Tsueng Ginger, Nanis Steven M, Fouquier Jennifer, Good Benjamin M, Su Andrew I
Department of Molecular and Experimental Medicine, The Scripps Research Institute, 10550 North Torrey Pines Road, La Jolla, CA 92037, USA.
Citiz Sci. 2016;1(2). doi: 10.5334/cstp.56. Epub 2016 Dec 31.
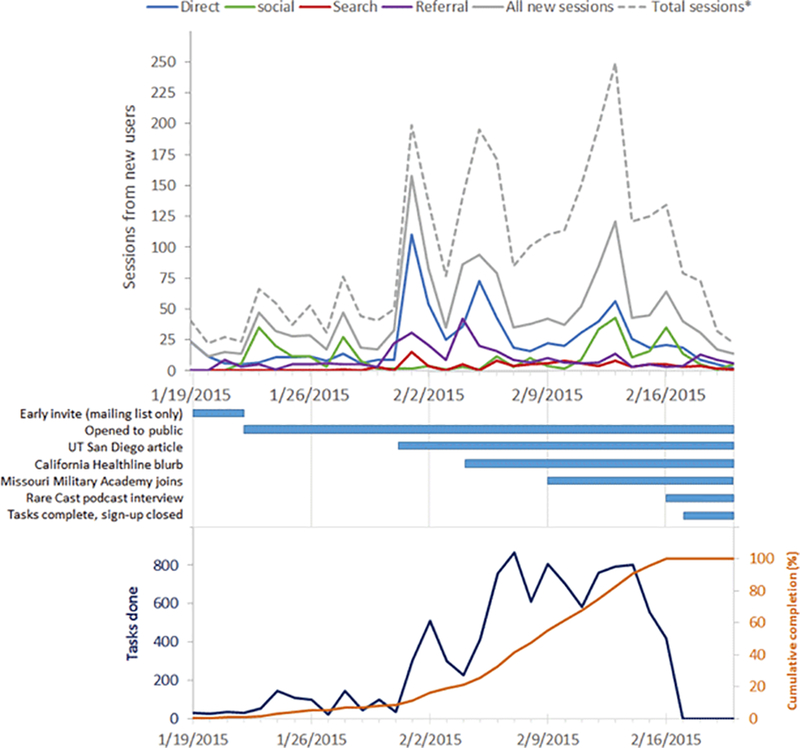
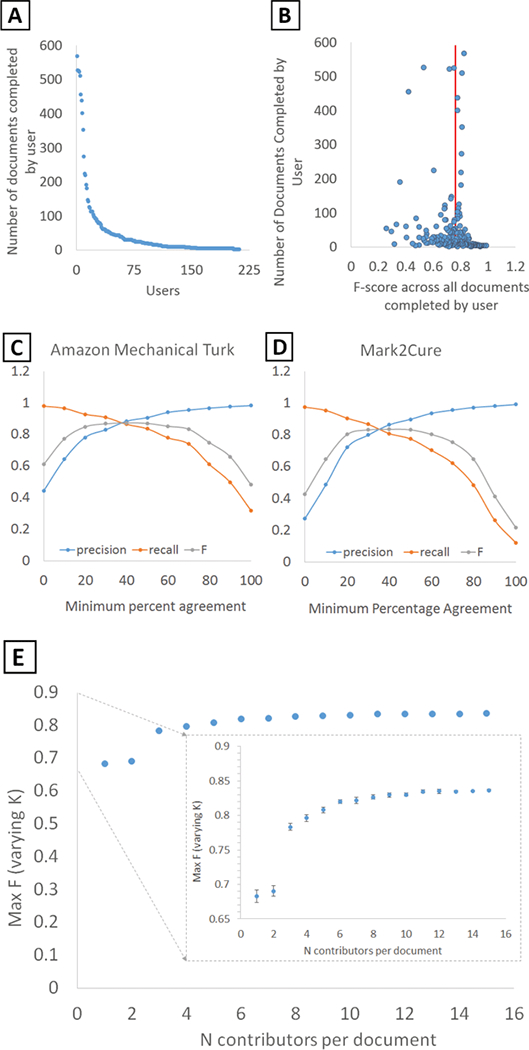
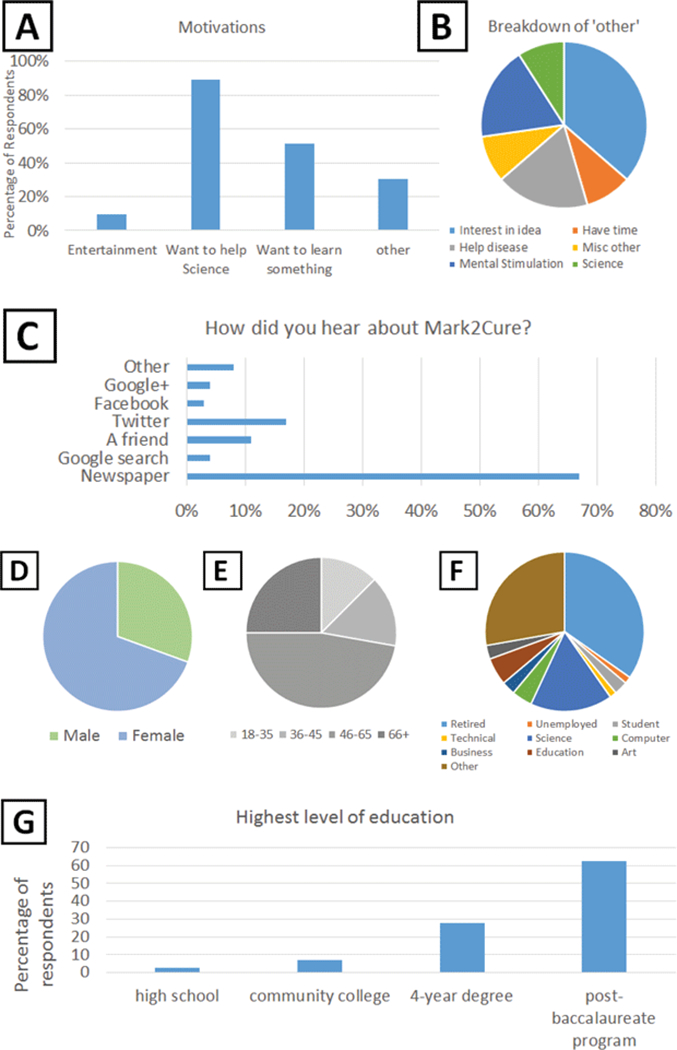
Biomedical literature represents one of the largest and fastest growing collections of unstructured biomedical knowledge. Finding critical information buried in the literature can be challenging. To extract information from free-flowing text, researchers need to: 1. identify the entities in the text (named entity recognition), 2. apply a standardized vocabulary to these entities (normalization), and 3. identify how entities in the text are related to one another (relationship extraction). Researchers have primarily approached these information extraction tasks through manual expert curation and computational methods. We have previously demonstrated that named entity recognition (NER) tasks can be crowdsourced to a group of non-experts via the paid microtask platform, Amazon Mechanical Turk (AMT), and can dramatically reduce the cost and increase the throughput of biocuration