Payne Richard D, Mallick Bani K
Texas A&M University, USA.
J Classif. 2018 Apr;35(1):29-51. doi: 10.1007/s00357-018-9248-z. Epub 2018 Mar 16.
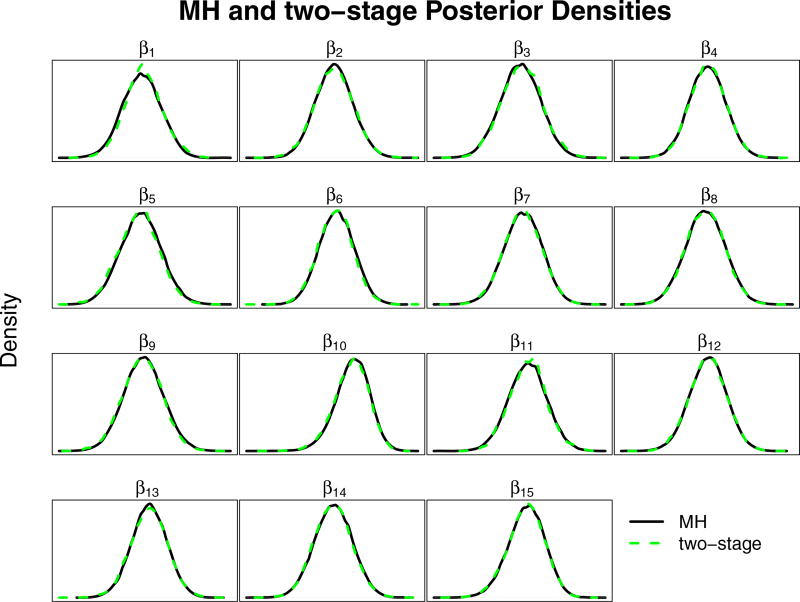
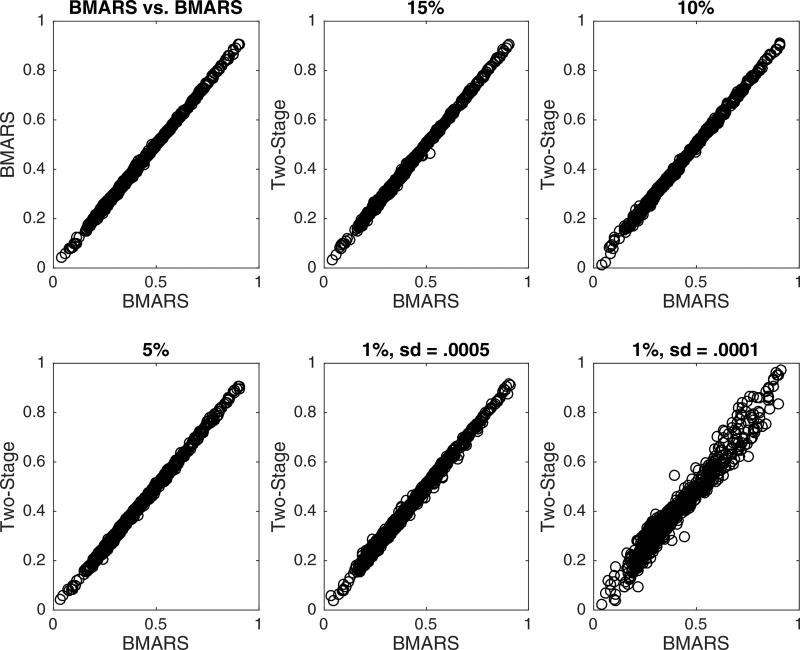
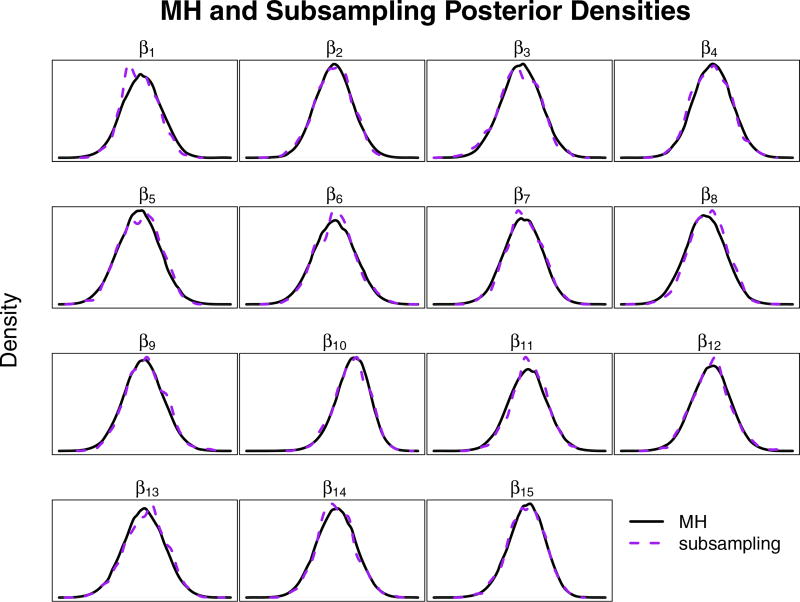
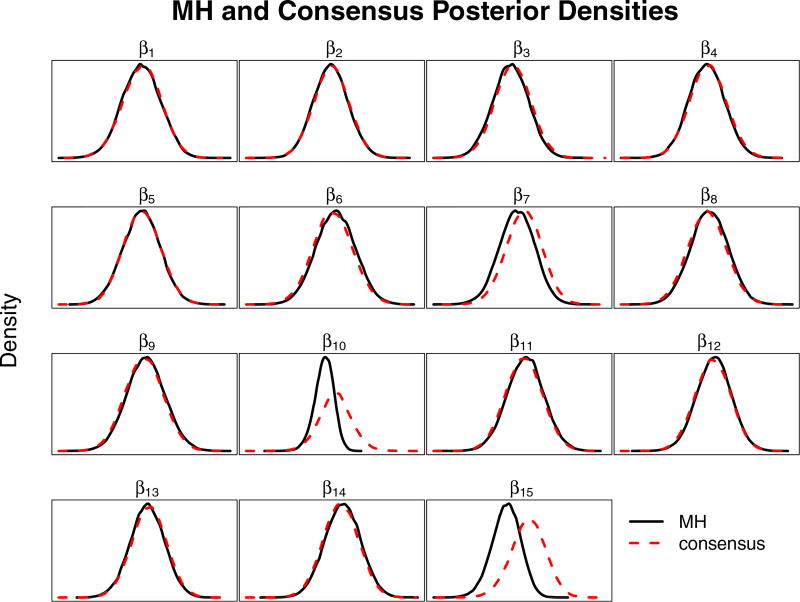
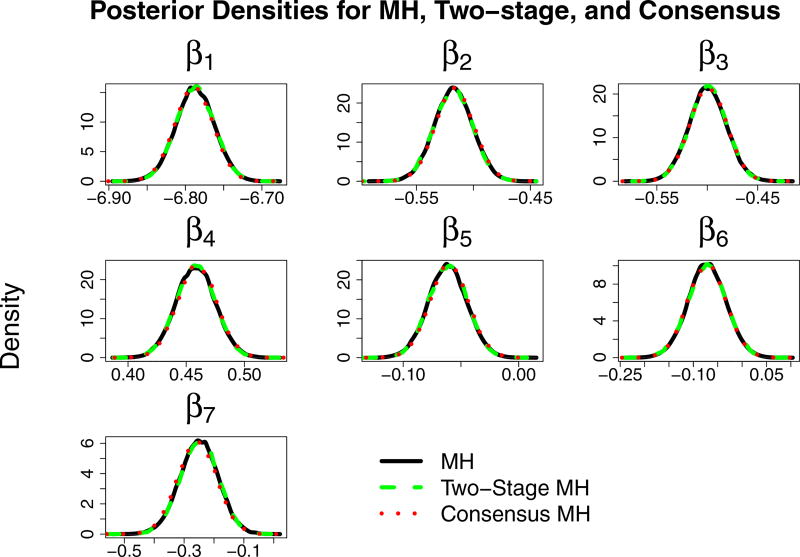
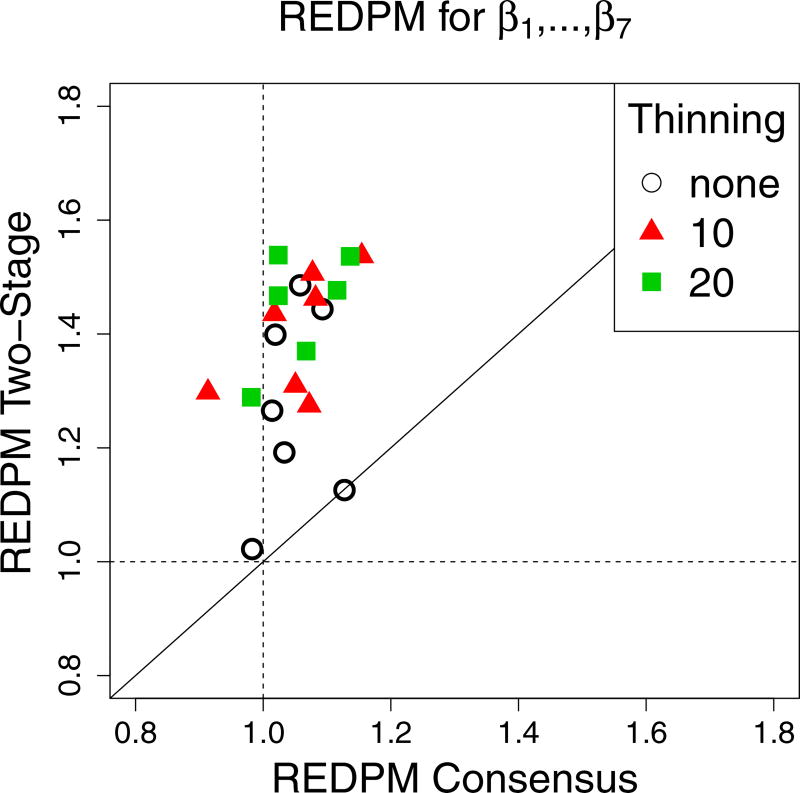
