Hasan Mohammad Nazmol, Rana Md Masud, Begum Anjuman Ara, Rahman Moizur, Mollah Md Nurul Haque
Bioinformatics Laboratory, Department of Statistics, University of Rajshahi, Rajshahi, Bangladesh.
Department of Statistics, Bangabandhu Sheikh Mujibur Rahman Agricultural University, Gazipur, Bangladesh.
Front Genet. 2018 Nov 1;9:516. doi: 10.3389/fgene.2018.00516. eCollection 2018.
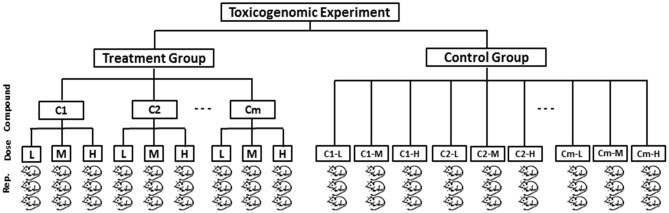
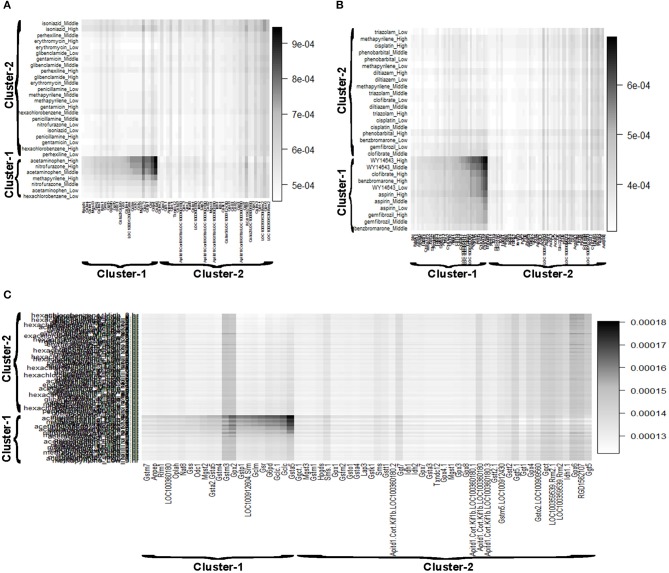
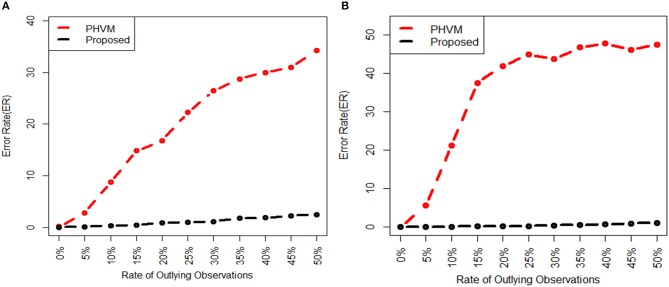
Detection of biomarker genes and their regulatory doses of chemical compounds (DCCs) is one of the most important tasks in toxicogenomic studies as well as in drug design and development. There is an online computational platform "Toxygates" to identify biomarker genes and their regulatory DCCs by co-clustering approach. Nevertheless, the algorithm of that platform based on hierarchical clustering (HC) does not share gene-DCC two-way information simultaneously during co-clustering between genes and DCCs. Also it is sensitive to outlying observations. Thus, this platform may produce misleading results in some cases. The probabilistic hidden variable model (PHVM) is a more effective co-clustering approach that share two-way information simultaneously, but it is also sensitive to outlying observations. Therefore, in this paper we have proposed logistic probabilistic hidden variable model (LPHVM) for robust co-clustering between genes and DCCs, since gene expression data are often contaminated by outlying observations. We have investigated the performance of the proposed LPHVM co-clustering approach in a comparison with the conventional PHVM and Toxygates co-clustering approaches using simulated and real life TGP gene expression datasets, respectively. Simulation results show that the proposed method improved the performance over the conventional PHVM in presence of outliers; otherwise, it keeps equal performance. In the case of real life TGP data analysis, three DCCs (glibenclamide-low, perhexilline-low, and hexachlorobenzene-medium) for glutathione metabolism pathway dataset as well as two DCCs (acetaminophen-medium and methapyrilene-low) for PPAR signaling pathway dataset were incorrectly co-clustered by the Toxygates online platform, while only one DCC (hexachlorobenzene-low) for glutathione metabolism pathway was incorrectly co-clustered by the proposed LPHVM approach. Our findings from the real data analysis are also supported by the other findings in the literature.
检测生物标志物基因及其化学化合物(DCCs)的调控剂量是毒理基因组学研究以及药物设计与开发中最重要的任务之一。有一个在线计算平台“Toxygates”,通过共聚类方法来识别生物标志物基因及其调控的DCCs。然而,该平台基于层次聚类(HC)的算法在基因与DCCs的共聚类过程中不能同时共享基因 - DCC的双向信息。而且它对异常观测值很敏感。因此,该平台在某些情况下可能会产生误导性结果。概率隐变量模型(PHVM)是一种更有效的共聚类方法,能同时共享双向信息,但它同样对异常观测值敏感。所以,在本文中,我们提出了逻辑概率隐变量模型(LPHVM)用于基因与DCCs之间的稳健共聚类,因为基因表达数据常常受到异常观测值的污染。我们分别使用模拟的和真实的TGP基因表达数据集,将所提出的LPHVM共聚类方法与传统的PHVM和Toxygates共聚类方法进行比较,研究了其性能。模拟结果表明,在存在异常值的情况下,所提出的方法比传统的PHVM性能有所提高;否则,它们的性能相当。在实际的TGP数据分析中,Toxygates在线平台将谷胱甘肽代谢途径数据集中的三个DCCs(低剂量格列本脲、低剂量哌克昔林和中剂量六氯苯)以及PPAR信号通路数据集中的两个DCCs(中剂量对乙酰氨基酚和低剂量美吡拉敏)错误地共聚类,而所提出的LPHVM方法仅将谷胱甘肽代谢途径中的一个DCC(低剂量六氯苯)错误地共聚类。我们从实际数据分析中得到的结果也得到了文献中其他研究结果的支持。