Kornfield Rachel, Sarma Prathusha K, Shah Dhavan V, McTavish Fiona, Landucci Gina, Pe-Romashko Klaren, Gustafson David H
School of Journalism and Mass Communication, University of Wisconsin-Madison, Madison, WI, United States.
Department of Electrical & Computer Engineering, University of Wisconsin-Madison, Madison, WI, United States.
J Med Internet Res. 2018 Jun 12;20(6):e10136. doi: 10.2196/10136.
Online discussion forums allow those in addiction recovery to seek help through text-based messages, including when facing triggers to drink or use drugs. Trained staff (or "moderators") may participate within these forums to offer guidance and support when participants are struggling but must expend considerable effort to continually review new content. Demands on moderators limit the scalability of evidence-based digital health interventions.
Automated identification of recovery problems could allow moderators to engage in more timely and efficient ways with participants who are struggling. This paper aimed to investigate whether computational linguistics and supervised machine learning can be applied to successfully flag, in real time, those discussion forum messages that moderators find most concerning.
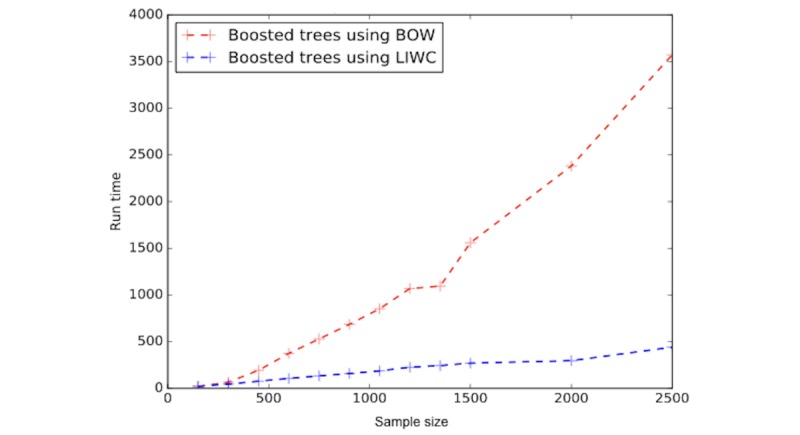
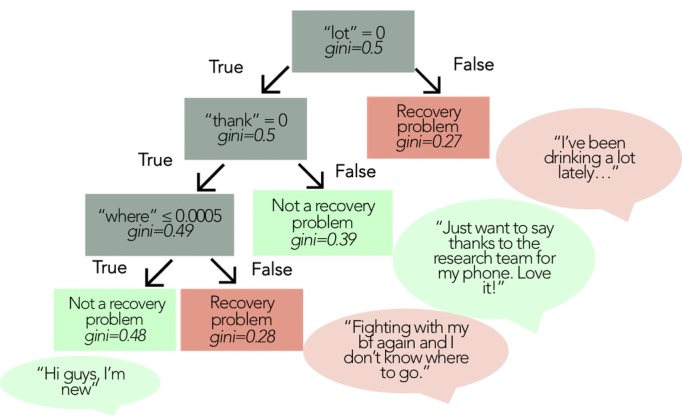
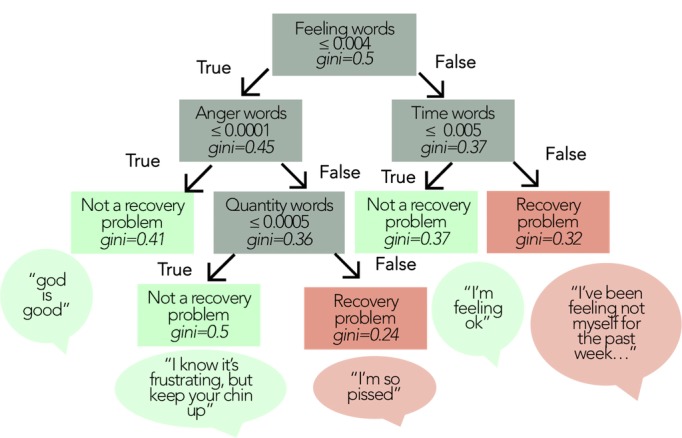
Training data came from a trial of a mobile phone-based health intervention for individuals in recovery from alcohol use disorder, with human coders labeling discussion forum messages according to whether or not authors mentioned problems in their recovery process. Linguistic features of these messages were extracted via several computational techniques: (1) a Bag-of-Words approach, (2) the dictionary-based Linguistic Inquiry and Word Count program, and (3) a hybrid approach combining the most important features from both Bag-of-Words and Linguistic Inquiry and Word Count. These features were applied within binary classifiers leveraging several methods of supervised machine learning: support vector machines, decision trees, and boosted decision trees. Classifiers were evaluated in data from a later deployment of the recovery support intervention.
