Department of Information Technology, Uppsala University, Lägerhyddsvägen 2, 75237 Uppsala, Sweden.
Department of Pharmaceutical Biosciences, Uppsala University, Husargatan 3, 75237, Uppsala, Sweden.
Gigascience. 2021 Mar 19;10(3). doi: 10.1093/gigascience/giab018.
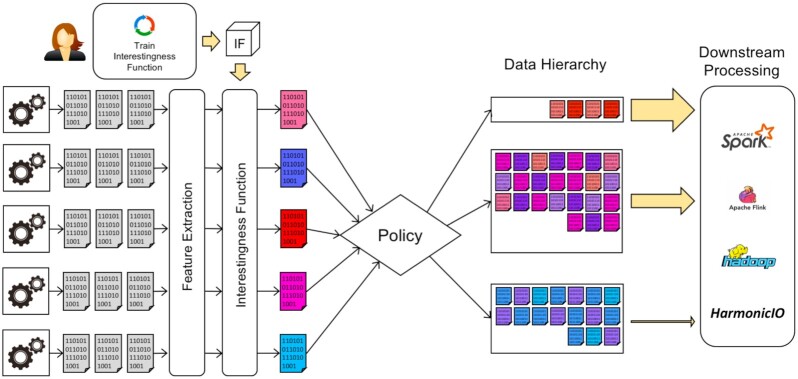
Large streamed datasets, characteristic of life science applications, are often resource-intensive to process, transport and store. We propose a pipeline model, a design pattern for scientific pipelines, where an incoming stream of scientific data is organized into a tiered or ordered "data hierarchy". We introduce the HASTE Toolkit, a proof-of-concept cloud-native software toolkit based on this pipeline model, to partition and prioritize data streams to optimize use of limited computing resources.
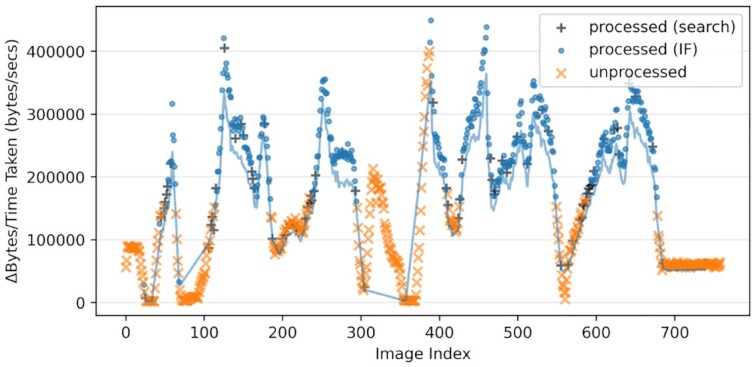
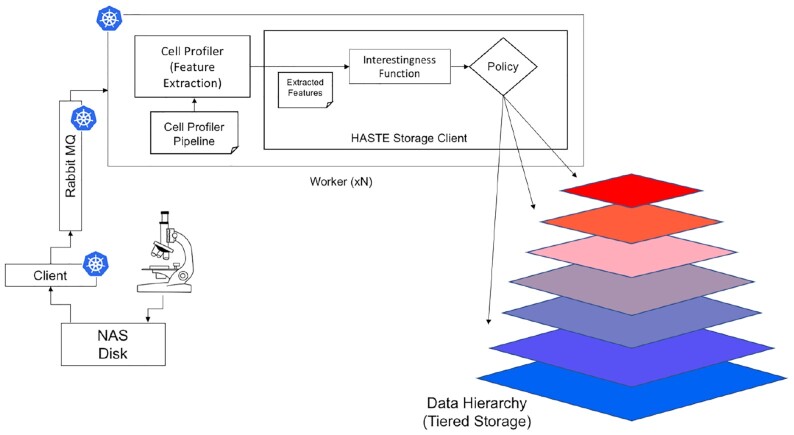
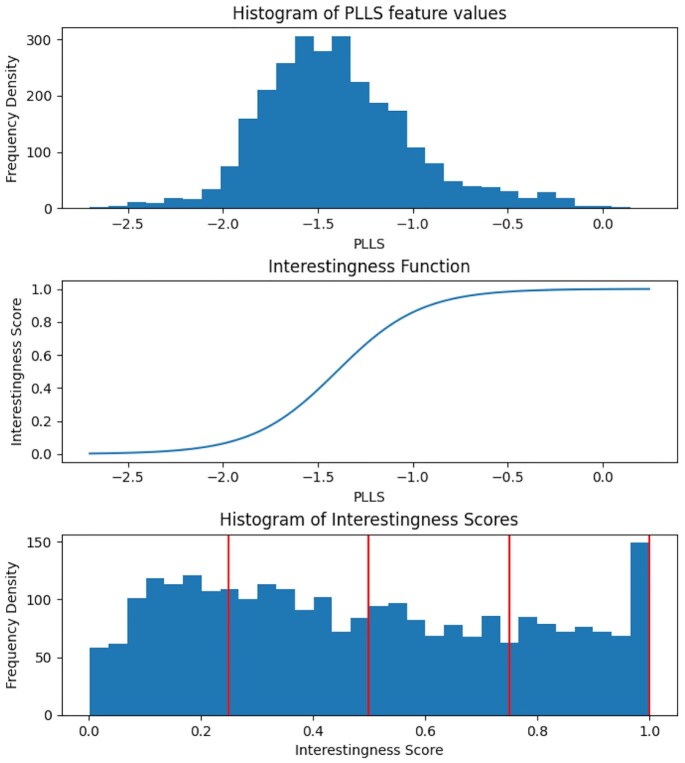
