Departamento de Biologia Geral, Universidade Federal de Minas Gerais, Belo Horizonte, Minas Gerais, 31270-901, Brazil.
Instituto Mario Penna, Núcleo de Ensino e Pesquisa, Belo Horizonte, Minas Gerais, 30380-472, Brazil.
Genome Res. 2018 Jul;28(7):1090-1095. doi: 10.1101/gr.225458.117. Epub 2018 Jun 14.
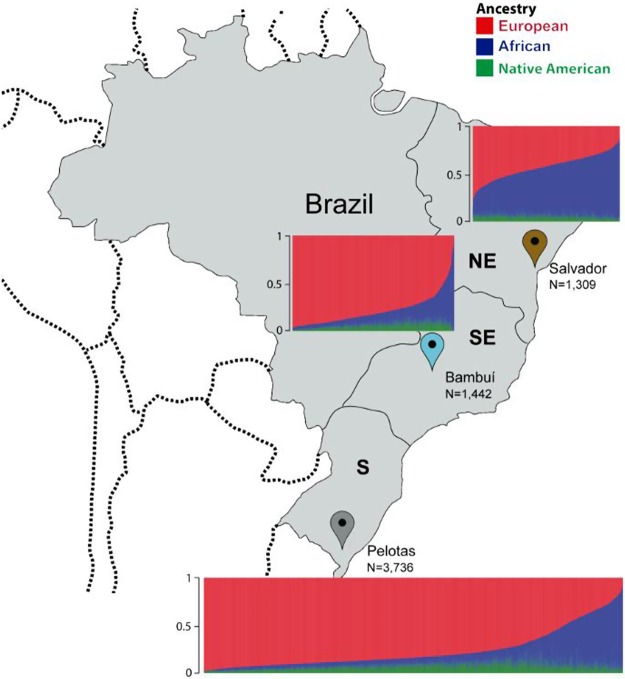
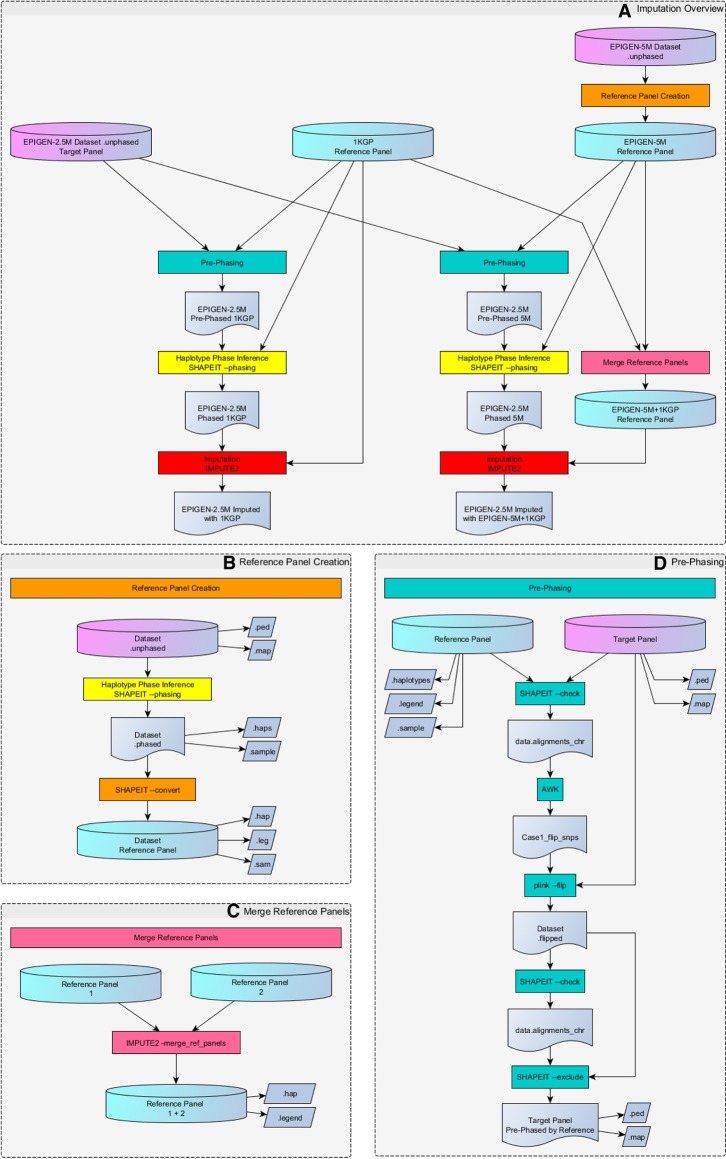
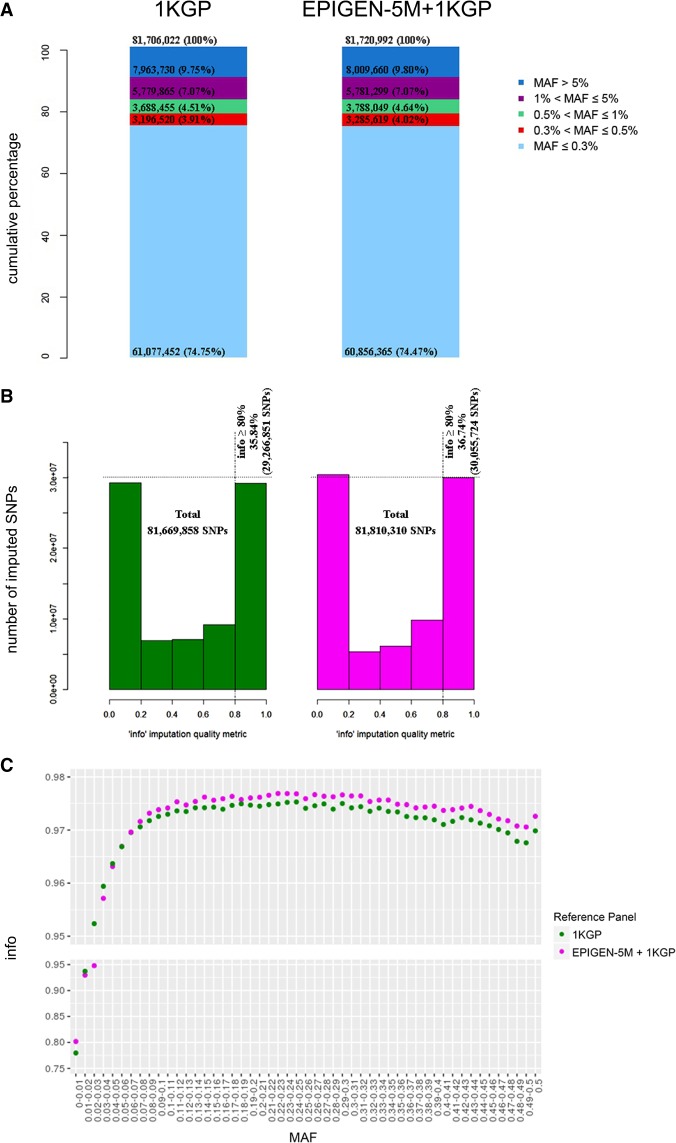
EPIGEN-Brazil is one of the largest Latin American initiatives at the interface of human genomics, public health, and computational biology. Here, we present two resources to address two challenges to the global dissemination of precision medicine and the development of the bioinformatics know-how to support it. To address the underrepresentation of non-European individuals in human genome diversity studies, we present the EPIGEN-5M+1KGP imputation panel-the fusion of the public 1000 Genomes Project (1KGP) Phase 3 imputation panel with haplotypes derived from the EPIGEN-5M data set (a product of the genotyping of 4.3 million SNPs in 265 admixed individuals from the EPIGEN-Brazil Initiative). When we imputed a target SNPs data set (6487 admixed individuals genotyped for 2.2 million SNPs from the EPIGEN-Brazil project) with the EPIGEN-5M+1KGP panel, we gained 140,452 more SNPs in total than when using the 1KGP Phase 3 panel alone and 788,873 additional high confidence SNPs ( ≥ 