Center for Biological Sequence Analysis, Department of Bio and Health Informatics, Technical University of Denmark, Lyngby, Denmark.
Novo Nordisk Foundation Center for Protein Research, Faculty of Health and Medical Sciences, University of Copenhagen, Copenhagen, Denmark.
PLoS Comput Biol. 2018 Feb 15;14(2):e1005962. doi: 10.1371/journal.pcbi.1005962. eCollection 2018 Feb.
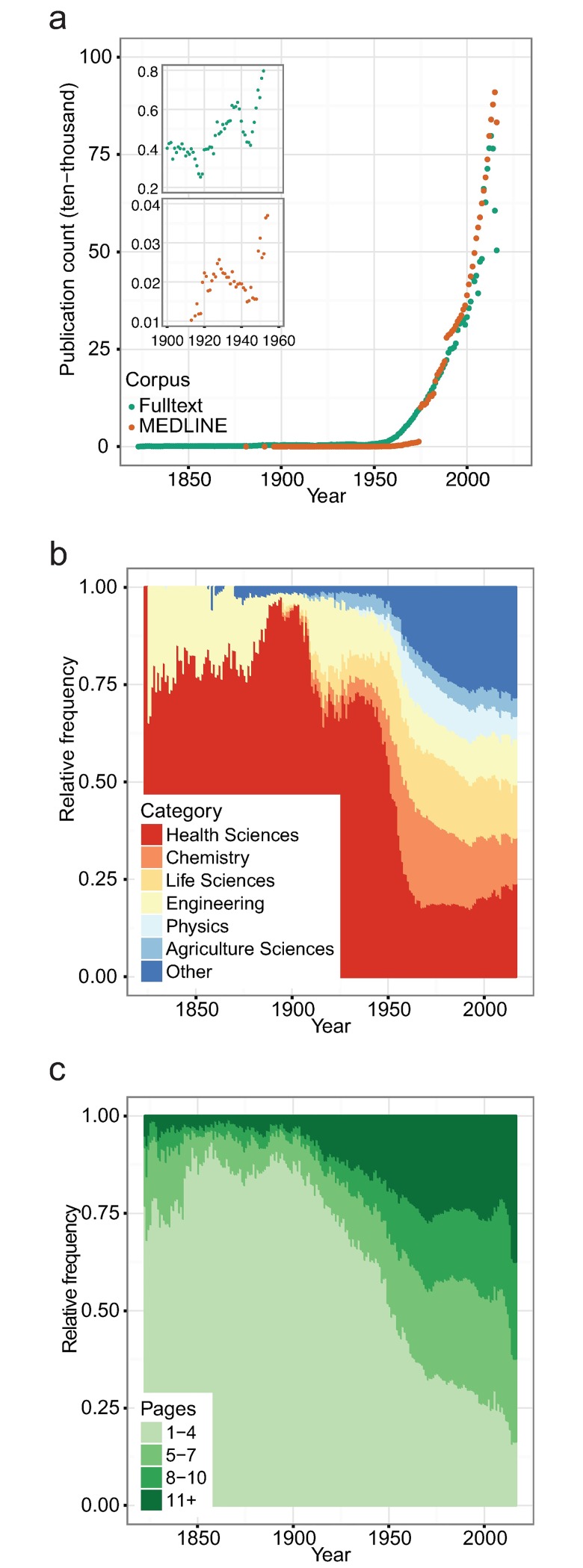
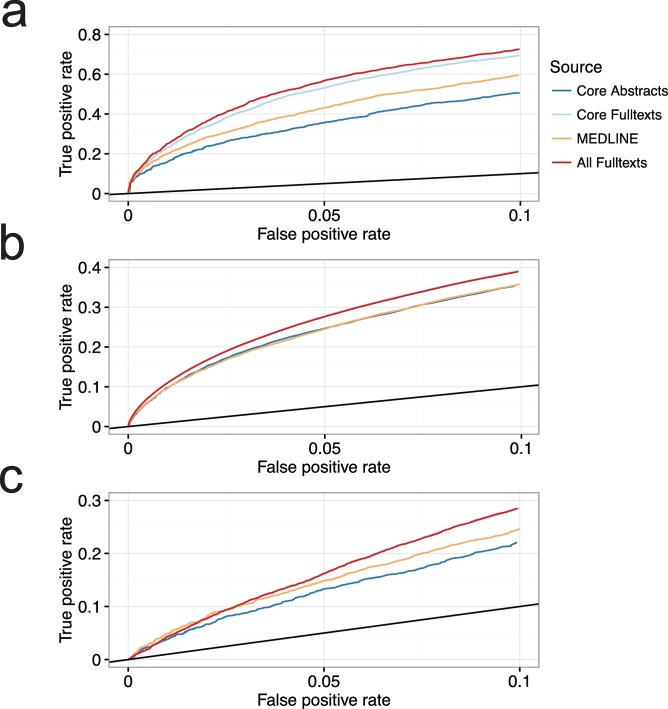
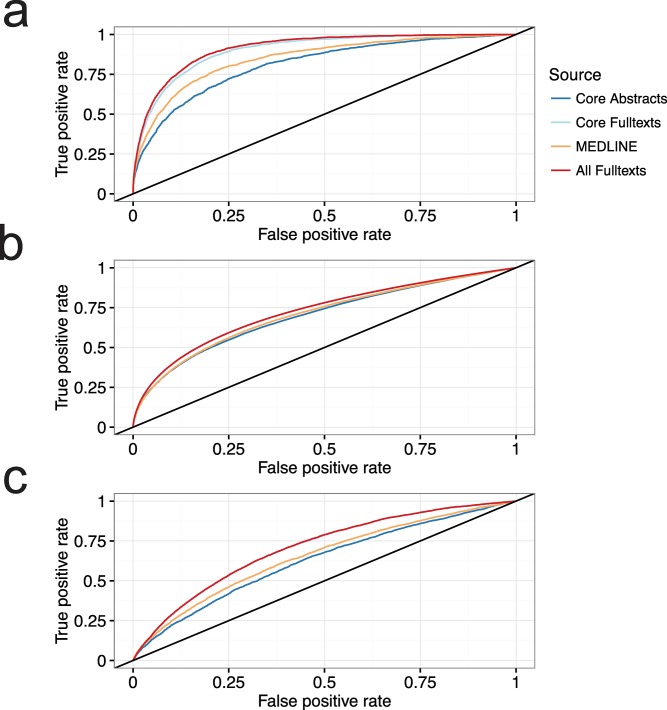
Across academia and industry, text mining has become a popular strategy for keeping up with the rapid growth of the scientific literature. Text mining of the scientific literature has mostly been carried out on collections of abstracts, due to their availability. Here we present an analysis of 15 million English scientific full-text articles published during the period 1823-2016. We describe the development in article length and publication sub-topics during these nearly 250 years. We showcase the potential of text mining by extracting published protein-protein, disease-gene, and protein subcellular associations using a named entity recognition system, and quantitatively report on their accuracy using gold standard benchmark data sets. We subsequently compare the findings to corresponding results obtained on 16.5 million abstracts included in MEDLINE and show that text mining of full-text articles consistently outperforms using abstracts only.
在学术界和工业界,文本挖掘已成为跟上科学文献快速增长的一种流行策略。由于摘要的可用性,科学文献的文本挖掘主要在摘要集合上进行。在这里,我们分析了 1500 万篇发表于 1823 年至 2016 年期间的英文科学全文文章。我们描述了近 250 年来文章长度和出版子主题的发展情况。我们展示了使用命名实体识别系统提取已发表的蛋白质-蛋白质、疾病-基因和蛋白质亚细胞关联的潜力,并使用黄金标准基准数据集定量报告其准确性。随后,我们将这些发现与包含在 MEDLINE 中的 1650 万摘要的相应结果进行了比较,并表明仅使用摘要进行文本挖掘始终优于全文文章的文本挖掘。