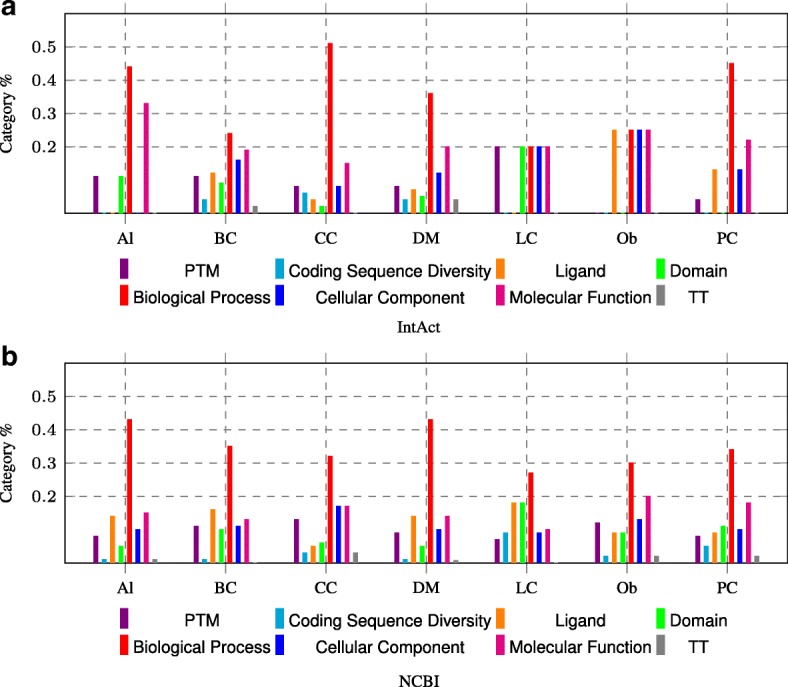
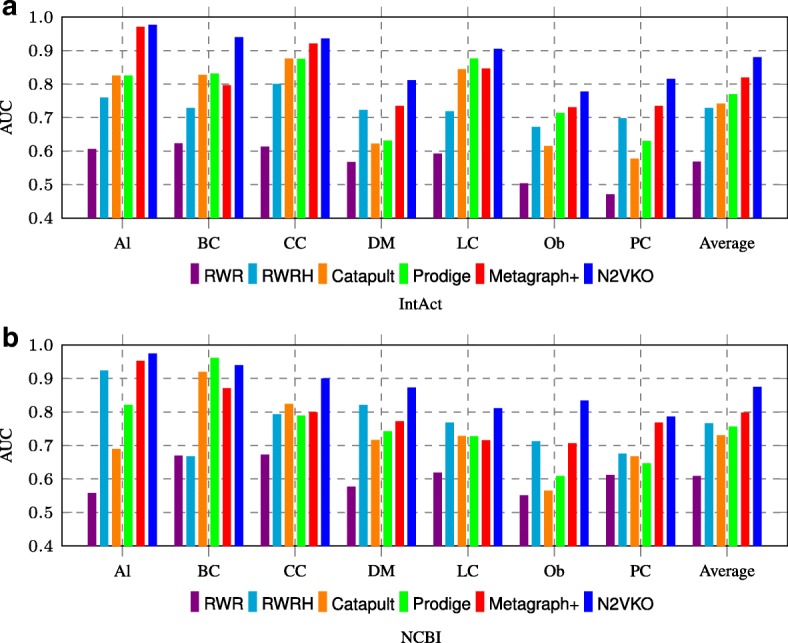
Ata Sezin Kircali, Ou-Yang Le, Fang Yuan, Kwoh Chee-Keong, Wu Min, Li Xiao-Li
Department of Computer Science and Engineering, Nanyang Technological University, Singapore, Singapore.
Department of Electronic Engineering, College of Information Engineering, Shenzhen University, China, Singapore, Singapore.
BMC Syst Biol. 2018 Dec 31;12(Suppl 9):138. doi: 10.1186/s12918-018-0662-y.
Predicting disease causative genes (or simply, disease genes) has played critical roles in understanding the genetic basis of human diseases and further providing disease treatment guidelines. While various computational methods have been proposed for disease gene prediction, with the recent increasing availability of biological information for genes, it is highly motivated to leverage these valuable data sources and extract useful information for accurately predicting disease genes.
