Department of Biostatistics, Harvard T.H. Chan School of Public Health, Boston, MA, USA.
University Bordeaux, ISPED, Inserm Bordeaux Population Health Research Center, UMR 1219, Inria SISTM, Bordeaux F-33000, France.
Sci Data. 2019 Jan 8;6:180298. doi: 10.1038/sdata.2018.298.
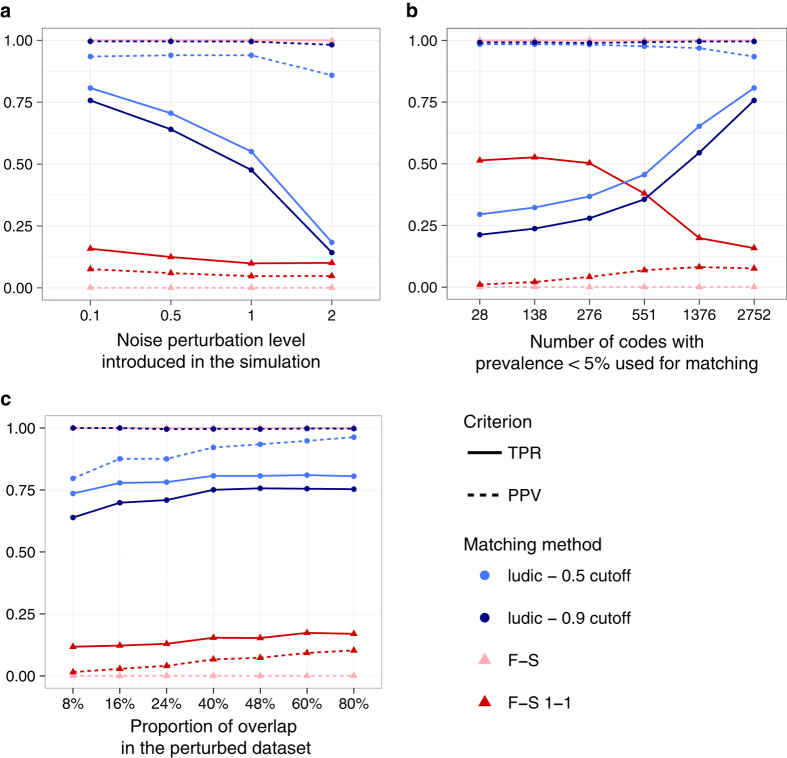
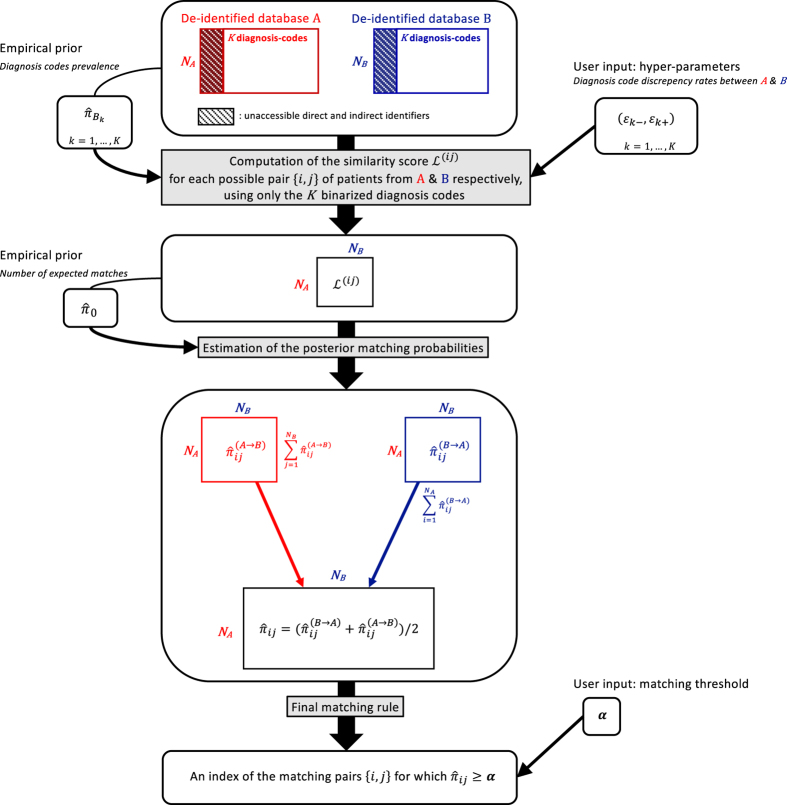
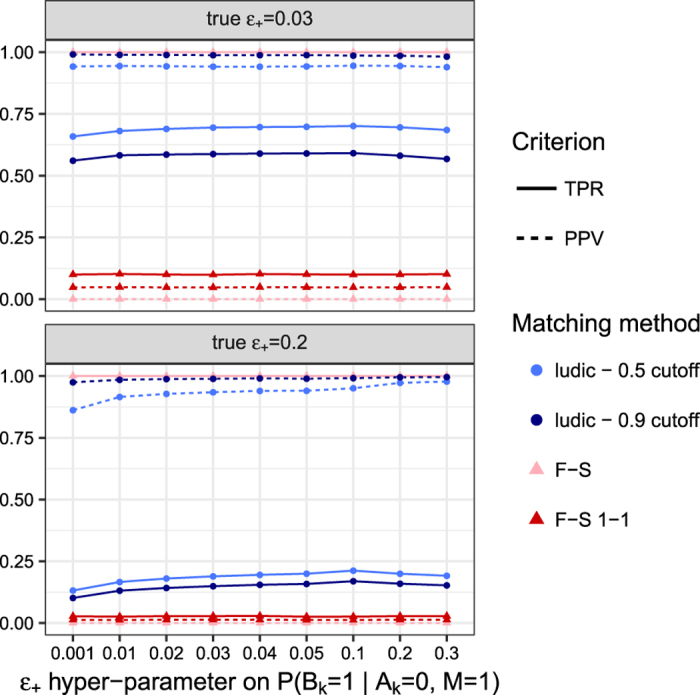
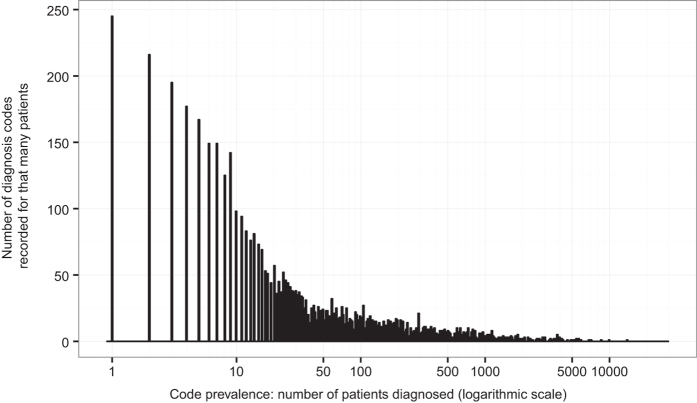
We develop an algorithm for probabilistic linkage of de-identified research datasets at the patient level, when only diagnosis codes with discrepancies and no personal health identifiers such as name or date of birth are available. It relies on Bayesian modelling of binarized diagnosis codes, and provides a posterior probability of matching for each patient pair, while considering all the data at once. Both in our simulation study (using an administrative claims dataset for data generation) and in two real