Department of Analytical, Environmental & Forensic Sciences, School of Population Health & Environmental Sciences, Faculty of Life Sciences and Medicine, King's College London, 150 Stamford Street, London SE1 9NH, UK.
Department of Applied Sciences, Northumbria University, Newcastle Upon Tyne NE1 8ST, UK.
Sci Total Environ. 2019 Jan 15;648:80-89. doi: 10.1016/j.scitotenv.2018.08.122. Epub 2018 Aug 10.
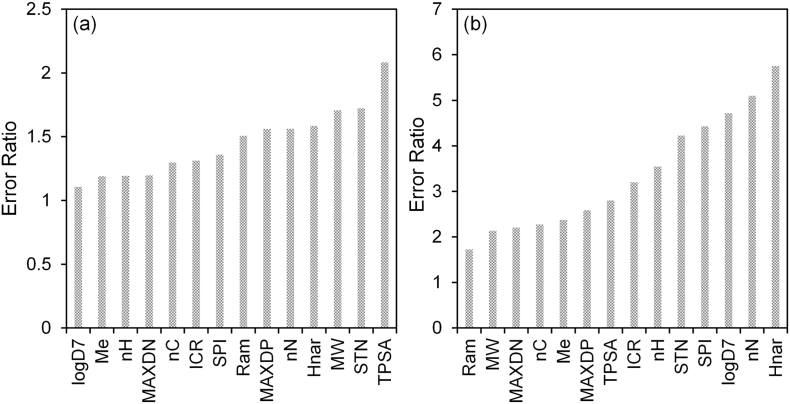
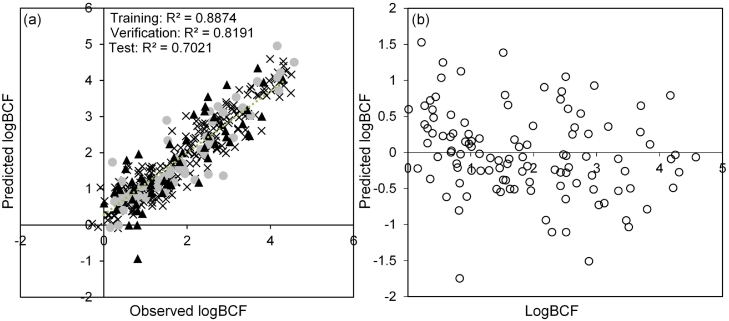
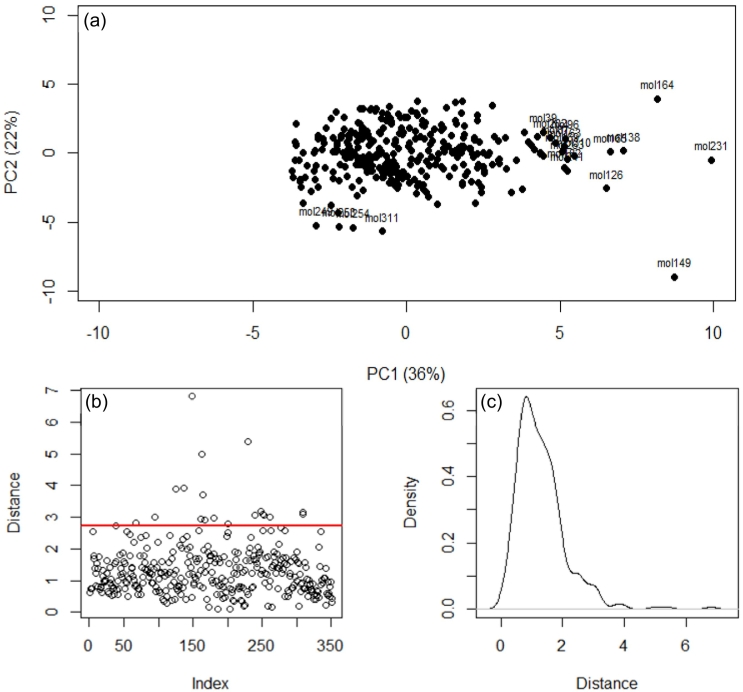
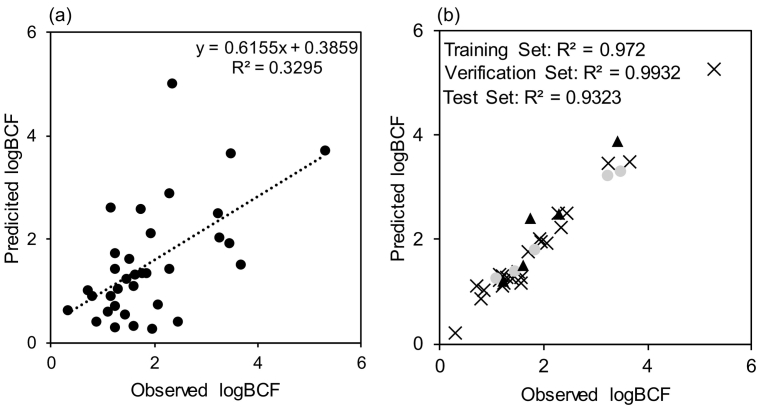
The application of machine learning has recently gained interest from ecotoxicological fields for its ability to model and predict chemical and/or biological processes, such as the prediction of bioconcentration. However, comparison of different models and the prediction of bioconcentration in invertebrates has not been previously evaluated. A comparison of 24 linear and machine learning models is presented herein for the prediction of bioconcentration in fish and important factors that influenced accumulation identified. R and root mean square error (RMSE) for the test data (n = 110 cases) ranged from 0.23-0.73 and 0.34-1.20, respectively. Model performance was critically assessed with neural networks and tree-based learners showing the best performance. An optimised 4-layer multi-layer perceptron (14 descriptors) was selected for further