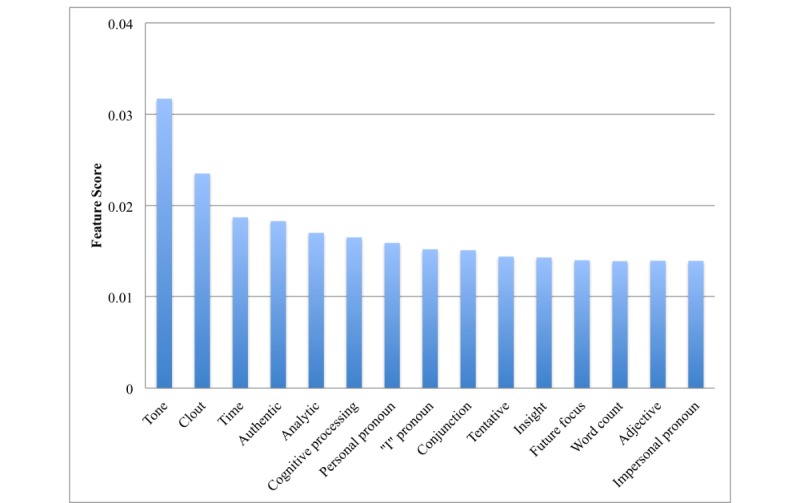
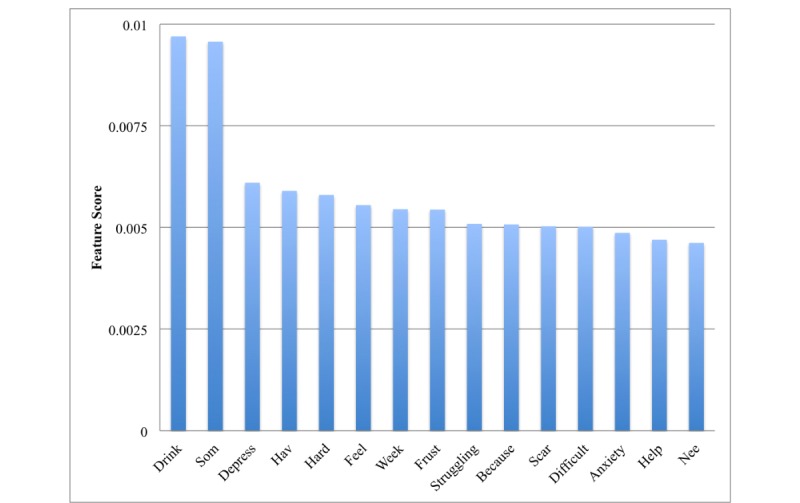
To distinguish recovery problem disclosures, the Bag-of-Words approach relied on domain-specific language, including words explicitly linked to substance use and mental health ("drink," "relapse," "depression," and so on), whereas the Linguistic Inquiry and Word Count approach relied on language characteristics such as tone, affect, insight, and presence of quantifiers and time references, as well as pronouns. A boosted decision tree classifier, utilizing features from both Bag-of-Words and Linguistic Inquiry and Word Count performed best in identifying problems disclosed within the discussion forum, achieving 88% sensitivity and 82% specificity in a separate cohort of patients in recovery.
Differences in language use can distinguish messages disclosing recovery problems from other message types. Incorporating machine learning models based on language use allows real-time flagging of concerning content such that trained staff may engage more efficiently and focus their attention on time-sensitive issues.
在线讨论论坛使处于成瘾康复期的人能够通过文本信息寻求帮助,包括在面临饮酒或使用毒品的诱因时。训练有素的工作人员(或“版主”)可能会参与这些论坛,在参与者遇到困难时提供指导和支持,但必须花费大量精力持续审查新内容。对版主的要求限制了循证数字健康干预措施的可扩展性。
自动识别康复问题可以使版主以更及时、高效的方式与遇到困难的参与者互动。本文旨在研究计算语言学和监督机器学习是否可以应用于实时成功标记版主认为最值得关注的那些讨论论坛信息。
训练数据来自一项针对酒精使用障碍康复者的基于手机的健康干预试验,由人工编码员根据作者是否提及康复过程中的问题对讨论论坛信息进行标注。这些信息的语言特征通过几种计算技术提取:(1)词袋法,(2)基于词典的语言查询与字数统计程序,以及(3)一种结合词袋法和语言查询与字数统计中最重要特征的混合方法。这些特征应用于利用几种监督机器学习方法的二元分类器中:支持向量机、决策树和增强决策树。分类器在康复支持干预措施后期部署的数据中进行评估。
为了区分康复问题披露,词袋法依赖于特定领域的语言,包括与物质使用和心理健康明确相关的词汇(“饮酒”、“复发”、“抑郁”等),而语言查询与字数统计方法依赖于语言特征,如语气、情感、洞察力、量词和时间参照的存在以及代词的使用。一个利用词袋法和语言查询与字数统计特征的增强决策树分类器在识别讨论论坛中披露的问题方面表现最佳,在另一组康复患者中实现了8