Department of Molecular Biotechnology and Health Sciences, University of Torino, Torino, Italy.
Department of Oncology, University of Torino, Candiolo, Italy.
BMC Bioinformatics. 2018 Oct 15;19(Suppl 10):349. doi: 10.1186/s12859-018-2296-x.
Reproducibility of a research is a key element in the modern science and it is mandatory for any industrial application. It represents the ability of replicating an experiment independently by the location and the operator. Therefore, a study can be considered reproducible only if all used data are available and the exploited computational analysis workflow is clearly described. However, today for reproducing a complex bioinformatics analysis, the raw data and the list of tools used in the workflow could be not enough to guarantee the reproducibility of the results obtained. Indeed, different releases of the same tools and/or of the system libraries (exploited by such tools) might lead to sneaky reproducibility issues.
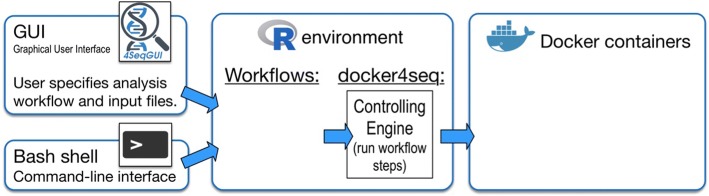
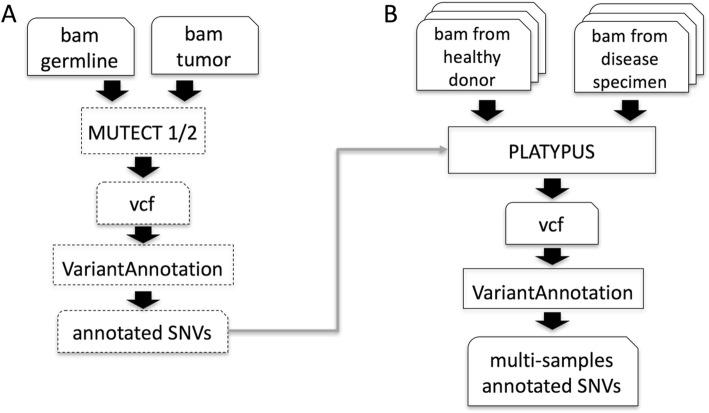
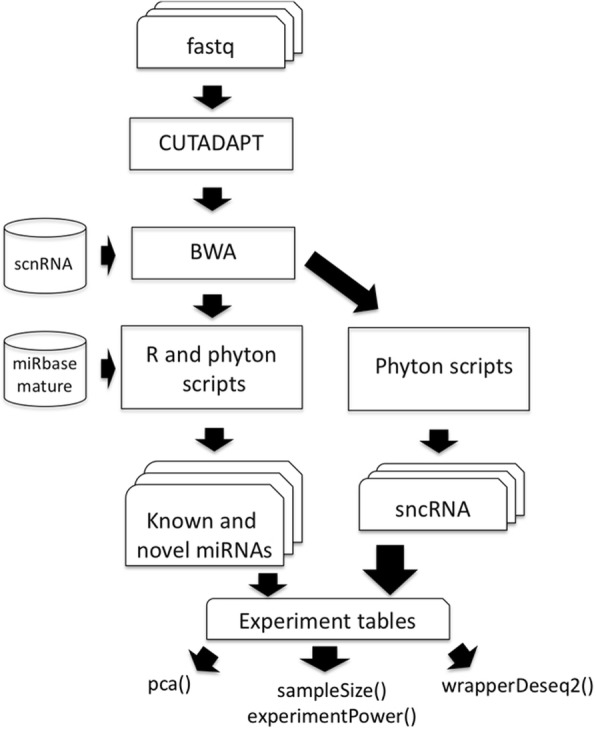
To address this challenge, we established the Reproducible Bioinformatics Project (RBP), which is a non-profit and open-source project, whose aim is to provide a schema and an infrastructure, based on docker images and R package, to provide reproducible results in Bioinformatics. One or more Docker images are then defined for a workflow (typically one for each task), while the workflow implementation is handled via R-functions embedded in a package available at github repository. Thus, a bioinformatician participating to the project has firstly to integrate her/his workflow modules into Docker image(s) exploiting an Ubuntu docker image developed ad hoc by RPB to make easier this task. Secondly, the workflow implementation must be realized in R according to an R-skeleton function made available by RPB to guarantee homogeneity and reusability among different RPB functions. Moreover she/he has to provide the R vignette explaining the package functionality together with an example dataset which can be used to improve the user confidence in the workflow utilization.
Reproducible Bioinformatics Project provides a general schema and an infrastructure to distribute robust and reproducible workflows. Thus, it guarantees to final users the ability to repeat consistently any analysis independently by the used UNIX-like architecture.
研究的可重复性是现代科学的关键要素,也是任何工业应用的必备条件。它代表了在不同地点和操作人员的情况下独立复制实验的能力。因此,只有在所有使用的数据都可用并且所利用的计算分析工作流程得到了清晰描述的情况下,研究才可以被认为是可重复的。然而,今天对于复制复杂的生物信息学分析,工作流程中使用的原始数据和工具列表可能不足以保证获得的结果的可重复性。实际上,同一工具的不同版本和/或系统库(这些工具所利用的)可能会导致难以察觉的可重复性问题。
为了解决这个挑战,我们建立了可重复生物信息学项目(RBP),这是一个非营利性的开源项目,旨在提供基于 Docker 镜像和 R 包的方案和基础设施,以提供生物信息学中的可重复结果。然后,针对工作流程定义一个或多个 Docker 镜像(通常每个任务一个),而工作流程的实现则通过嵌入在 github 存储库中的 R 函数来处理。因此,参与该项目的生物信息学家首先必须利用 RBP 专门开发的 Ubuntu docker 镜像将她/他的工作流程模块集成到 Docker 镜像中,以简化此任务。其次,工作流程的实现必须根据 RBP 提供的 R 骨架函数在 R 中实现,以保证不同 RBP 函数之间的同质性和可重用性。此外,她/他还必须提供解释包功能的 R 简介以及可以用于提高用户对工作流程使用的信心的示例数据集。
可重复生物信息学项目提供了一种通用的方案和基础设施来分发强大且可重复的工作流程。因此,它保证了最终用户能够根据所使用的 UNIX 类架构一致地重复任何分析。