0.8). Thus, the major effect of the inclusion of the EPIGEN-5M data set in this new imputation panel is not only to gain more SNPs but also to improve the quality of imputation. To address the lack of transparency and reproducibility of bioinformatics protocols, we present a conceptual Scientific Workflow in the form of a website that models the scientific process (by including publications, flowcharts, masterscripts, documents, and bioinformatics protocols), making it accessible and interactive. Its applicability is shown in the context of the development of our EPIGEN-5M+1KGP imputation panel. The Scientific Workflow also serves as a repository of bioinformatics resources.
EPIGEN-Brazil 是人类基因组学、公共卫生和计算生物学交叉领域中最大的拉丁美洲倡议之一。在这里,我们提出了两个资源,以解决精准医学全球传播和支持它的生物信息学专业知识发展所面临的两个挑战。为了解决人类基因组多样性研究中代表性不足的非欧洲个体的问题,我们提出了 EPIGEN-5M+1KGP imputation 面板——将公共的 1000 基因组计划(1KGP)第三阶段 imputation 面板与来自 EPIGEN-5M 数据集的单倍型融合在一起(EPIGEN-5M 数据集是 265 名混合个体中 430 万个 SNP 基因分型的产物,来自 EPIGEN-Brazil 倡议)。当我们使用 EPIGEN-5M+1KGP 面板对一个目标 SNP 数据集(6487 名混合个体的 220 万个 SNP 进行基因分型,来自 EPIGEN-Brazil 项目)进行 imputation 时,我们总共获得了 140452 个额外的 SNP,比单独使用 1KGP 第三阶段面板时多了 140452 个 SNP,并且还获得了 788873 个额外的高置信度 SNP(≥0.8)。因此,在这个新的 imputation 面板中纳入 EPIGEN-5M 数据集的主要影响不仅是获得更多的 SNP,而且还提高了 imputation 的质量。为了解决生物信息学协议缺乏透明度和可重复性的问题,我们以网站的形式提出了一个概念性的科学工作流程,该流程通过包括出版物、流程图、主脚本、文档和生物信息学协议来模拟科学过程,使其具有可访问性和交互性。它的适用性在我们开发 EPIGEN-5M+1KGP imputation 面板的背景下得到了展示。科学工作流程还充当生物信息学资源的存储库。