Biostatistics and Bioinformatics Facility, Fox Chase Cancer Center, Philadelphia, PA, United States of America.
Department of Medical Oncology, Rutgers Cancer Institute of New Jersey, New Brunswick, New Jersey, United States of America.
PLoS One. 2018 Sep 25;13(9):e0204394. doi: 10.1371/journal.pone.0204394. eCollection 2018.
Online surveys are a valuable tool for social science research, but the perceived anonymity provided by online administration may lead to problematic behaviors from study participants. Particularly, if a study offers incentives, some participants may attempt to enroll multiple times. We propose a method to identify clusters of non-independent enrollments in a web-based study, motivated by an analysis of survey data which tests the effectiveness of an online skin-cancer risk reduction program.
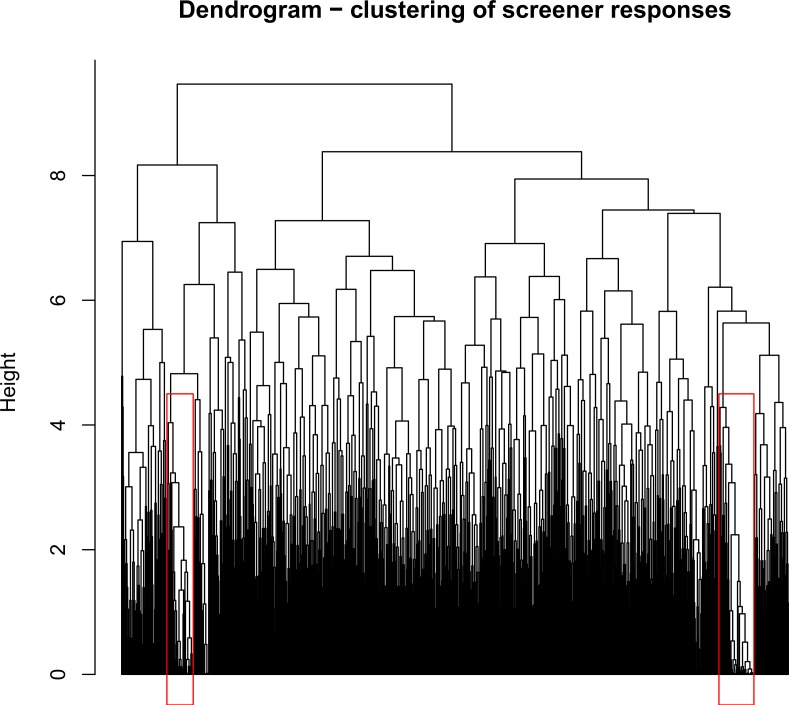
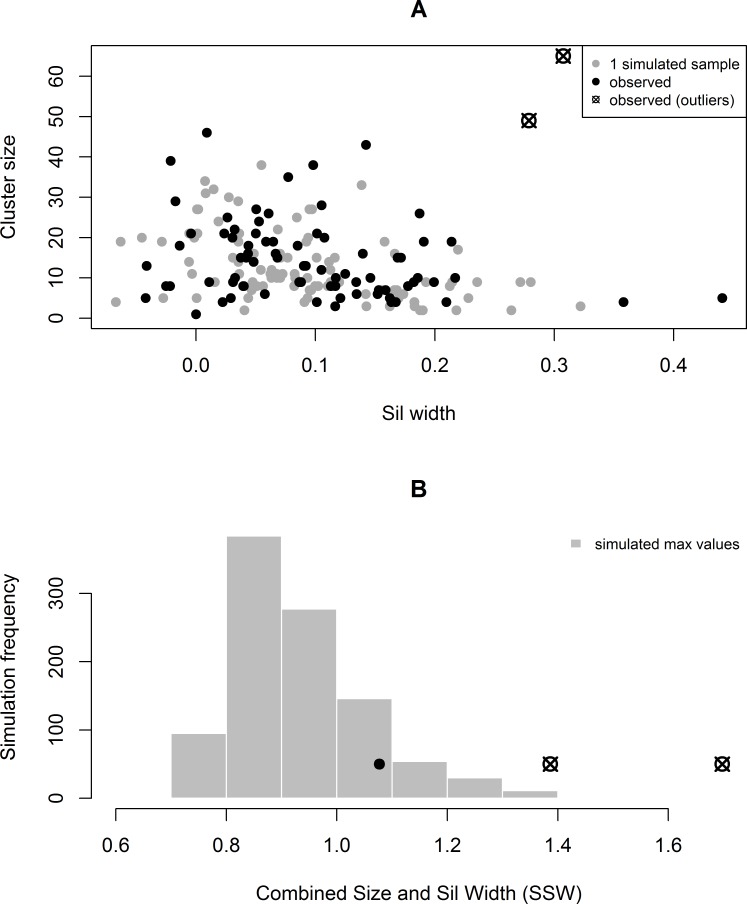
To identify groups of enrollments, we used a hierarchical clustering algorithm based on the Euclidean distance matrix formed by participant responses to a series of Likert-type eligibility questions. We then systematically identified clusters that are unusual in terms of both size and similarity, by repeatedly simulating datasets from the empirical distribution of responses under the assumption of independent enrollments. By performing the clustering algorithm on the simulated datasets, we determined the distribution of cluster size and similarity under independence, which is then used to identify groups of outliers in the observed data. Next, we assessed 12 other quality indicators, including previously proposed and study-specific measures. We summarized the quality measures by cluster membership, and compared the cluster groupings to those found when using the quality indicators with latent class modeling.
When we excluded the clustered enrollments and/or lower-quality latent classes from the analysis of study outcomes, the estimates of the intervention effect were larger. This demonstrates how including repeat or low quality participants can introduce bias into a web-based study. As much as is possible, web-based surveys should be designed to verify participant quality. Our method can be used to verify survey quality and identify problematic groups of enrollments when necessary.
在线调查是社会科学研究的一种有价值的工具,但在线管理所提供的感知匿名性可能导致研究参与者的不良行为。特别是,如果研究提供奖励,一些参与者可能会试图多次注册。我们提出了一种方法来识别基于网络的研究中不独立的注册群体,这是受分析测试在线皮肤癌风险降低计划有效性的调查数据的启发。
为了识别注册群体,我们使用了一种基于参与者对一系列李克特式资格问题的回答形成的欧几里得距离矩阵的层次聚类算法。然后,我们通过重复模拟数据集,从独立注册的假设下的响应经验分布中,系统地识别出大小和相似性都不寻常的集群。通过在模拟数据集上执行聚类算法,我们确定了独立性下的聚类大小和相似性的分布,然后将其用于识别观测数据中的异常组。接下来,我们评估了其他 12 个质量指标,包括之前提出的和特定于研究的指标。我们根据集群成员身份总结了质量指标,并将集群分组与使用质量指标和潜在类别建模找到的分组进行了比较。
当我们从研究结果的分析中排除聚类注册和/或低质量的潜在类别时,干预效果的估计值更大。这表明,包括重复或低质量的参与者会给基于网络的研究引入偏差。在可能的情况下,基于网络的调查应该设计用于验证参与者的质量。我们的方法可以用于验证调查质量,并在必要时识别有问题的注册群体。