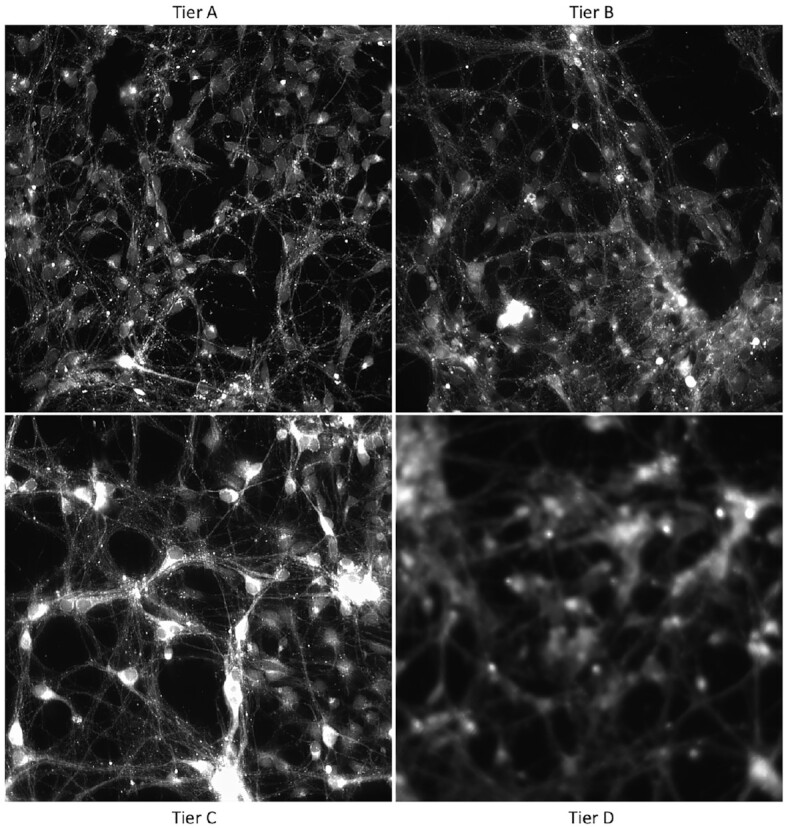
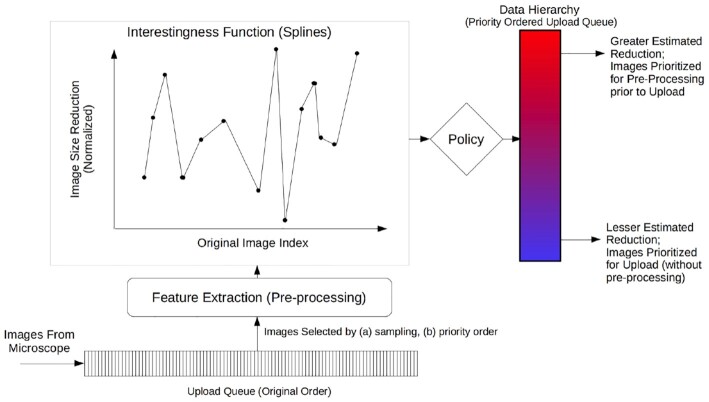
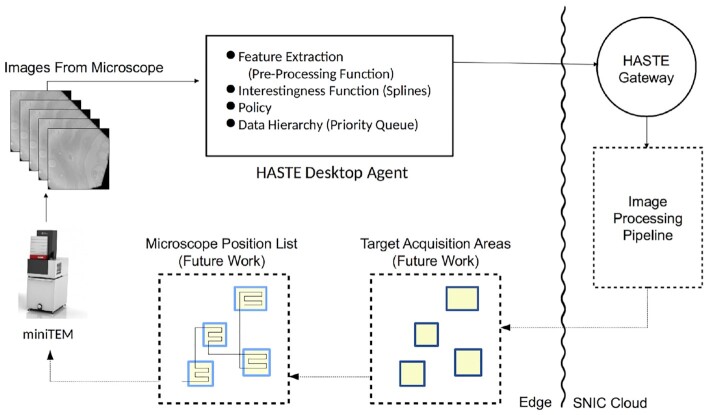
In our pipeline model, an "interestingness function" assigns an interestingness score to data objects in the stream, inducing a data hierarchy. From this score, a "policy" guides decisions on how to prioritize computational resource use for a given object. The HASTE Toolkit is a collection of tools to adopt this approach. We evaluate with 2 microscopy imaging case studies. The first is a high content screening experiment, where images are analyzed in an on-premise container cloud to prioritize storage and subsequent computation. The second considers edge processing of images for upload into the public cloud for real-time control of a transmission electron microscope.
