Department of Computer Science, Humboldt-Universität zu Berlin, Unter den Linden 6, Berlin, 10099, Germany.
Department of Anesthesiology and Operative Intensive Care Medicine (CCM/CVK), Charité Unviersitätsmedizin Berlin, Charitéplatz 1, Berlin, 10117, Germany.
BMC Med Inform Decis Mak. 2018 Nov 21;18(1):107. doi: 10.1186/s12911-018-0665-z.
The decreasing cost of obtaining high-quality calls of genomic variants and the increasing availability of clinically relevant data on such variants are important drivers for personalized oncology. To allow rational genome-based decisions in diagnosis and treatment, clinicians need intuitive access to up-to-date and comprehensive variant information, encompassing, for instance, prevalence in populations and diseases, functional impact at the molecular level, associations to druggable targets, or results from clinical trials. In practice, collecting such comprehensive information on genomic variants is difficult since the underlying data is dispersed over a multitude of distributed, heterogeneous, sometimes conflicting, and quickly evolving data sources. To work efficiently, clinicians require powerful Variant Information Systems (VIS) which automatically collect and aggregate available evidences from such data sources without suppressing existing uncertainty.
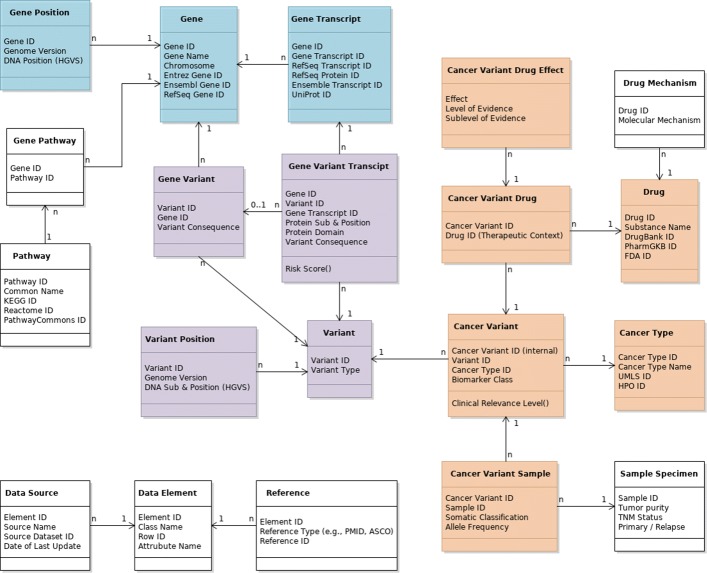
We address the most important cornerstones of modeling a VIS: We take from emerging community standards regarding the necessary breadth of variant information and procedures for their clinical assessment, long standing experience in implementing biomedical databases and information systems, our own clinical record of diagnosis and treatment of cancer patients based on molecular profiles, and extensive literature review to derive a set of design principles along which we develop a relational data model for variant level data. In addition, we characterize a number of public variant data sources, and describe a data integration pipeline to integrate their data into a VIS.
We provide a number of contributions that are fundamental to the design and implementation of a comprehensive, operational VIS. In particular, we (a) present a relational data model to accurately reflect data extracted from public databases relevant for clinical variant interpretation, (b) introduce a fault tolerant and performant integration pipeline for public variant data sources, and (c) offer recommendations regarding a number of intricate challenges encountered when integrating variant data for clincal interpretation.
The analysis of requirements for representation of variant level data in an operational data model, together with the implementation-ready relational data model presented here, and the instructional description of methods to acquire comprehensive information to fill it, are an important step towards variant information systems for genomic medicine.
获取高质量基因组变异信息的成本不断降低,以及越来越多与临床相关的变异数据的可用性,是个性化肿瘤学的重要推动因素。为了在诊断和治疗中做出合理的基于基因组的决策,临床医生需要直观地访问最新的、全面的变异信息,包括例如在人群和疾病中的流行程度、分子水平上的功能影响、与可用药靶点的关联,或临床试验结果。在实践中,由于基础数据分散在众多分布广泛、异构、有时相互冲突且快速发展的数据来源中,因此收集此类全面的基因组变异信息非常困难。为了高效工作,临床医生需要功能强大的变异信息系统(Variant Information Systems,VIS),该系统能够自动从这些数据源中收集和汇总可用证据,而不会抑制现有的不确定性。
我们解决了建模 VIS 的最重要基石:我们采用了关于变异信息的必要广度的新兴社区标准以及对其进行临床评估的程序,长期以来在实施生物医学数据库和信息系统方面的经验,我们自己基于分子谱的癌症患者诊断和治疗记录,以及广泛的文献综述,得出了一系列设计原则,我们根据这些原则开发了一个关系型数据模型,用于变异级别的数据。此外,我们还对一些公共变异数据源进行了特征描述,并描述了一个数据集成管道,用于将它们的数据集成到 VIS 中。
我们提供了一些对于全面、可操作的 VIS 的设计和实现至关重要的贡献。具体来说,我们:(a) 提出了一个关系型数据模型,以准确反映从与临床变异解释相关的公共数据库中提取的数据;(b) 引入了一个容错且高性能的公共变异数据源集成管道;(c) 提供了一些在整合用于临床解释的变异数据时遇到的复杂挑战的建议。
在操作数据模型中表示变异级数据的需求分析,以及这里提出的可实现的关系型数据模型,以及获取全面信息以填充它的方法的说明性描述,是迈向基因组医学的变异信息系统的重要一步。