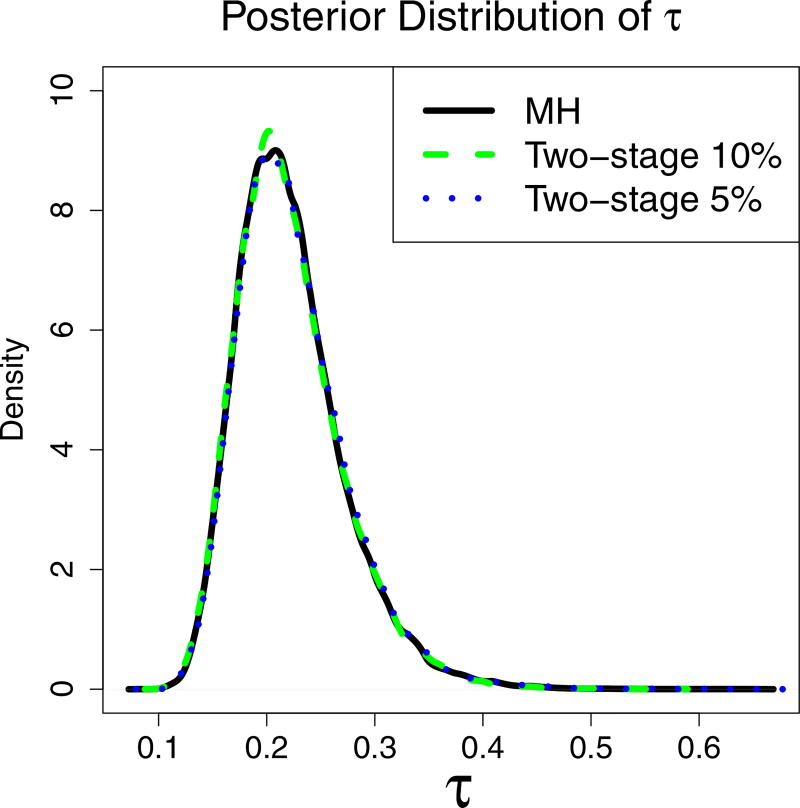
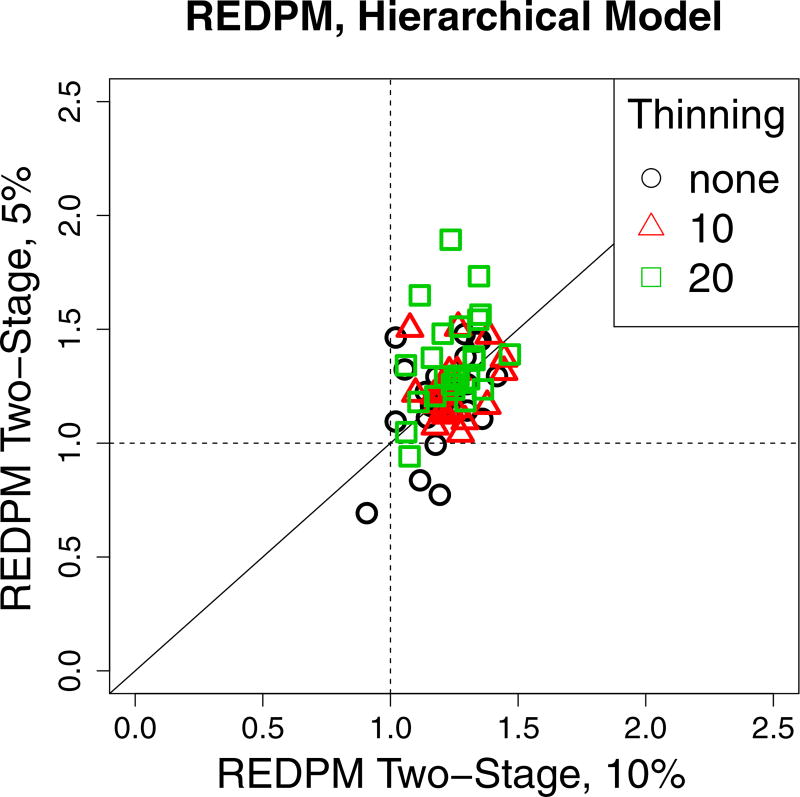
This paper discusses the challenges presented by tall data problems associated with Bayesian classification (specifically binary classification) and the existing methods to handle them. Current methods include parallelizing the likelihood, subsampling, and consensus Monte Carlo. A new method based on the two-stage Metropolis-Hastings algorithm is also proposed. The purpose of this algorithm is to reduce the exact likelihood computational cost in the tall data situation. In the first stage, a new proposal is tested by the approximate likelihood based model. The full likelihood based posterior computation will be conducted only if the proposal passes the first stage screening. Furthermore, this method can be adopted into the consensus Monte Carlo framework. The two-stage method is applied to logistic regression, hierarchical logistic regression, and Bayesian multivariate adaptive regression splines.
本文讨论了与贝叶斯分类(特别是二元分类)相关的高数据问题所带来的挑战以及处理这些问题的现有方法。当前的方法包括似然并行化、子采样和共识蒙特卡罗方法。还提出了一种基于两阶段梅特罗波利斯-黑斯廷斯算法的新方法。该算法的目的是在高数据情况下降低精确似然计算成本。在第一阶段,通过基于近似似然的模型测试新提议。只有当提议通过第一阶段筛选时,才会进行基于全似然的后验计算。此外,该方法可纳入共识蒙特卡罗框架。两阶段方法应用于逻辑回归、分层逻辑回归和贝叶斯多元自适应回归样条。