Department of Pharmaceutical Biosciences and Science for Life Laboratory, Uppsala University, Uppsala, Sweden.
Department of Medical Sciences, Clinical Chemistry, Uppsala University, Uppsala, Sweden.
Bioinformatics. 2019 Mar 1;35(5):839-846. doi: 10.1093/bioinformatics/bty699.
Computational biologists face many challenges related to data size, and they need to manage complicated analyses often including multiple stages and multiple tools, all of which must be deployed to modern infrastructures. To address these challenges and maintain reproducibility of results, researchers need (i) a reliable way to run processing stages in any computational environment, (ii) a well-defined way to orchestrate those processing stages and (iii) a data management layer that tracks data as it moves through the processing pipeline.
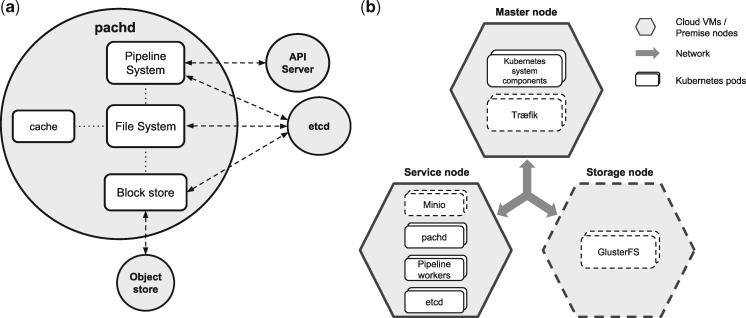
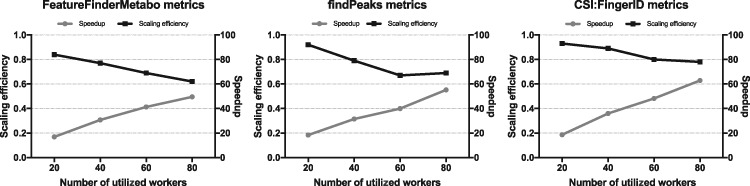
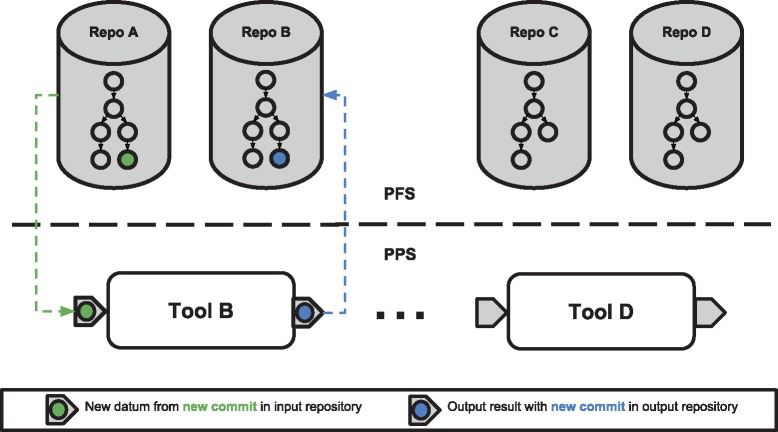
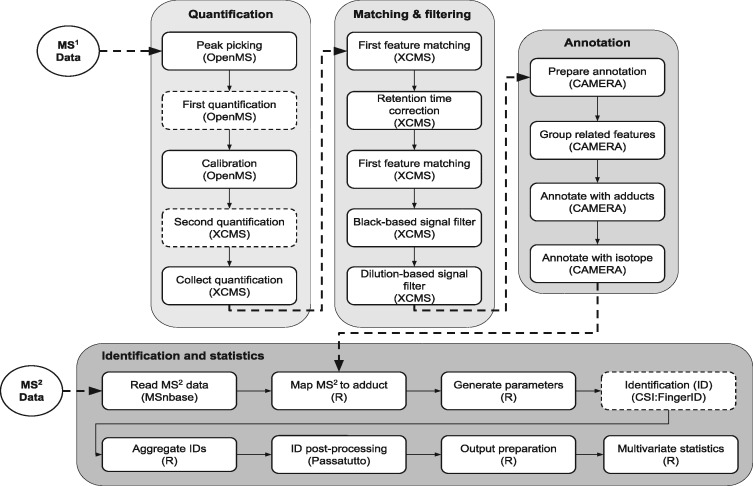
Pachyderm is an open-source workflow system and data management framework that fulfils these needs by creating a data pipelining and data versioning layer on top of projects from the container ecosystem, having Kubernetes as the backbone for container orchestration. We adapted Pachyderm and demonstrated its attractive properties in bioinformatics. A Helm Chart was created so that researchers can use Pachyderm in multiple scenarios. The Pachyderm File System was extended to support block storage. A wrapper for initiating Pachyderm on cloud-agnostic virtual infrastructures was created. The benefits of Pachyderm are illustrated via a large metabolomics workflow, demonstrating that Pachyderm enables efficient and sustainable data science workflows while maintaining reproducibility and scalability.
Pachyderm is available from https://github.com/pachyderm/pachyderm. The Pachyderm Helm Chart is available from https://github.com/kubernetes/charts/tree/master/stable/pachyderm. Pachyderm is available out-of-the-box from the PhenoMeNal VRE (https://github.com/phnmnl/KubeNow-plugin) and general Kubernetes environments instantiated via KubeNow. The code of the workflow used for the analysis is available on GitHub (https://github.com/pharmbio/LC-MS-Pachyderm).
Supplementary data are available at Bioinformatics online.
计算生物学家面临许多与数据大小相关的挑战,他们需要管理复杂的分析,通常包括多个阶段和多个工具,所有这些都必须部署到现代基础架构中。为了应对这些挑战并保持结果的可重复性,研究人员需要 (i) 在任何计算环境中运行处理阶段的可靠方法,(ii) 定义良好的方法来协调这些处理阶段,以及 (iii) 一个数据管理层,用于跟踪数据在处理管道中的移动方式。
Pachyderm 是一个开源工作流系统和数据管理框架,它通过在容器生态系统中的项目之上创建一个数据管道和数据版本控制层,并以 Kubernetes 作为容器编排的骨干,满足了这些需求。我们对 Pachyderm 进行了改编,并在生物信息学中展示了其吸引人的特性。创建了一个 Helm 图表,以便研究人员可以在多种场景中使用 Pachyderm。扩展了 Pachyderm 文件系统以支持块存储。创建了一个用于在无云虚拟基础架构上启动 Pachyderm 的包装器。通过一个大型代谢组学工作流程说明了 Pachyderm 的优势,表明 Pachyderm 可以在保持可重复性和可扩展性的同时,实现高效和可持续的数据科学工作流程。
Pachyderm 可从 https://github.com/pachyderm/pachyderm 获得。Pachyderm Helm 图表可从 https://github.com/kubernetes/charts/tree/master/stable/pachyderm 获得。Pachyderm 可从 PhenoMeNal VRE(https://github.com/phnmnl/KubeNow-plugin)和通过 KubeNow 实例化的一般 Kubernetes 环境中获得。用于分析的工作流程的代码可在 GitHub 上获得(https://github.com/pharmbio/LC-MS-Pachyderm)。
补充数据可在《生物信息学》在线获得。