use-cases linking patient electronic health records from a large tertiary care network, our method exhibits good performance and compares favourably to the standard baseline Fellegi-Sunter algorithm. We propose a scalable, fast and efficient open-source implementation in the ludic R package available on CRAN, which also includes the anonymized diagnosis code data from our real use-case. This work suggests it is possible to link de-identified research databases stripped of any personal health identifiers using only diagnosis codes, provided sufficient information is shared between the data sources.
我们开发了一种在患者水平上对去识别研究数据集进行概率链接的算法,当只有有差异的诊断代码且没有个人健康标识符(如姓名或出生日期)可用时。它依赖于二进制诊断代码的贝叶斯建模,并为每个患者对提供匹配的后验概率,同时考虑到所有数据。无论是在我们的模拟研究(使用行政索赔数据集进行数据生成)还是在两个真实用例中,将大型三级保健网络的患者电子健康记录进行链接,我们的方法都表现出良好的性能,并优于标准的 Fellegi-Sunter 基线算法。我们在 ludic R 包中提出了一种可扩展、快速且高效的开源实现,该包可在 CRAN 上获得,其中还包括我们实际用例中的匿名诊断代码数据。这项工作表明,只要在数据源之间共享足够的信息,就有可能仅使用诊断代码来链接去识别研究数据库,而无需任何个人健康标识符。