testing. The model was applied for cross-species prediction of bioconcentration in a freshwater invertebrate, Gammarus pulex. The model for G. pulex showed good performance with R of 0.99 and 0.93 for the verification and test data, respectively. Important molecular descriptors determined to influence bioconcentration were molecular mass (MW), octanol-water distribution coefficient (logD), topological polar surface area (TPSA) and number of nitrogen atoms (nN) among others. Modelling of hazard criteria such as PBT, showed potential to replace the need for animal testing. However, the use of machine learning models in the regulatory context has been minimal to date and is critically discussed herein. The movement away from experimental estimations of accumulation to in silico modelling would enable rapid prioritisation of contaminants that may pose a risk to environmental health and the food chain.
机器学习在生态毒理学领域中的应用引起了人们的兴趣,因为它能够对化学和/或生物过程进行建模和预测,例如生物浓缩的预测。然而,不同模型的比较和无脊椎动物生物浓缩的预测尚未得到评估。本文比较了 24 种线性和机器学习模型,用于预测鱼类中的生物浓缩以及确定影响积累的重要因素。测试数据(n=110 例)的 R 和均方根误差(RMSE)范围分别为 0.23-0.73 和 0.34-1.20。使用神经网络和基于树的学习器对模型性能进行了严格评估,结果表明它们的性能最佳。选择了经过优化的 4 层多层感知器(14 个描述符)进行进一步测试。该模型用于预测淡水无脊椎动物秀丽隐杆线虫的生物浓缩的交叉物种。该模型对 G. pulex 的表现良好,验证数据和测试数据的 R 值分别为 0.99 和 0.93。确定影响生物浓缩的重要分子描述符包括分子量(MW)、辛醇-水分配系数(logD)、拓扑极性表面积(TPSA)和氮原子数(nN)等。对 PBT 等危害标准的建模显示出替代动物测试的潜力。然而,到目前为止,机器学习模型在监管方面的应用还很少,本文对此进行了批判性讨论。从实验估计积累转向计算机建模,将能够快速确定可能对环境健康和食物链构成风险的污染物的优先级。