Department of Computer Engineering, Bilkent University, Ankara 06800, Turkey.
Computational Biology Department, School of Computer Science, Carnegie Mellon University, Pittsburgh, PA 15213, USA.
Nucleic Acids Res. 2018 Nov 30;46(21):e125. doi: 10.1093/nar/gky724.
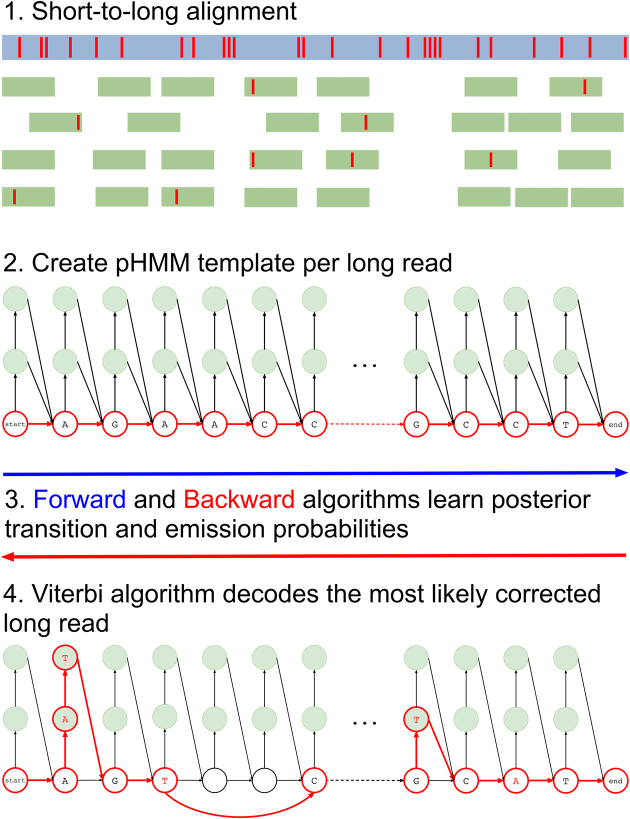
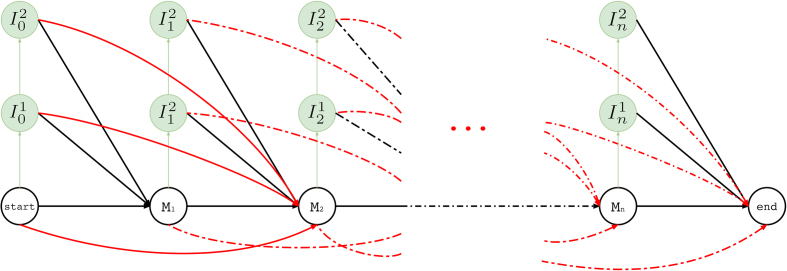
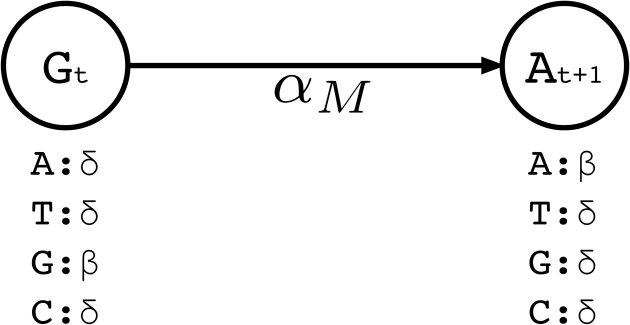
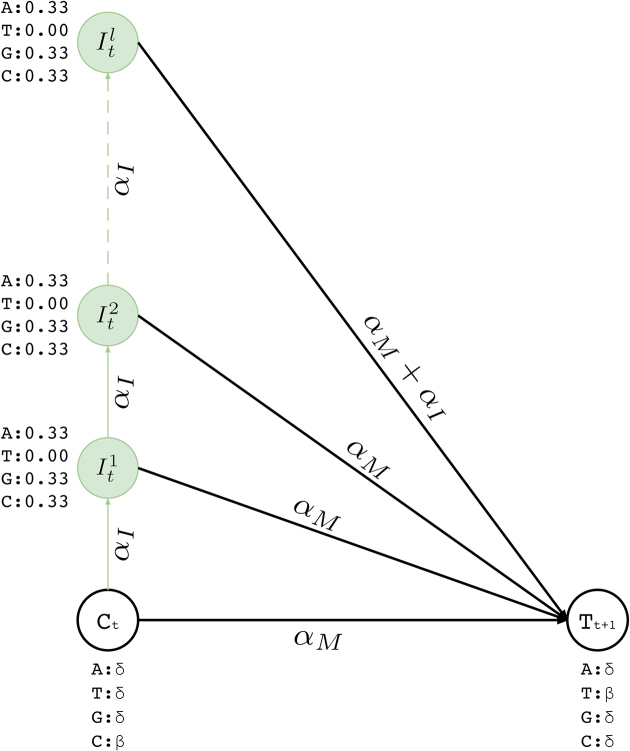
Choosing whether to use second or third generation sequencing platforms can lead to trade-offs between accuracy and read length. Several types of studies require long and accurate reads. In such cases researchers often combine both technologies and the erroneous long reads are corrected using the short reads. Current approaches rely on various graph or alignment based techniques and do not take the error profile of the underlying technology into account. Efficient machine learning algorithms that address these shortcomings have the potential to achieve more accurate integration of these two technologies. We propose Hercules, the first machine learning-based long read error correction algorithm. Hercules models every long read as a profile Hidden Markov Model with respect to the underlying platform's error profile. The algorithm learns a posterior transition/emission probability distribution for each long read to correct errors in these reads. We show on two DNA-seq BAC clones (CH17-157L1 and CH17-227A2) that Hercules-corrected reads have the highest mapping rate among all competing algorithms and have the highest accuracy when the breadth of coverage is high. On a large human CHM1 cell line WGS data set, Hercules is one of the few scalable algorithms; and among those, it achieves the highest accuracy.
选择使用第二代或第三代测序平台可能会导致准确性和读长之间的权衡。有几种类型的研究需要长而准确的读数。在这种情况下,研究人员通常会结合这两种技术,并且使用短读数来纠正错误的长读数。当前的方法依赖于各种基于图或比对的技术,并且没有考虑到基础技术的错误分布。解决这些缺点的高效机器学习算法有可能实现这两种技术的更精确整合。我们提出了 Hercules,这是第一个基于机器学习的长读错误纠正算法。Hercules 针对基础平台的错误分布,将每个长读建模为一个关于隐藏马尔可夫模型的分布。该算法为每个长读学习后验转移/发射概率分布,以纠正这些读中的错误。我们在两个 DNA-seq BAC 克隆 (CH17-157L1 和 CH17-227A2) 上表明,在所有竞争算法中,Hercules 纠正的读数具有最高的映射率,并且在覆盖率高时具有最高的准确性。在大型人类 CHM1 细胞系 WGS 数据集上,Hercules 是少数可扩展算法之一;在这些算法中,它实现了最高的准确性。