efforts. However, given the size of the biomedical literature, even information extraction via paid microtask platforms is not scalable. With our web-based application Mark2Cure (http://mark2cure.org), we demonstrate that NER tasks also can be performed by volunteer citizen scientists with high accuracy. We apply metrics from the Zooniverse Matrices of Citizen Science Success and provide the results here to serve as a basis of comparison for other citizen science projects. Further, we discuss design considerations, issues, and the application of analytics for successfully moving a crowdsourcing workflow from a paid microtask platform to a citizen science platform. To our knowledge, this study is the first application of citizen science to a natural language processing task.
生物医学文献是最大且增长最快的非结构化生物医学知识集合之一。在文献中找到隐藏的关键信息可能具有挑战性。为了从流畅的文本中提取信息,研究人员需要:1. 识别文本中的实体(命名实体识别);2. 对这些实体应用标准化词汇(归一化);3. 识别文本中的实体之间如何相互关联(关系提取)。研究人员主要通过人工专家编纂和计算方法来处理这些信息提取任务。我们之前已经证明,命名实体识别(NER)任务可以通过付费微任务平台亚马逊土耳其机器人(AMT)众包给一群非专家,并且可以显著降低成本并提高生物编目工作的通量。然而,鉴于生物医学文献的规模,即使通过付费微任务平台进行信息提取也无法扩展。通过我们基于网络的应用程序Mark2Cure(http://mark2cure.org),我们证明了NER任务也可以由志愿公民科学家高精度地执行。我们应用了来自公民科学成功的Zooniverse矩阵的指标,并在此提供结果,作为其他公民科学项目的比较基础。此外,我们讨论了设计考虑因素、问题以及分析方法的应用,以便成功地将众包工作流程从付费微任务平台转移到公民科学平台。据我们所知,这项研究是公民科学在自然语言处理任务中的首次应用。