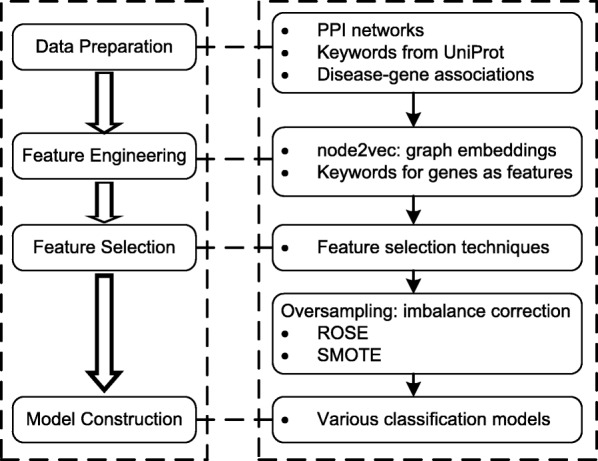
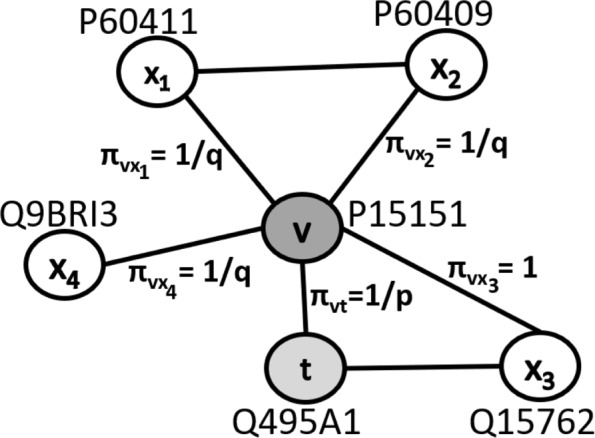
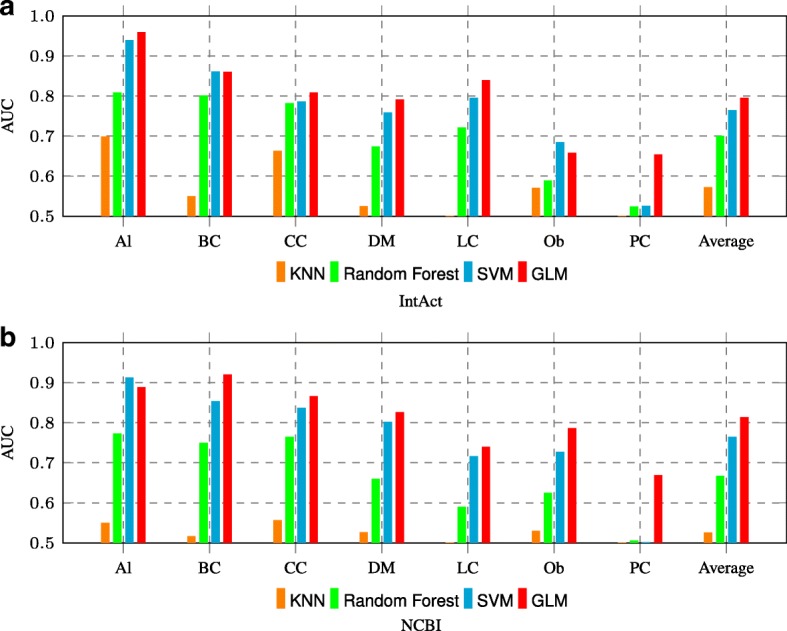
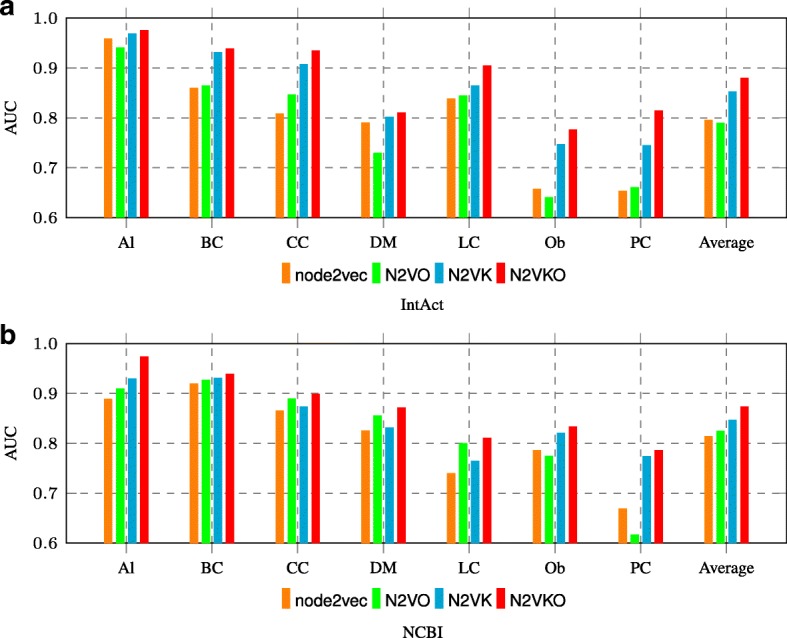
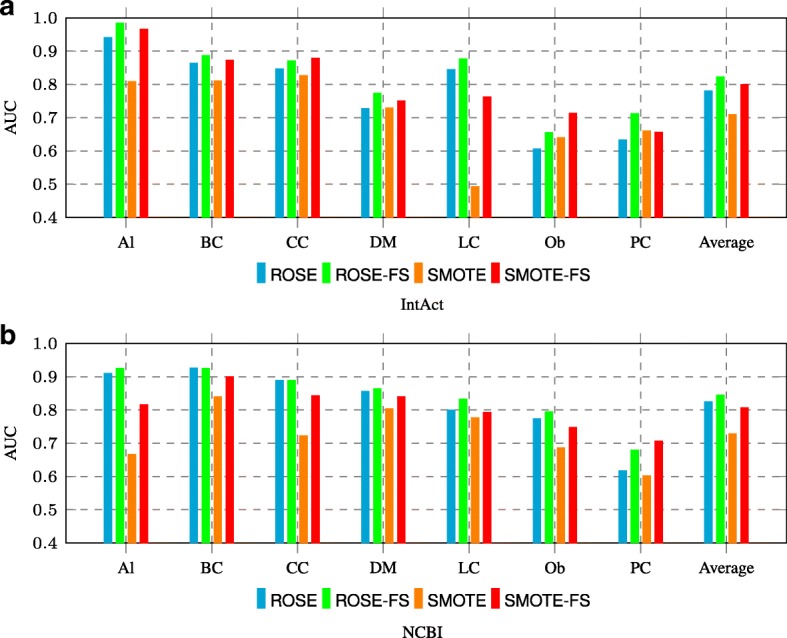
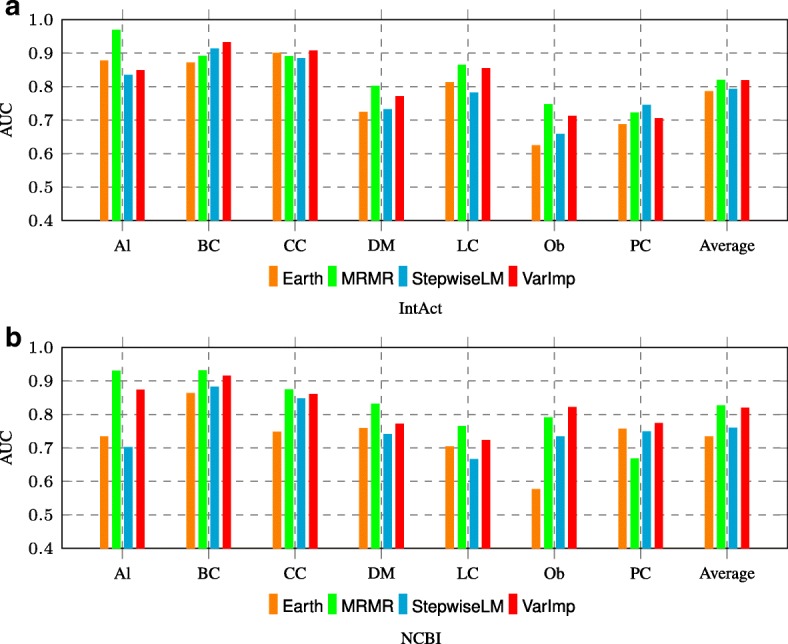
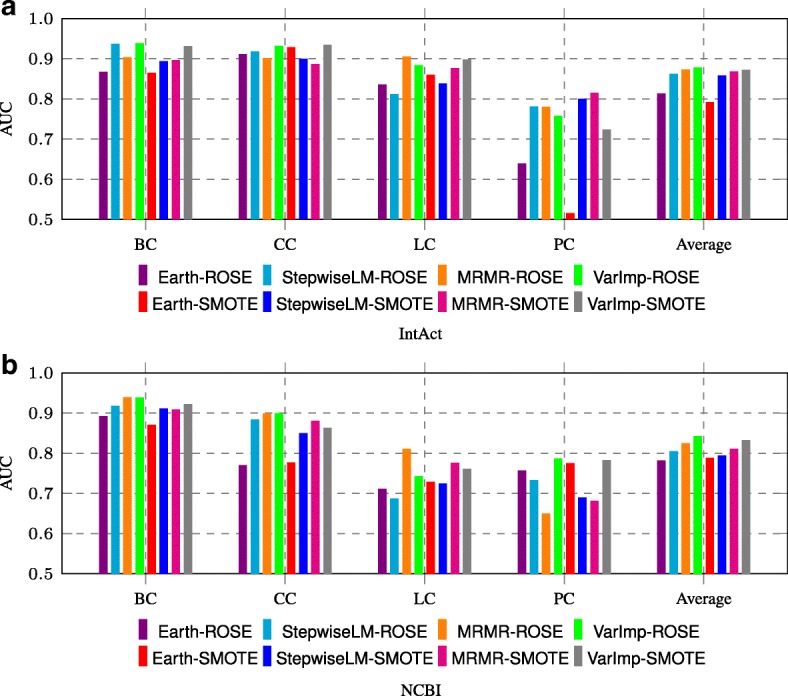
We present an integrative framework called N2VKO to predict disease genes. Firstly, we learn the node embeddings from protein-protein interaction (PPI) network for genes by adapting the well-known representation learning method node2vec. Secondly, we combine the learned node embeddings with various biological annotations as rich feature representation for genes, and subsequently build binary classification models for disease gene prediction. Finally, as the data for disease