Raghu Vineet K, Ramsey Joseph D, Morris Alison, Manatakis Dimitrios V, Sprites Peter, Chrysanthis Panos K, Glymour Clark, Benos Panayiotis V
1Department of Computer Science, University of Pittsburgh, Pittsburgh, PA USA.
3Department of Philosophy, Carnegie Mellon University, Pittsburgh, PA USA.
Int J Data Sci Anal. 2018;6(1):33-45. doi: 10.1007/s41060-018-0104-3. Epub 2018 Feb 6.
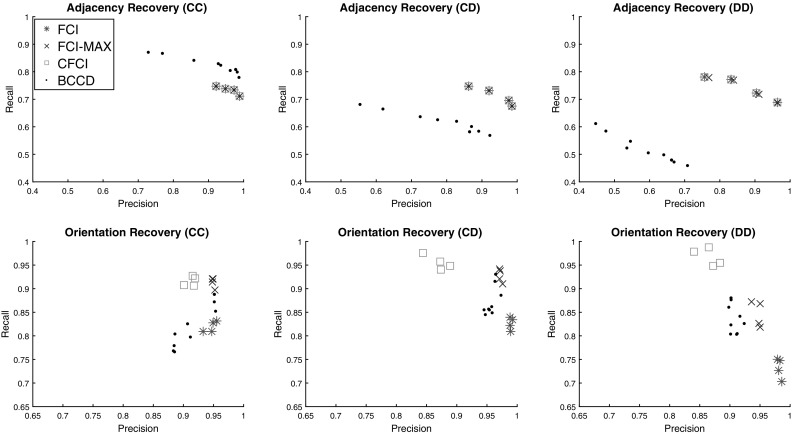
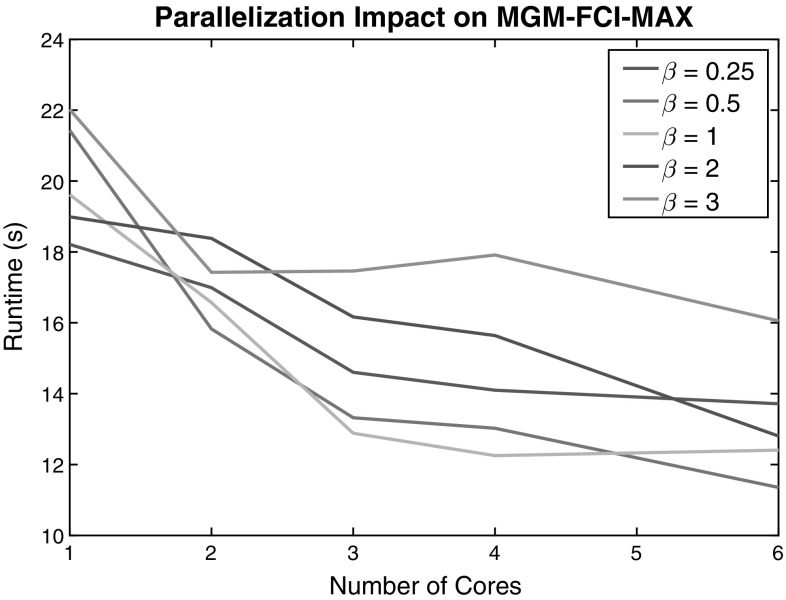
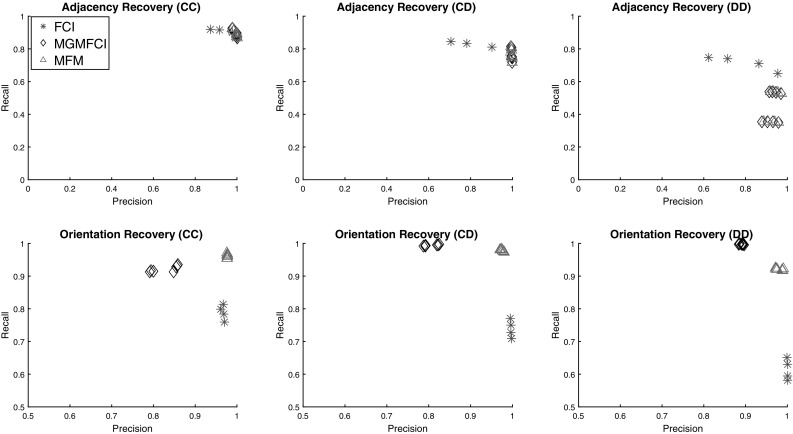
Modern technologies allow large, complex biomedical datasets to be collected from patient cohorts. These datasets are comprised of both continuous and categorical data ("Mixed Data"), and essential variables may be unobserved in this data due to the complex nature of biomedical phenomena. Causal inference algorithms can identify important relationships from biomedical data; however, handling the challenges of causal inference over mixed data with unmeasured confounders in a scalable way is still an open problem. Despite recent advances into causal discovery strategies that could potentially handle these challenges; individually, no study currently exists that comprehensively compares these approaches in this setting. In this paper, we present a comparative study that addresses this problem by comparing the accuracy and efficiency of different strategies in large, mixed datasets with latent confounders. We experiment with two extensions of the Fast Causal Inference algorithm: a maximum probability search procedure we recently developed to identify causal orientations more accurately, and a strategy which quickly eliminates unlikely adjacencies in order to achieve scalability to high-dimensional data. We demonstrate that these methods significantly outperform the state of the art in the field by achieving both accurate edge orientations and tractable running time in simulation experiments on datasets with up to 500 variables. Finally, we demonstrate the usability of the best performing approach on real data by applying it to a biomedical dataset of HIV-infected individuals.
现代技术使得从患者队列中收集大规模、复杂的生物医学数据集成为可能。这些数据集由连续数据和分类数据(“混合数据”)组成,由于生物医学现象的复杂性,关键变量在这些数据中可能未被观测到。因果推断算法可以从生物医学数据中识别重要关系;然而,以可扩展的方式处理混合数据中存在未测量混杂因素时的因果推断挑战仍然是一个未解决的问题。尽管最近在因果发现策略方面取得了进展,这些策略有可能应对这些挑战;但目前还没有一项研究全面比较在这种情况下的这些方法。在本文中,我们进行了一项比较研究,通过比较不同策略在具有潜在混杂因素的大规模混合数据集中的准确性和效率来解决这个问题。我们对快速因果推断算法的两种扩展进行了实验:一种是我们最近开发的最大概率搜索过程,用于更准确地识别因果方向,另一种是快速消除不太可能的邻接关系以实现对高维数据可扩展性的策略。我们证明,在包含多达500个变量的数据集的模拟实验中,这些方法通过实现准确的边方向和易于处理的运行时间,显著优于该领域的现有技术水平。最后,我们将性能最佳的方法应用于一组HIV感染者的生物医学数据集,证明了其在真实数据上的可用性。