Through our evaluation, we created smart data pipelines capable of effective use of storage, compute, and network resources, enabling more efficient data-intensive experiments. We note a beneficial separation between scientific concerns of data priority, and the implementation of this behaviour for different resources in different deployment contexts. The toolkit allows intelligent prioritization to be `bolted on' to new and existing systems - and is intended for use with a range of technologies in different deployment scenarios.
生命科学应用中的大型流式数据集通常在处理、传输和存储方面都需要大量的资源。我们提出了一种流水线模型,即科学流水线的设计模式,其中传入的科学数据流被组织成分层或有序的“数据层次结构”。我们引入了 HASTE 工具包,这是一个基于该流水线模型的概念验证云原生软件工具包,用于划分和优先处理数据流,以优化有限计算资源的使用。
在我们的流水线模型中,“有趣函数”为流中的数据对象分配有趣分数,从而引出数据层次结构。根据该分数,“策略”指导针对给定对象如何优先使用计算资源的决策。HASTE 工具包是采用这种方法的一组工具。我们通过 2 个显微镜成像案例研究进行评估。第一个是高内涵筛选实验,其中在本地容器云中分析图像,以优先存储和后续计算。第二个考虑边缘处理图像,以便上传到公共云中实时控制透射电子显微镜。
通过评估,我们创建了能够有效利用存储、计算和网络资源的智能数据流管道,从而使数据密集型实验更加高效。我们注意到数据优先级的科学问题与不同部署环境中不同资源的这种行为的实现之间的有益分离。该工具包允许将智能优先级划分“固定”到新的和现有的系统中-并旨在与不同部署场景中的各种技术一起使用。