Department of Cardiology, Erasmus MC, Rotterdam, The Netherlands.
Department of Biostatistics, Erasmus MC, Rotterdam, The Netherlands.
Stat Med. 2019 May 30;38(12):2269-2281. doi: 10.1002/sim.8113. Epub 2019 Jan 31.
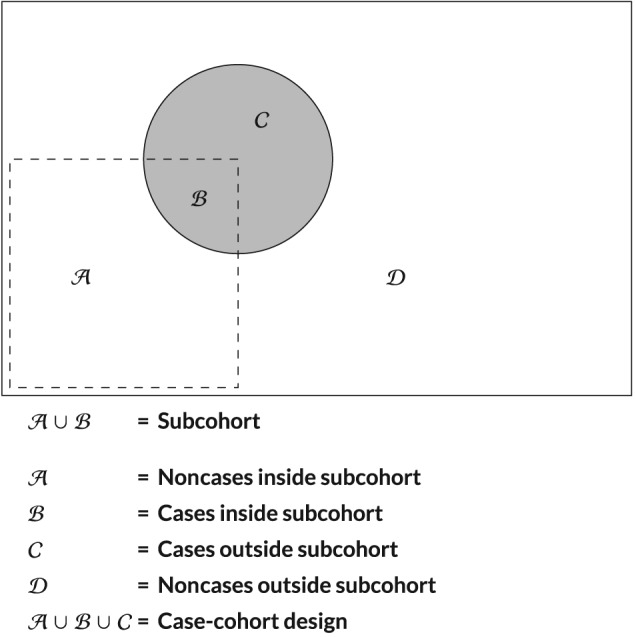
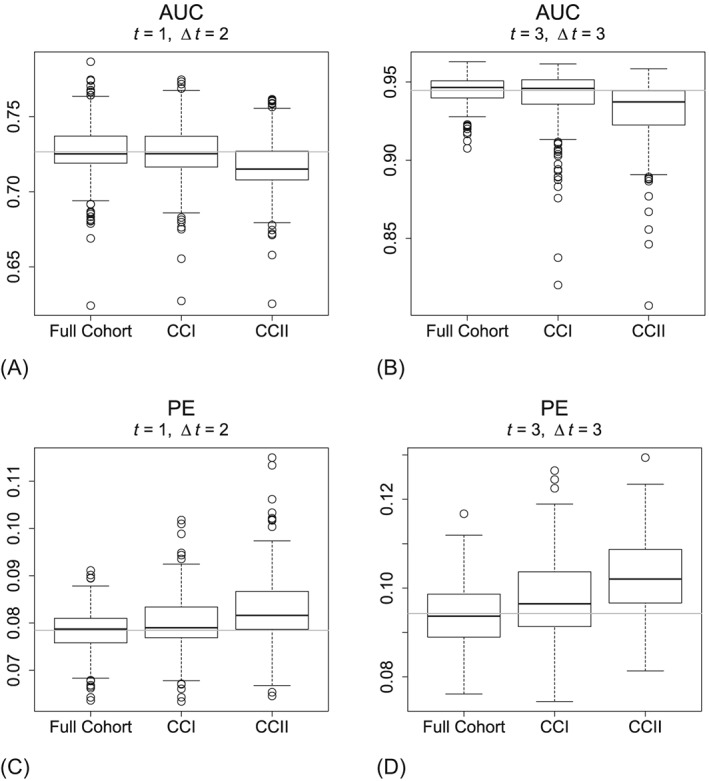
Studies with longitudinal measurements are common in clinical research. Particular interest lies in studies where the repeated measurements are used to predict a time-to-event outcome, such as mortality, in a dynamic manner. If event rates in a study are low, however, and most information is to be expected from the patients experiencing the study endpoint, it may be more cost efficient to only use a subset of the data. One way of achieving this is by applying a case-cohort design, which selects all cases and only a random samples of the noncases. In the standard way of analyzing data in a case-cohort design, the noncases who were not selected are completely excluded from analysis; however, the overrepresentation of the cases will lead to bias. We propose to include survival information of all patients from the cohort in the analysis. We approach the fact that we do not have longitudinal information for a subset of the patients as a missing data problem and argue that the missingness mechanism is missing at random. Hence, results obtained from an appropriate model, such as a joint model, should remain valid. Simulations indicate that our method performs similar to fitting the model on a full cohort, both in terms of parameters estimates and predictions of survival probabilities. Estimating the model on the classical version of the case-cohort design shows clear bias and worse performance of the predictions. The procedure is further illustrated in data from a biomarker study on acute coronary syndrome patients, BIOMArCS.
在临床研究中,具有纵向测量的研究很常见。特别感兴趣的是那些使用重复测量来动态预测事件发生时间结果(如死亡率)的研究。然而,如果研究中的事件发生率较低,并且大多数信息都来自经历研究终点的患者,那么仅使用数据的子集可能更具成本效益。一种实现此目的的方法是应用病例-队列设计,该设计选择所有病例和仅随机样本的非病例。在病例-队列设计中分析数据的标准方法中,未被选择的非病例完全被排除在分析之外;然而,病例的过度代表会导致偏差。我们建议在分析中包括队列中所有患者的生存信息。我们将无法获得部分患者的纵向信息视为缺失数据问题,并认为缺失机制是随机缺失的。因此,从适当的模型(例如联合模型)获得的结果应该仍然有效。模拟表明,我们的方法在参数估计和生存概率预测方面都与在全队列上拟合模型的效果相似。在病例-队列设计的经典版本上拟合模型会显示出明显的偏差和预测性能下降。该过程进一步在急性冠状动脉综合征患者生物标志物研究 BIOMArCS 的数据中进行了说明。