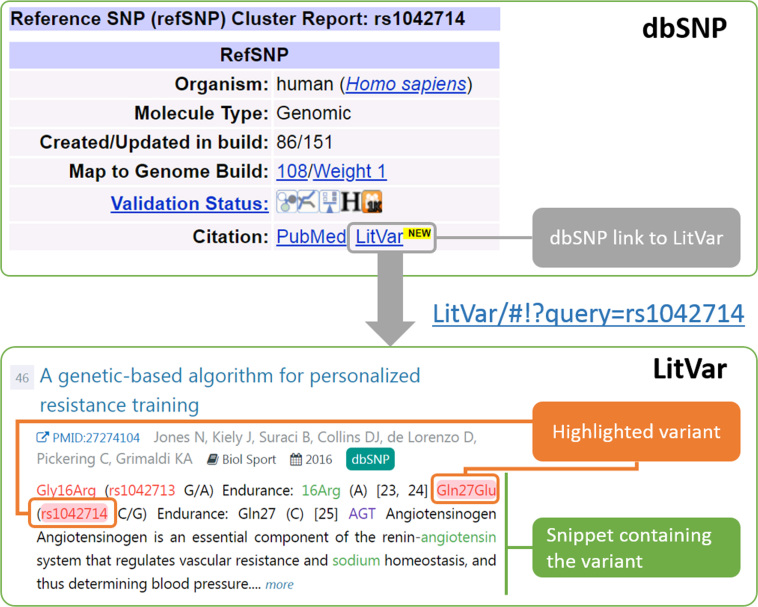
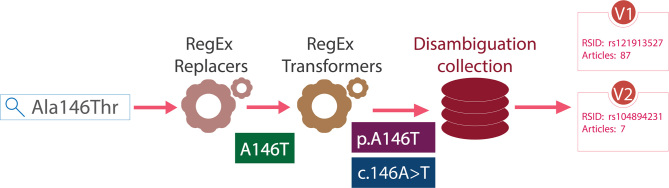
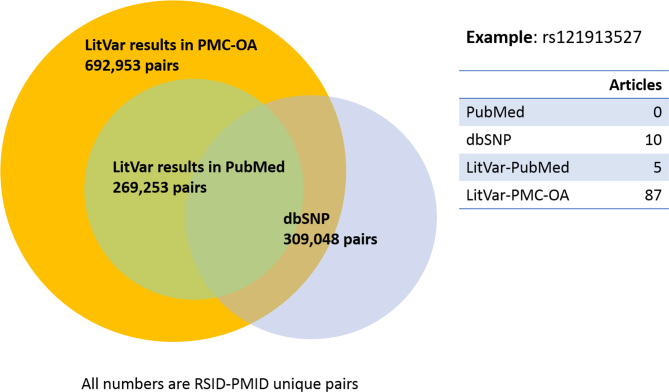
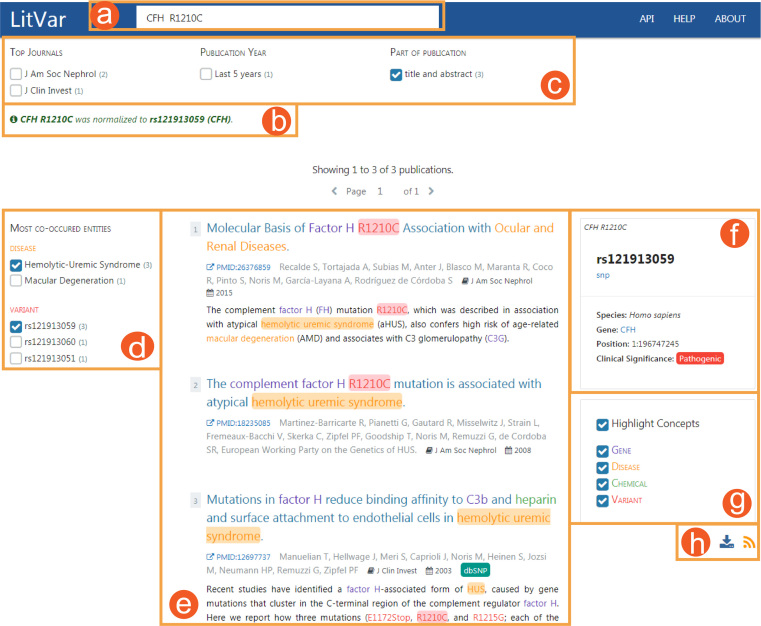
The identification and interpretation of genomic variants play a key role in the diagnosis of genetic diseases and related research. These tasks increasingly rely on accessing relevant manually curated information from domain databases (e.g. SwissProt or ClinVar). However, due to the sheer volume of medical literature and high cost of expert curation, curated variant information in existing databases are often incomplete and out-of-date. In addition, the same genetic variant can be mentioned in publications with various names (e.g. 'A146T' versus 'c.436G>A' versus 'rs121913527'). A search in PubMed using only one name usually cannot retrieve all relevant articles for the variant of interest. Hence, to help scientists, healthcare professionals, and database curators find the most up-to-date published variant research, we have developed LitVar for the search and retrieval of standardized variant information. In addition, LitVar uses advanced text mining techniques to compute and extract relationships between variants and other associated entities such as diseases and chemicals/drugs. LitVar is publicly available at https://www.ncbi.nlm.nih.gov/CBBresearch/Lu/Demo/LitVar.
基因组变异的鉴定和解释在遗传疾病的诊断和相关研究中起着关键作用。这些任务越来越依赖于从领域数据库(例如 SwissProt 或 ClinVar)访问相关的手动整理信息。然而,由于医学文献的数量庞大且专家整理成本高昂,现有数据库中的经整理的变异信息往往不完整且已过时。此外,同一个遗传变异在出版物中可能会有不同的名称(例如 'A146T' 与 'c.436G>A' 与 'rs121913527')。仅使用一个名称在 PubMed 中进行搜索通常无法检索到感兴趣变异的所有相关文章。因此,为了帮助科学家、医疗保健专业人员和数据库整理人员找到最新的已发表的变异研究,我们开发了 LitVar 来搜索和检索标准化的变异信息。此外,LitVar 使用先进的文本挖掘技术来计算和提取变异与其他相关实体(如疾病和化学物质/药物)之间的关系。LitVar 可在 https://www.ncbi.nlm.nih.gov/CBBresearch/Lu/Demo/LitVar 上公开获取。