gene prediction is usually imbalanced (i.e. the number of the causative genes for a specific disease is much less than that of its non-causative genes), we further address this serious data imbalance issue by applying oversampling techniques for imbalance data correction to improve the prediction performance. Comprehensive experiments demonstrate that our proposed N2VKO significantly outperforms four state-of-the-art methods for disease gene prediction across seven diseases.
In this study, we show that node embeddings learned from PPI networks work well for disease gene prediction, while integrating node embeddings with other biological annotations further improves the performance of classification models. Moreover, oversampling techniques for imbalance correction further enhances the prediction performance. In addition, the literature search of predicted disease genes also shows the effectiveness of our proposed N2VKO framework for disease gene prediction.
预测疾病致病基因(或简称为疾病基因)在理解人类疾病的遗传基础以及进一步提供疾病治疗指南方面发挥了关键作用。虽然已经提出了各种用于疾病基因预测的计算方法,但随着最近基因生物学信息的可用性不断增加,利用这些有价值的数据源并提取有用信息以准确预测疾病基因具有很强的动机。
我们提出了一个名为N2VKO的综合框架来预测疾病基因。首先,我们通过采用著名的表示学习方法node2vec从基因的蛋白质 - 蛋白质相互作用(PPI)网络中学习节点嵌入。其次,我们将学习到的节点嵌入与各种生物学注释相结合,作为基因丰富的特征表示,随后构建用于疾病基因预测的二元分类模型。最后,由于疾病基因预测的数据通常是不平衡的(即特定疾病的致病基因数量远少于其非致病基因数量),我们通过应用过采样技术来校正不平衡数据,以进一步解决这个严重的数据不平衡问题,从而提高预测性能。综合实验表明,我们提出的N2VKO在七种疾病的疾病基因预测方面显著优于四种最先进的方法。
在本研究中,我们表明从PPI网络中学习到的节点嵌入在疾病基因预测中效果良好,而将节点嵌入与其他生物学注释相结合进一步提高了分类模型的性能。此外,用于不平衡校正的过采样技术进一步增强了预测性能。此外,对预测疾病基因的文献检索也表明了我们提出的N2VKO框架在疾病基因预测方面的有效性。